







前言
今天是Vision-Life项目组的第三个小项目,做的是一个简单的车牌识别。
车牌识别算是一个比较经典的项目了,网上也有很多资料,没什么创意,做的目的呢是因为它恰好涵盖了我之前一段时间所学的知识,权当是对前面知识的总结复习吧🍔🍟🍿
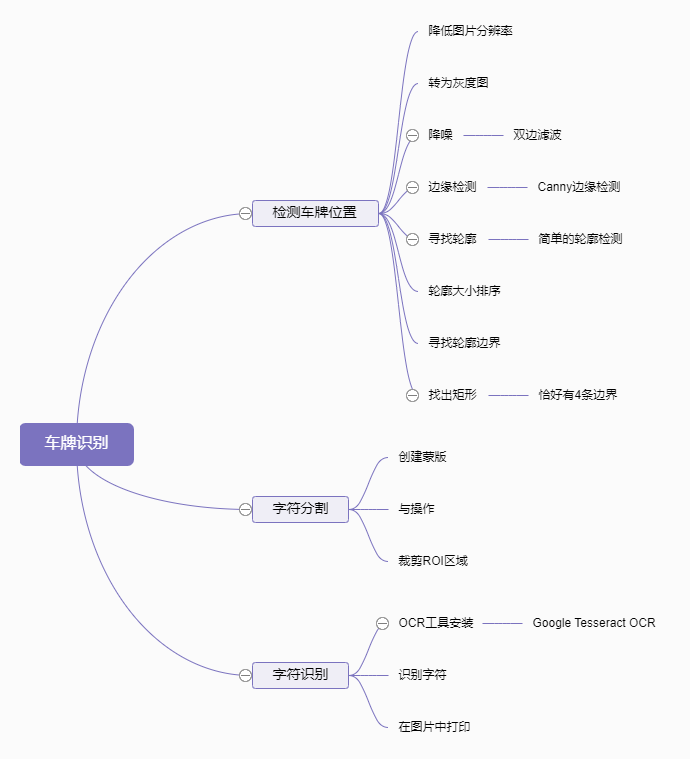
知识体系
架构
效果图
对指定图片可以达到检测的目的

检测车牌位置
图像预处理
图像预处理包括:降分辨率、灰度、降噪与Canny边缘检测
img = cv2.imread('carcard.jpg')
img = cv2.resize(img,(640,420),interpolation=cv2.INTER_LANCZOS4)
gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 双边滤波模糊
gray_img = cv2.bilateralFilter(gray_img,3,45,45)
gray_img = cv2.Canny(gray_img,20,300)
首先我们选一张图片,它初始的时候是这样子的
大小为1080x540,RGB格式

由于不同图像的分辨率不同,所以我们要统一大小。同时要保证,我们感兴趣的区域(ROI,这里是车牌),必须保留在框架中
img = cv2.resize(img,(640,420),interpolation=cv2.INTER_LANCZOS4)
这里我使用640*420的分辨率,相较之前缩小了一半

因为在处理图像的时候我们不需要关注颜色细节,所以灰度图能减少图像的颜色通道,方便后期处理
gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)

灰度变换之后,由于车的背景(如两座山,围栏)对识别有影响,所以我们应对图片进行滤波,突出主题,为后面的Canny检测作铺垫
gray_img = cv2.bilateralFilter(gray_img,3,45,45)
注意事项
这里为什么用双边滤波呢?我们知道,双边滤波在模糊的同时,还能突出边缘。这大大改善Canny检测的效果
开始的时候我曾用过中值滤波,发现边缘也被模糊了。于是Canny检测后的图像的矩形轮廓有断点,计算机无法找到车牌的位置
上图是对灰度图模糊的对比,也许你看不出有什么区别
但如果我Canny检测之后呢?
我们放大车牌部分,发现中值模糊下的断点更多,而双边模糊的断点更少;从而左边的车牌构不成一个完整的轮廓,而右边的可以构成一个完整的轮廓,从而被计算机找到


寻找车牌轮廓
# opencv2返回两个值:contours、hierarchy。opencv3返回三个值:img(图像)、countours(轮廓)、hierarchy(层次结构)
contours = cv2.findContours(gray_img,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
# imutils.grab_contours的作用,返回cnts中的countors(轮廓),不区分opencv2或opencv3
contours = imutils.grab_contours(contours)
# 想要过滤掉那些微小琐碎的轮廓,只显示这幅图中面积大的轮廓。代码思路是将findContours查找到的轮廓按照面积排序
contours = sorted(contours,key=cv2.contourArea, reverse = True)[0:10]
screenCnt = None
for c in contours:
area = cv2.contourArea(c)
print(area)
epsilon = 0.02*cv2.arcLength(c,True)
# approxPolyDP()返回值顶点的坐标
approx = cv2.approxPolyDP(c,epsilon,True)
if len(approx) == 4:
screenCnt = approx
print(len(screenCnt))
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 1)
break
cv2.findContours()寻找到轮廓- 由于Opencv2和3函数返回值不同,所以我们
imutils.grab_contours()统一返回的数据格式 sorted()将各个轮廓按面积大小由高到低排序,[0:10]是指排到第十名就不排了- 轮询各个轮廓
- 用
cv2.approxPolyDP()得到各个轮廓顶点坐标(坐标的个数不限,反正按顺序连接这些顶点能大概绘制出轮廓的样子就行) - 因为车牌是矩形,所以我们车牌轮廓一定有4个顶点(理想状态下…)
cv2.drawContours()绘制车牌区域
经过这一系列操作后,我们的图像将会变成这样

这样,车牌部分就被找出来了😎😎😎
字符分割
蒙版操作
现在我们知道车牌在哪里了,剩下的信息对我们来说几乎没用。因此,我们可以对没用的部分进行遮挡(涂黑)
# 创建蒙版
img_mask = np.zeros(gray_img.shape,np.uint8)
new_img = cv2.drawContours(img_mask,[screenCnt],0,255,-1)
cv2.imshow('new_img',new_img)
# 与操作
img=cv2.bitwise_and(img,img,mask=new_img)
被遮挡的图像如下

于是,我们可以根据蒙版的数值(黑=0,白=255),裁剪图像
蒙版图👇👇👇

裁剪操作
(x,y)=np.where(img_mask==255)
topx=np.max(x)
topy=np.max(y)
bottomx=np.min(x)
bottomy=np.min(y)
Cropped = np.zeros(gray_img.shape,np.uint8)
Cropped = cv2.rectangle(Cropped,(topy,topx),(bottomy,bottomx),255,1)
Cropped=img[bottomx:topx,bottomy:topy]
np.where(img_mask==255)找蒙版为白色像素,np.max(y)找返回的y数组里最大的那个值Cropped = cv2.rectangle(Cropped,(topy,topx),(bottomy,bottomx),255,1)这里要注意坐标格式为==(y,x)==Cropped=img[bottomx:topx,bottomy:topy]直接操作元组切割图像,注意bottomx:topx,bottomy:topy,topx-bottomx>0
裁剪后的图像如下

最后放大一下裁剪的图像,方便OCR识别
Cropped = cv2.resize(Cropped,(400,200),interpolation=cv2.INTER_LANCZOS4)
字符识别
OCR(Optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转换为机器编码文本的技术。通过数字方式存储文本数据更容易保存和编辑,可以存储大量数据,比如1G的硬盘可以存储数百万本书。
OCR工具安装
参考链接:Python OCR工具pytesseract详解
这里我装的路径为:pytesseract.pytesseract.tesseract_cmd=r’D:\GoogleOCR\tesseract.exe’
将路径复制到代码上
import cv2
import numpy as np
import imutils
import pytesseract
pytesseract.pytesseract.tesseract_cmd=r'D:\GoogleOCR\tesseract.exe'
数字识别
# 识别字符
text = pytesseract.image_to_string(Cropped,config='--psm 11')
print("Detected license plate number is:",text)
print(text[0:7])
打印一下
Detected license plate number is: CZ20FSE.
成功🤔🤤🤤🤤
再看一次效果
结语
代码已经扔进仓库里了,需要的自取:Vision-Life3 车牌检测
接下来如果有时间的话,将会用Opencv4+Unity3D做点好玩的东西,应该会非常有创意🤔🤔🤔

















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











