









what
翻译或问答系统中,输入和输出是不定长的序列,传统的卷积神经网络,无法直接处理
数据格式
我是中国人 -》 I am Chinese
nlp中一般对数据会预先进行分词处理,如我是中国人,可以分成:我 是 中国 人,输出英文就是三个单词了,这里很明显,输入序列长度是4,输出序列长度是3。在送入模型之前,我们先要将数据进行编码,一般是one hot格式,首先对中文及英语都会有一个词典(ocr中也是这样)
我是中国人,可以编码如下:
我【0000001000】
是【0000010000】
中国【0010000000】
人【0100000000】
同理输出也是这样,这样我们就有了一个样本对【X(X1,X2,X3,X4),Y(Y1,Y2,Y3)】
损失函数
这里介绍的损失函数,并不是常规意义上的损失函数,看起来像一个总的目的,模型参数为theta,最大似然求该样本集出现的概率

条件概率
知道了最大似然损失函数,如何求得最终结果呢,下面使用贝叶斯条件概率公式进行了推导,求得P(Y | X)的条件概率

seq2seq模型介绍
总体结构如下,还是以翻译为例,记住一点,无论输入输出,都是以one-hot格式的数据,如“机器学习”,这里没有分词,直接翻译的,无论是否分词,都有一个输入的字典,假设字典长度为M,那么这里的输入总维度就是MT,T是输入序列长度,这里是4个,因为无论编码模块、解码模块都是用RNN、LSTM等,因此输入也是一个不定长(时间维度)的序列
同理,输出也是这种格式,假设输出字典长度为N,总的输出就是NT,这里输出T为2
embeding 有些情况下,输入字典太大,会进行embeding压缩成词向量之后,再送入网络,本质就是在one-hot基础上重新编码一下
下图中,h4到C,是进行了进一步的信息压缩,可能就是一个全连接,C包含了整个输入句子中的信息

LSTM介绍
LSTM其实也简单,把这个图背下来就行了,比RNN无非多了三个门(sigmoid)一个Ct
pytorch中,rnn或lstm的数据数据,无论n-step有几个,即下面的单元结构,定义一个层就可以了,因为rnn或lstm层输入数据的格式包含了batch,n-step、feature(vector)Length几个信息,一起输进去了,里面的递进计算,都是pytorch封装的layer自己做的,之所以这样原理是rnn或lstm无论多少个step,其实他们用的是一套参数,计算的时候也是按时序顺序计算的

自己总结语言:lstm主要是解决rnn长期依赖的问题,rnn的结构很简单,就是每个神经元的输入包含两部分,输入信号xt,以及上一层神经元的输出ht-1,通过这种简单的连接,尤其是多级联以后,容易造成梯度消失,近处的神经元信号可以穿过来,远处的信号可能衰减的厉害,因此梯度消失就造成的rnn的短期依赖强,长期依赖弱的问题。lstm又叫长短期依赖,就是解决这个问题
它的主要思路是上面有一个高速通道一样的隐层ct,ct这个通道的信息,可以从第一个神经元畅通至最后一个神经元
另外,还有三个门函数,分别是遗忘门、输入门和输出门
遗忘门通过xt经过sigmoid激活函数后,与ct相乘
输入门是xt信号经过sigmoid后,与ht-1相乘,去和ct相加
输出门是xt信号经过sigmoid后,与ct-1相乘,产生ht
通过这样复杂的结构后,每个step有两个输出,ct高速通道,有效防止梯度下降,解决长期依赖,以及ht,神经元的输出,综合了xt,以及ct的信息
attention
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射。
其计算方式是先计算Query和各个Key的相似性或者相关性(这里用点乘),得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数
target序列中的某个元素query
Source序列是一系列<key,value>数据对
attention在seq2seq中的一般应用
解码过程与传统encoder-decoder模型相同,只不过context vector c变为了Ci,每个Ci都是经过了对ht(输入信号的编码信息)经过了加权求和

公式如下,显然这里的q是Sj,来自解码器的信息,即target和source不同(和self-attention的本质区别),k和v都是hi?
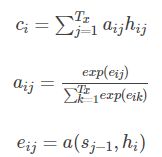
self-attention
self attention会给你一个矩阵,告诉你 entity1 和entity2、entity3 ….的关联程度、entity2和entity1、entity3…的关联程度。
它指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Q=K=V。

图中x的nstep=2?,每个step的输入是1乘4,输出是1乘3
self-attention公式

transformer结构中使用了多头attention机制,所谓多头就是并行有n个attention,然后再concat到一起。一点小不同是,transformer中的attention再计算softmax之前,加了掩码,目的是在nlp任务中,不让后面的词对当前词产生影响。

transformer的具体情况,以后另起一文详细总结
通俗易懂的介绍
VIT(Visual Transformer)
将transformer思想应用于图像,首先要将图片的数据或特征转换为(N, seq_len, emb_size)的格式,这里采用列分块的方法,把图像分成列196块,组成时序维度,目的是将图像各位置的特征进行关联。

上图的Embedded Patches就是分块,将原始的(3, 224,224)图片特征转换为(1, 196, 768),就是(N, seq_len, emb_size)。原始图片分成196块,每块的宽高大小是224/14=16,所以每块的特征数就是16×16×3=768。















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









