




TL;DR
在 MCPHub 上用 浏览器即可运行 的工作流 llm-search → AntV → 导出,把一个研究型 Prompt 直接变成「可视化图表 + 迷你报告」。零本地配置、零复制粘贴。
立即试用: https://chat.mcphub.com
工作流的亮点
-
浏览器运行:无需本地安装与环境配置。
-
多语种权威来源:llm-search 支持 英文+中文主流媒体评测,并可开启 crawl 拉取文章正文,抽取结构化数据。
-
自动归一化:把不同媒体的打分与表述统一到 0–100 量表。
-
冲突消解:按 时效性(最新优先)+ 来源可信度 自动合并,剔除离群值。
-
一键可视化:AntV 生成 雷达图(若某指标数据稀疏自动回退为柱状图)。
-
可溯源:输出 图表 URL、Top 5 来源链接,附 方法与局限 简述,确保透明与可复现。
-
一键导出:成品报告支持 Markdown,图表可下载 PNG。
传统「研究 → 画图」往往来回切工具、手动搬运数据。借助 MCP 服务器,模型能自动编排整条链路:
搜索 → 归一化 → 可视化 → 文字叙述 → 导出。流程可复用、易分享,也方便沉淀为团队模板。
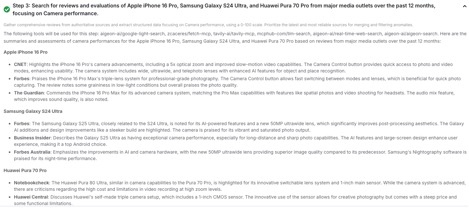
工作流具体运行流程
-
Search & Structure(检索与结构化):
llm-search返回规范化的数据行(例如vendor、mentions、date、source),并可抓取正文做字段抽取。 -
Visualize(可视化):
AntV MCP将数据行转为图表 -
Report(报告生成):MCPHub 汇总要点、添加引用并内嵌图表,可一键导出 Markdown
Demo
在 浏览器 中运行以下工作流,把一个对比评测 Prompt 转换为 0–100 归一化数据 + 雷达图/柱状图 + 报告。







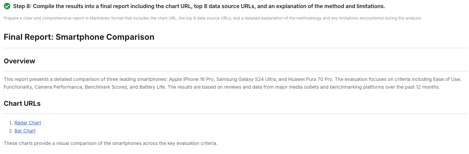
在线报告示例:https://mcp.edgeone.site/share/7G8ZzVlQyTDrXR00HPYLT
加入 Discord 社区
有问题、想提新工具、或想展示你的工作流?欢迎加入官方 Discord,一起讨论与共建:
-
社区与开发者的直接帮助
-
反馈建议,参与塑造 MCPHub 的未来
-
看看大家在做什么,获取灵感
-
第一时间获知新功能与新工具支持
加入讨论: https://discord.gg/eV3ZpQ3x
立刻上手
前往 mcphub.com,选择可用服务器,然后按需使用 Inspector 或 Online Client:
-
Inspector:纯工具测试——适合逐步校验并截取输出/截图
-
Online Client:在对话中直接调用工具,由模型生成最终报告
技术细节
-
Servers:
llm-search(搜索/归一化)、antvis(图表) -
Client: MCPHub(浏览器 UI)
-
Outputs: 图表图片、图表 spec、以及干净的 MD/PDF 报告


















 6764
6764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









