







上一篇文章,介绍了一下Raft共识算法的一些概念,包括领导选举、日志复制、日志压缩、安全特性等。在学习了Raft之后,本人也花了半个月的时间完成MIT6.824课程的Lab2(建议看一下课程视频,Robert Morris教授的笑容真的太亲切了~),并在本地通过了五百次的测试。目前正在进行六千次的测试中,已完成4500次。这篇文章将按照MIT6.824中的路线,聚焦Lab2的A、B部分,讲一下使用Go实现Raft的领导选举与日志复制中的细节以及Lab相关的注意事项。
强烈建议不要到网上看别人现成的代码,独立思考,收获会非常大。本篇文章主要是以分享思路为主,只会贴一些核心逻辑/代码。往期文章:
下文中会出现两个日志的概念,一个为我们代码中实际打印出来的日志,另一个为Raft中需要进行复制的日志。为了区别,我会将后者用LogEntry进行强调。当没有出现LogEntry这一单词时,日志一词的意思指前者。此外,为了简洁起见,本文出现的代码均删去了打印日志的相关代码。
前言
总体而言,Lab2A的难度并不是很大。个人在开始上手Lab2A之前,看了课程的Lecture5。同时,不熟悉Golang的同学可以先做一下Lab1,做完会对Go有一个初步的认识。切记不要急于开始写代码,否则很可能会遇到很多坑,花费很多时间。
相对于Lab2A的代码实现,其实前置知识的学习所花费的时间更多,其中Raft的学习与理解更是重中之重。对Raft的介绍可以看上一篇文章,当然,能看论文的话最好看一遍原论文。这一节首先介绍一下写实验前需要知道的各种工具、文章。
- Raft Extend Paper 首先,自然是Raft论文本身了。如果觉得上来就啃论文啃不动的话,可以先看看这个Raft可视化网站。
- Lab Guidance课程组的实验指导页面,包括了一些Go语言的测试命令、Raft实现中结构体的设计、锁的设计、计时器设计的建议。
- Raft Locking Advice与Raft Structure Advice:(来自上一条中的Lab Guidance中的链接)课程组在代码设计上的建议,有效规避了很多可能会出现死锁的情况以及计时器的设计建议,会在后面的章节中展开。
- Students’ Guide to Raft:这个是助教在16年写的一篇关于学生们在实现Raft的过程中经常会遇到的问题以及相应的解决方案,里面还包含了一些常见的case study的FAQ。不过这两篇文章要不要在开始写代码前读我保持中立,因为这篇文章写得很全面,基本上把大部分Lab2会遇到的坑都提到了,留给个人思考的空间会比较小。我个人比较头铁😂,直到写完Lab2的所有代码后才回过头来看了这两篇文章查漏补缺,确实自己遇到的大坑里面基本上都有讲。虽然在这些坑上花了不少时间,但独立思考着实带来了不小的锻炼,所以,看个人选择吧。
- Debugging by Pretty Printing:这是助教写的如何让日志更加规范的文章,在开始写代码前一定要读!!!我们知道,分布式系统的debug是个体力活。由于多线程的特殊性,我们的debug只能通过日志的输出来完成,这也导致debug花费的时间往往成倍于写代码的时间。就以Lab2为例,写完Lab2的所有四个部分,代码其实不过一千多行,但debug的时间却花费了十天左右。从堆积如山的日志中调bug是一件非常头疼的事情,在写Lab1时深有感触。而这篇文章中提供的日志美化脚本则大大缩短了我们debug的时间:助教贴心地建议我们将不同的Log分为不同的类型,并通过Python的Rich库将日志在终端中以不同的颜色打印出来,起到事半功倍的效果。一图胜千言,贴一张对比图感受一下:
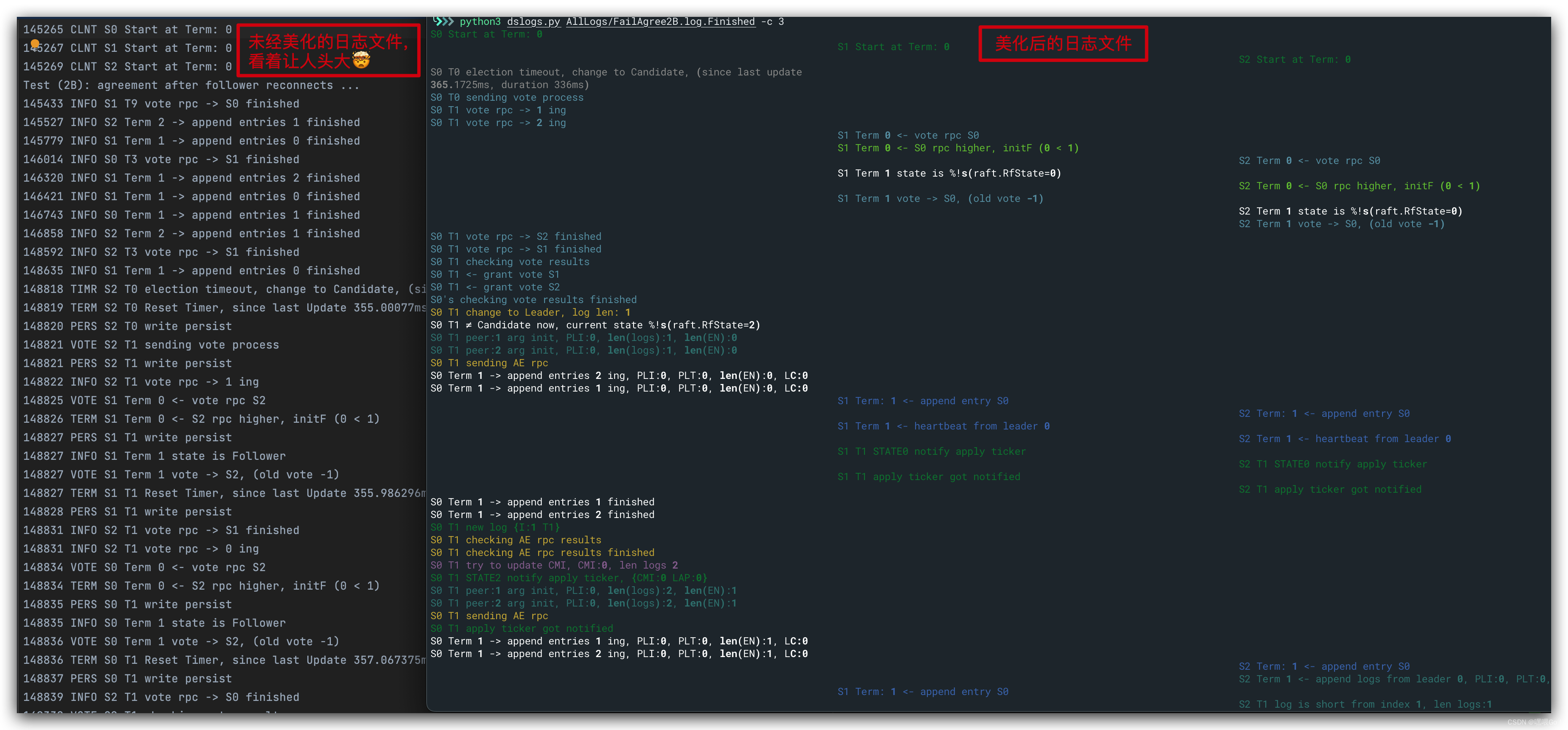
除了美化日志,助教还为我们提供了一个批量测试的Python文件,方便我们能够反复执行测试以找出潜在的bug:
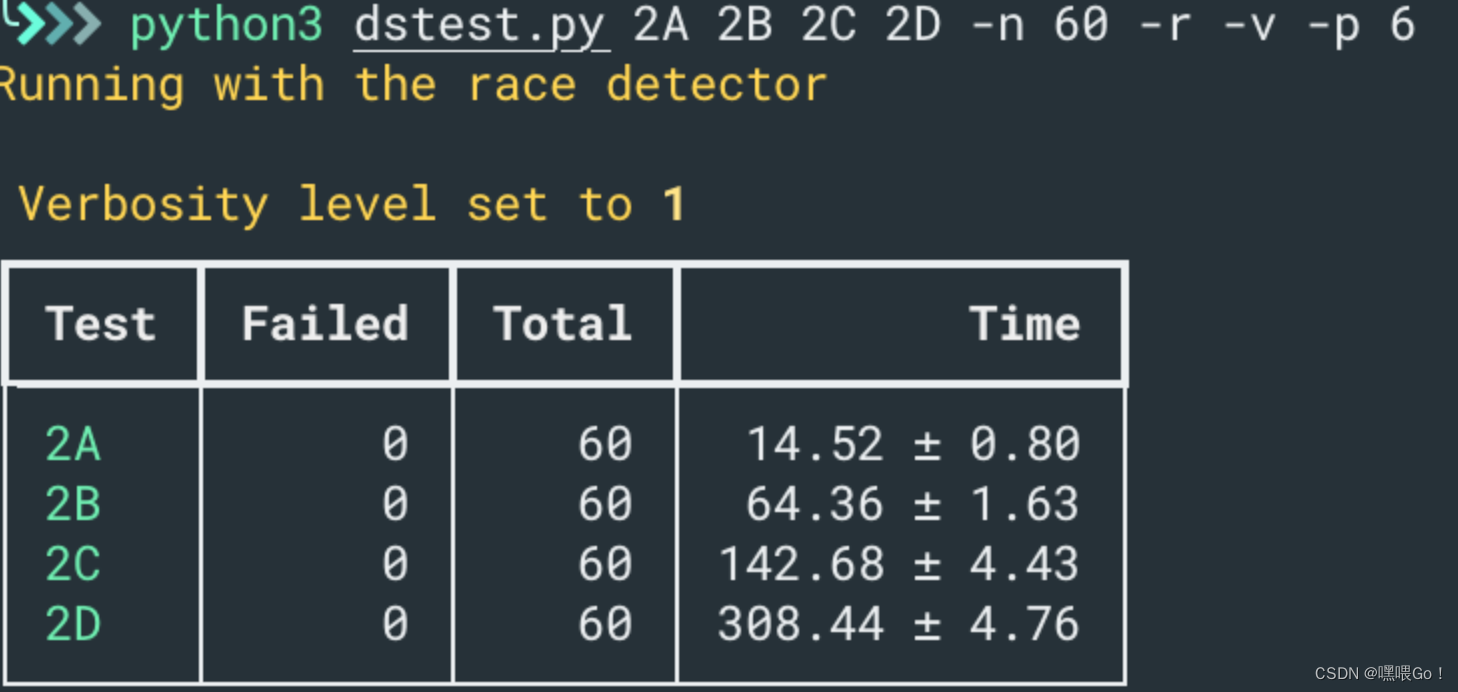
总之,助教写的这两个脚本非常有用,我是写完Lab2A以后才开始用的,相见恨晚😂。
- diagram of Raft interactions: 最后是课程组提供的一个关于Lab2、Lab3的结构图,便于我们理解需要实现的函数的具体作用。我们知道,Lab2是实现Raft算法,但Raft终归是需要为上层的State Machine服务的,以便响应Client的请求。Lab3就是要求我们在Raft的基础上实现一个key/value层,并能响应客户端的各种请求。需要注意的是23年的课程中去掉了
CondInstallSnap(sm_state)这一个接口(22年其实就已经“名存实亡”了),具体地我们放到Lab2D中讲。
最后,我想讲一下自己在debug中的Tips。从Lab2B开始,每当我的代码有一定的改动,我都会重新运行百次左右的之前已通过的测试,以保证对代码的修改不影响已实现的功能。Go语言的测试中,-run参数会匹配并运行所有包含该参数的测试。例如,go test -run 2A就会运行所有测试函数中包含了2A关键字的测试。因此,当我通过了某一个测试后(一般连续通过上百次后我会暂时认为这一测试是“通过”的),我都会在测试函数后面加上CheckPoint关键字。后面需要重新运行这些测试时,直接go test -run CheckPoint就好。
此外,当测试代码很长、生成了大量日志时(最多的时候见到过几十万行的😅),我会尝试缩小日志的规模:复制这一测试并改名,修改里面的一些变量。例如减少循环次数、减少server的个数、去掉随机数等等。很多时候日志文件的大部分内容都是正常运行的输出,我们需要的内容往往只是一小部分。通过这样的方法有效减少日志规模的同时,也能复现Bug,屡试不爽。
领导选举
Lab2A是Lab2四个实验中唯一一个标注了moderate的lab,其余的均为Hard。实际做下来,lab2A写代码+debug花了两天半的时间。
需要了解
Lab2A主要要求我们实现的是领导选举以及领导产生后发送心跳的机制。虽然不难,但可以说Lab2A是Lab2(甚至是Lab3)的骨架。具体到细节上,我们还需要实现两个RPC的发送及其Handler函数、Raft节点structure的设计、计时器的设计等等。Lab2A HINT部分的长度远超其他三个lab也从侧面体现了这一点。
这里需要强调一下在课程组的一些设计建议(前言部分的链接里提到的建议)以及测试要求、注意事项,可能会比较长,着急的朋友可直接跳到下一部分。
- 计时器的设计不要使用Go的
time.Timer或者time.Ticker,可能会造成不知名bug,非常的“tricky”。最简单的方法就是在Raft的设计里加一个成员用于表示上次收到leader心跳的时间,并用一个线程配合time.Sleep定时访问这个成员以判断是否超时。 - 由于会有很多线程会访问某个server(Raft节点)的状态,课程组建议使用
mutex的机制来访问这些需要共享的状态。实际实现时,我刚开始曾使用过Go的channel,但经常会遇到死锁,后来老老实实改成使用mutx了。_(:_」∠)_ - 每一个RPC的发送都需要使用单独的线程,以便让发送者不用等待并能够并行地发送数个RPC。
- 任何等待的过程都不要加锁,包括但不限于从channel读写数据(Start Code里的
ApplyMsg结构依旧需要使用channel)、Sleep等。并且,等待完成后需要检查自己的State有没有被改变。例如leader在心跳sleep结束后要检查一下自己是否依旧还是leader等。(对应下文代码中的some check here) - 测试要求leader发送心跳的时间每秒不得超过十次,也就是说心跳的周期需满足
>= 100ms。上一篇文章中提到,为了应对不可靠网络中经常“丢包”的情况,我的实现里在大部分情况下让Leader在每一个follower的选举周期里能够发送三次心跳,这也就意味着选举周期会大于论文中的150毫秒到300毫秒的区间。同时测试要求五秒内必须选举出leader,所以选举周期也不能太大,最终我将选举周期设定在了300到500毫秒之间。 - 对于一些
Forloop,尤其在一些长期运行的线程中,需要使用rf.killed()来某一个节点是否被kill了,以免打印出不必要的信息。我个人在通过所有2D的测试后都没有实现这一点,导致在上千次测试的过程中看到上一个测试的一些节点还在打印一些没用的信息。所以从一开始就实现这一点能省去不少麻烦。 - 所有的RPC发送都需要调用课程组提供的
labrpc包里的Call方法进行。labrpc能够模仿网络延迟、分区以及丢包操作。但是有一点需要注意的是Call方法在RPC handler没有处理或者陷入死循环时也会有一定概率无法返回,这一点可以在processReq的for循环中看到。
实际实现
实际实现的过程中,我们只需按照论文里的Figure 2进行实现即可。首先,对于Raft的structure,除了论文里提到的Raft成员外,还包括上文中提到的计时器相关的成员。代码如下所示:
// Raft A Go object implementing a single Raft peer.
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Persistent state on all servers
currentTerm int
votedFor int
logs []LogEntry
rfState RfState
// Volatile state on all servers
commitIndex int
lastApplied int
// Volatile state on leaders, Reinitialized after election
nextIndex []int
matchIndex []int
// time for election
lastUpdate time.Time
lastInter int64
}
这里为了简介起见,Lab2后三个lab里需要用到的成员以及一些课程组的注释已隐去。代码中的lastUpdate表示上次计时器reset的时间,lastInter表示计时器时长。两者的更新均只会在前一篇文章中提到过的三个地方更新:1)发起选举,2)收到Leader的AppendEntries RPC,3)投票给其他节点。更新代码如下:
func (rf *Raft) ResetTimer() {
lastT := rf.lastUpdate
oldLI := rf.lastInter
rf.lastUpdate = time.Now()
rf.lastInter = ElectionTimeOutLeast + (rand.Int63() % ElectionTimeOutDiff)
DPrintf(dTimer, "S%v T%v Reset Timer, since last Update %v, last LI %v, new LI %v",
rf.me, rf.currentTerm, time.Since(lastT),
time.Duration(oldLI)*time.Millisecond, time.Duration(rf.lastInter)*time.Millisecond)
}
RfState是我自己设置的一个structure,用于实现类似于其他语言中的枚举结构,表示server当前的身份:
// RfState state
type RfState int
const (
Follower RfState = iota
Candidate
Leader
)
func (s *RfState) String() string {
// we don't need use ... here
return []string{"Follower", "Candidate", "Leader"}[*s]
}
RfState实现了String()接口,这样当需要打印状态时,只需要调用.String()就能将RfState转换为对应的字符串了。
DPrintf(dInfo, "S%v Term %v state is %s", rf.me, rf.currentTerm, rf.rfState.String())
当Make一个server时,除了初始化Raft State外,还需要另起一个线程(ticker)用作计时器用,配合Sleep以定时轮询选举计时器是否超时。所以,这里就有一个问题:Sleep多久?
我刚开始实现的时候,直接Sleep了lastInter的时长。在2A里没出现问题,但在LabB就出现了明明超时却无法转变为Candidate发起选举的情况。其实这一点课程组已经给过我们提示:
t’s easiest to use time.Sleep() with a small constant argument to drive the periodic checks.
即我们不能直接SleeplastInter的时长,而应设置一个较小的Sleep时长,这样在一个选举计时器周期内能够多次检查计时器是否超时,而不是像我原来只检查一次。我自己在写Lab2A、B的时候没注意课程组的这个提示,导致踩了不少坑。不过也好,付出了一些时间,多了一些思考。核心代码如下:
if time.Since(updateTime) > time.Duration(interTime)*time.Millisecond {
rf.ChangeToCanAndAct()
} else {
time.Sleep(time.Duration(ElectionTimeCheck) * time.Millisecond)
}
那么,这个small constant应该设置多少呢?我们先称这个变量为ElectionTimeCheck。注意,我的实现里,ElectionTimeCheck能够将选举计时器离散化。举个例子,假入ElectionTimeCheck设置为了100毫秒,那么对于lastInter在300~400毫秒之间的计时器,他们都是一样的。因为ticker线程每隔100毫秒检查一次计时器是否超时,那么在100的倍数区间内的所有计时器长度在这里都是一样的。(如果两个server同时make,在ElectionTimeCheck为100毫秒的情况下,301毫秒计时器的server与399毫秒的计时器都会在同一个时间发现自己的计时器超时。)过度离散化的情况会导致论文中“分票”的情况发生,为此,我们需要适当地减小ElectionTimeCheck以减小离散化的情况。那么,这是不是意味着ElectionTimeCheck越小越好?其实也不然。举个极端的例子,最小的情况,就是无穷小,就是0,即不Sleep。这就导致server的Lock一直都被ticker占有,无法进行RPC的发送与接收,显然不是我们所期望的——过小的ElectionTimeCheck会导致锁的过度争用。
实际实现里,我尝试过20毫秒、五十毫秒。发现速度相差不大,最终就定在了50ms,每五十毫秒检查一次计时器。而如果要想彻底规避掉离散化这个问题,或许只能通过time.Timer或者time.Ticker实现。(欢迎讨论~~~
计时器超时后,我们就需要转变为Candidate并发送RequestVoteRPC。RequestVoteRPC Handler的逻辑在论文里讲得非常清晰,上一篇文章中也做过分析,注意一下Term之间大小关系对应的身份转换以及计时器的重置即可。这里我想讲一下关于这个RPC发送的逻辑,即上面的ChangeToCanAndAct函数。
在这个函数里,主要做的事情就是Candidate另起线程并行地向其他server发送RPC,并统计投票结果。这里有两种实现方式,一种是将发送RPC和统计投票结果都放到新的线程里进行,另一种是新线程负责发送RPC,而统计投票结果放到ChangeToCanAndAct线程里自己实现。个人感觉这两种方法没有孰优孰劣之分,自己两种都试过,速度上没有差别。最终我选择了后者。
在吸取了上面计时器的教训后,我在统计投票结果这里也使用了相同的结构,即使用For循环在选举计时周期内配合Sleep small constant轮询检查投票结果。一旦能够转换为Leader或需要转换为Follower,则break循环;否则,重置计时器,发起新一轮选举。核心代码如下,注意当Candidate成功转换为Leader时,我会立刻发送一次心跳,以防止选举计时器时间相近的Candidate发起新一轮选举的情况发生。
for !rf.killed() {
// Some init here
...
// issues RequestVote RPCs in parallel
for peerId := 0; peerId < len(rf.peers); peerId++ {
if peerId == rf.me {
continue
}
go rf.sendRequestVote(peerId, &args, &reply[peerId], &ok[peerId])
}
// check vote results
for time.Since(lastT) < time.Duration(preTime)*time.Millisecond {
cnt := 1
// Sleep a while and Check State Here
...
rf.mu.Lock()
state := rf.candidateCheckVote(&reply, &ok, cnt)
rf.mu.Unlock()
// after become a leader, send heartbeat immediately
if state != Candidate {
if state == Leader {
rf.leaderTicker()
}
break
}
}
// some check and timer reset here
...
}
candidateCheckVote的逻辑也很清晰,就是遍历每一个server,根据投票结果统计cnt,若超过半数转变为Leader即可。注意如果成功转变为Leader,需要初始化Leader特有的成员。当然,这是Lab2B涉及到的内容。此外,这里可以先暂时将lastIncludedIndex这一成员当作0来处理,Lab2D会用到。
// become a leader
if rf.rfState == Candidate && cnt > len(rf.peers)/2 {
rf.rfState = Leader
for i := range rf.peers {
rf.nextIndex[i] = len(rf.logs) + rf.lastIncludedIndex
rf.matchIndex[i] = rf.lastIncludedIndex
}
}
完成了RequestVoteRPC相关,剩下就是Leader发送心跳的RPC了。注意,发送RPC时,我们不应该将心跳与AppendEntries(后文简称AE)分开写,相反,应该将两者当作同一种RPC来对待。不同之处在于参数的初始化中所包含的LogEntry不同。对于RPC Handler,即接收者而言,在Lab2A里我们只需要根据Term的大小关系进行身份的转换即可。这里放一下发送的代码:
// some init here
...
// send rpc
for peerId := 0; peerId < len(rf.peers); peerId++ {
if peerId == rf.me {
continue
}
go rf.sendAppendEntries(peerId, &args[peerId], &reply[peerId], &ok[peerId])
}
time.Sleep(time.Duration(HeartBeatTimeOut) * time.Millisecond)
// some check here
...
interOne = time.Now()
for peerId := 0; peerId < len(rf.peers); peerId++ {
if peerId == rf.me {
continue
}
// leader's action here, which we don't need to care about in lab2A
...
}
前面提到,我的实现里保证Leader会在Follower的一个选举周期里发送三次AE。因此,这里我们不需要跟Candidate一样每隔一定时间就轮询一次reply;相反,对每个Follower,我们查看一次就好。就算某一次的reply因为各种原因导致Leader没有收到,我们下次重新发送、重新检查reply即可。
一些Bug & 想当然的细节
这里记录一下自己写Lab2A时的两个小问题:
- 自己刚开始写的时候,Candidate如果没有收到足够的选票,就会转变回Follower。显然,这里犯了一个“想当然”的错误,没有严格遵循论文中“选举失败且没有产生新Leader时需要发起新一轮选举”的要求。
- 自己刚开始时对于Go的
time不熟悉,写超时判断语句time.Since(updateTime) > time.Duration(interTime)*time.Millisecond时漏了time.Millisecond,导致测试时无限地“计时器超时、发起选举”😂。后来看了Go的官方网站才了解到,time.Duration的默认时间为纳秒,哭笑不得。
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
// source: https://pkg.go.dev/time@go1.21.5#example-Duration
日志复制
Start() 与 ApplyMsg
如果说前面一节的领导选举代码是骨架,那么这一节的日志复制即为Raft的核心。Raft是一种分布式一致性共识算法,这个一致与共识的对象,就是日志LogEntry。除了论文给出的两个成员外,LogEntry还有一个重要的成员为索引index,不过这个不用定义在结构体内,可以直接使用Raft结构体内对应的索引下标代替。故,我们只需这样定义LogEntry结构体:
// LogEntry log entries
type LogEntry struct {
Command interface{} // command for state machine
LogTerm int // term when entry was received by leader (first index is 1)
}
Lab2B中,HandOut里提到了两个内容,Start()函数和ApplyMsg channel。我们结合下面这幅课程组给的图理解一下其意思:
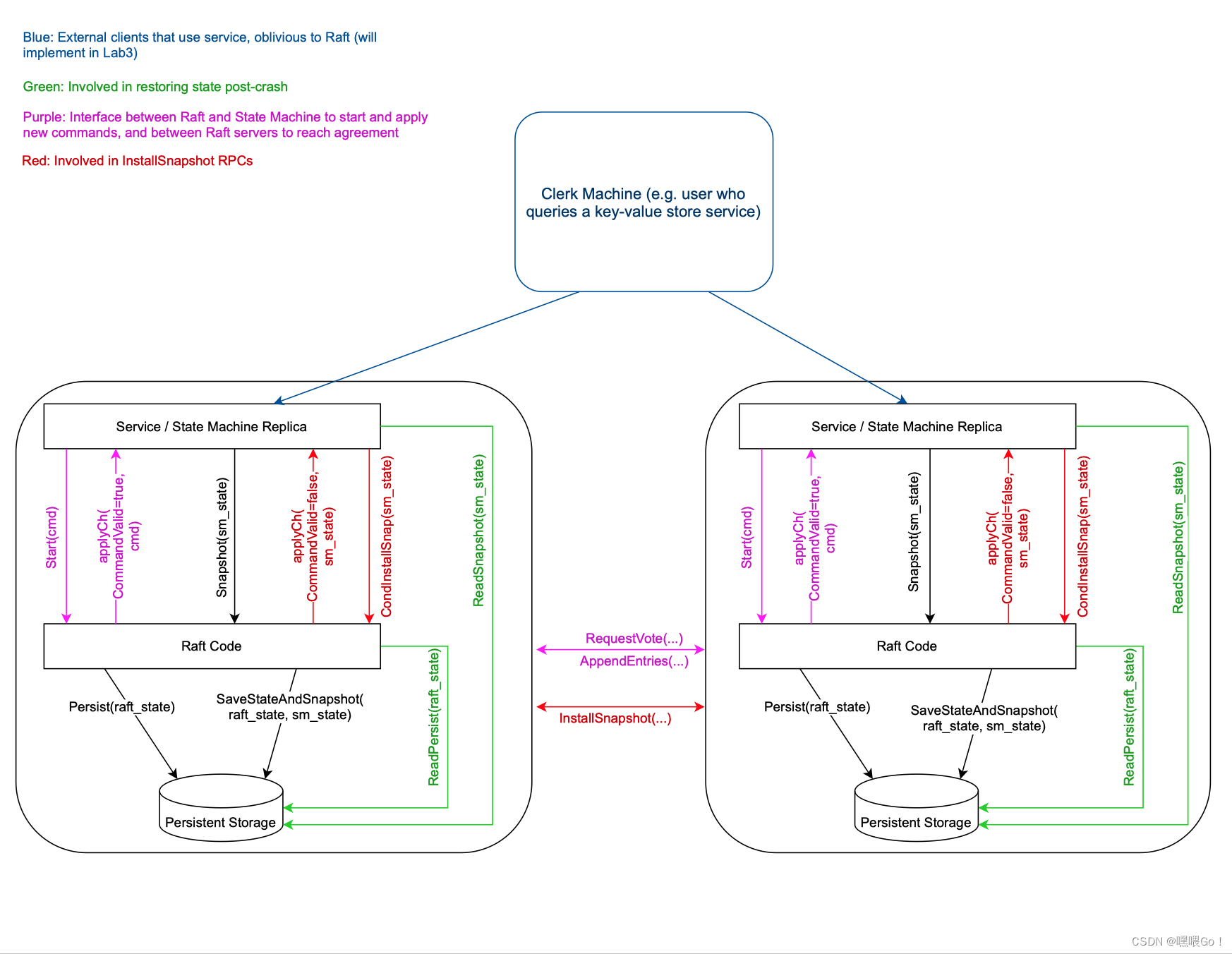
在浅析Raft算法的文章中提到过,每个server主要包含两层:一层为State Machine,可以将其理解为一个Key/Value键值库(或者就简单理解为一个map);另一层就为Lab2中需要实现的Raft层。当Leader server从客户端,即图中的Clerk Machine中得到一条指令时(例如Get或者Put),server并不会将指令直接应用到State Machine上。相反,server会首先将指令封装为LogEntry,发送到Raft层。Raft层之间通过RPC达成共识,使得这条LogEntry被复制到过半数的server的Logs中时(即这条LogEntry已提交),这条LogEntry才会被每一个server apply到自己的State Machine上。以上过程中,将指令封装为LogEntry,发送到Raft层就是我们要实现的Start(),而将LogEntry应用到State Machine,就是使用课程组提供的ApplyMsgchannel。
这么一来,Start()函数的逻辑就很清晰了:首先我们需要判断当前的server是否为leader,如果不是,直接返回;否则,将command封装为一个LogEntry,并append至serevr的log即可。函数每个返回值的具体含义在注释里都有,很好理解;而对于LogEntry的apply,会稍微复杂一点点。先看一下课程组的这段话:
You’ll want to have a separate long-running goroutine that sends committed log entries in order on the applyCh. It must be separate, since sending on the applyCh can block; and it must be a single goroutine, since otherwise it may be hard to ensure that you send log entries in log order.
为了保证LogEntry中的command是按序apply的,我们必须使用一个单独的线程来apply。同时,对于每一个server,都要有且仅有一个这样的线程来将command应用至自己的状态机上。每当检测到有LogEntry可以apply时,就将LogEntry里的command封装为一个ApplyMsg,并发送至channel;而没有LogEntry可以apply时,我们可以使用Go的*sync.Cond条件变量进行等待。当server有新的LogEntry提交时,调用Broadcast()方法通知apply线程提交command,主要代码如下,condition()为commitIndex > lastApplied,lastIncludedIndex先当成0:
func (rf *Raft) ApplyTicker() {
rf.cv.Lock()
defer rf.cv.Unlock()
for !rf.killed() {
for !rf.condition() {
rf.applyCV.Wait()
}
rf.mu.Lock()
for rf.lastApplied++; rf.lastApplied <= rf.commitIndex; rf.lastApplied++ {
applyMsg := ApplyMsg{
CommandValid: true,
Command: rf.logs[rf.lastApplied-rf.lastIncludedIndex].Command,
CommandIndex: rf.lastApplied,
}
rf.mu.Unlock()
rf.applyChM <- applyMsg
rf.mu.Lock()
}
rf.lastApplied--
rf.mu.Unlock()
}
}
这里Raft结构多了以下几个成员:
type Raft struct {
...
// channel for applyMsg
applyChM chan ApplyMsg
// for applyTicker
cv sync.Mutex
applyCV *sync.Cond
..
}
applyChM为channel,在Make里直接将对应的参数传过来就好,不需要传指针;后两个则为条件变量相关的成员。
AppendEntries RPC
完成了以上两个内容,剩下的就为Log Replica的核心内容了。日志复制的核心在于Leader发送AE RPC与接收reply、Follower接收并处理AE rpc的逻辑,同时还要需要实现5.4.1节中领导选举的限制(加一个LogEntry的新旧对比)。具体的步骤上一篇文章中已经讲过了,Figure 2中的AppendEntries RPC以及Rules for Servers的Leader部分也讲得很详细,这里主要强调几个细节:
首先是在AE Handler里对于Leader发送的Entries的Append处。,这里我刚开始的时候,在检查完是否有冲突的LogEntry之后,默认会append Leader发送的Entries里特定index开始的所有LogEntry。但实际上,并不是每种情况都需要append的。我们重新看一下论文里的原话:
- If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
- Append any new entries not already in the log
这里not already一词非常重要,换句话说,如果Entries里的LogEntryFollower已全部拥有了,那么此时是不需要append的。说白了,就是下图中的这种情况,Entries里包含的LogEntry与Follower的logs并不存在冲突。
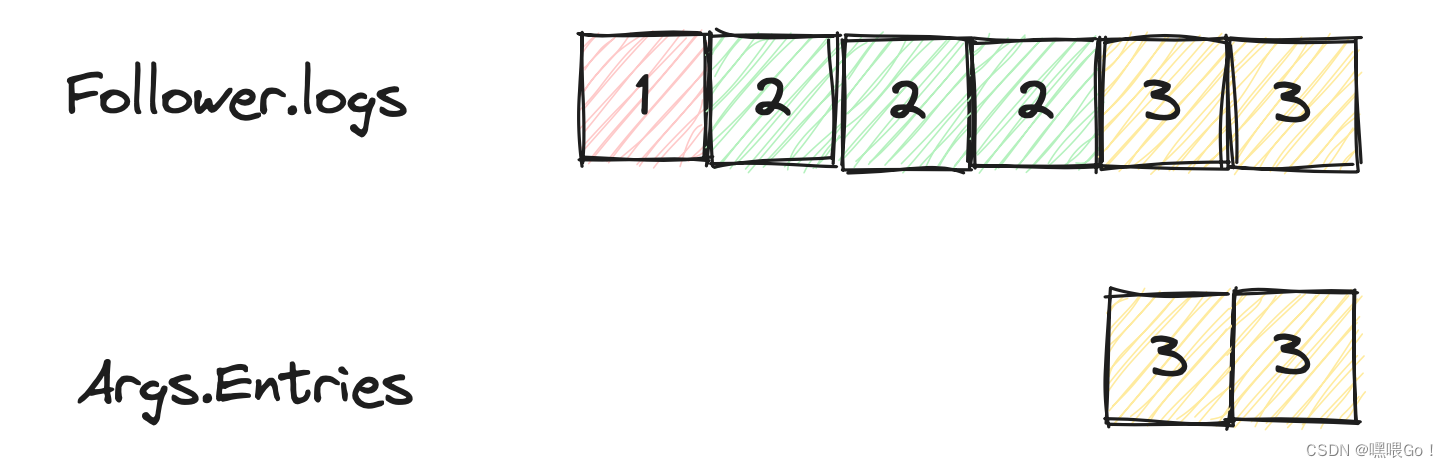
在Term3,Leader发送给Follower的AE RPC里包含了两条LogEntry,Follower收到后成功append并返回;但因为网络问题,Leader没有成功接收到这个reply,于是在下个心跳周期重新发送了一个包含两个相同LogEntry的AE RPC,即如图中所示。此时Follower已经有了这两条LogEntry,不需要Append。
总结一下,就是有冲突时,需要append,没有冲突时,不需要append。这里的冲突指在相同的index上Term不同,或者Follower的logs比PrevLogIndex + len(args.Entries)更短。核心代码如下:
// AppendEntries RPC Handler
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// check term and log consistency here
...
// heartbeat
if len(args.Entries) == 0 {
...
} else {
hasConf, index := rf.DeleteConflictLogs(args)
// append any new logs in args **not already** in
if hasConf {
rf.AppendFollowerEntries(args, index)
} else {
// don't append
}
}
...
}
func (rf *Raft) DeleteConflictLogs(args *AppendEntriesArgs) (bool, int) {
var index int
hasConf := false
// delete all logs from conflict index
for i, log := range args.Entries {
...
index = i + args.PrevLogIndex + 1
if index >= len(rf.logs)+rf.lastIncludedIndex ||
rf.logs[index-rf.lastIncludedIndex].LogTerm != log.LogTerm {
rf.logs = append([]LogEntry{}, rf.logs[:index-rf.lastIncludedIndex]...)
rf.persist()
hasConf = true
break
}
}
...
return hasConf, index
}
这里依旧先把rf.lastIncludedIndex看作0即可。
接着是Leader 发送RPC的逻辑。发送时只需要根据PrevLogIndex和Leader本身的logs长度初始化Entries即可,这里主要关注对于回复的处理,对应Figure 2中右下角的部分。如果reply的success为false,那么需要根据返回的Term的情况进行对应的操作:如果Term与Leader的Term相等,说明发送的RPC不满足LogEntry的一致性检查,因此减小nextIndex的值并在下一个AE RPC中重试;如果Term大于Leader的term,需要转换为Follower。
如果reply的Success为True,说明发送的Entries里的LogEntry已成功复制至Follower,此时我们也需要更新nextIndex,同时也要更新matchIndex。这里一开始的时候,我认为Follower既然已经成功复制了Leader的logs,那么直接将nextIndex更新为Leader此时的len(logs) + 1,matchIndex更新为len(logs)即可。这么做可以通过Lab2B的测试,但在Lab2C会出问题,具体的问题我们放在Lab2C中讲,可以先思考一下。
最后,我们需要更新Leader的commitIndex。这里考虑到其实server的数量不是很多,我就直接用一个for循环进行遍历了。边遍历边维护matchIndex中超过半数的最大的N,以更新commitIndex。详细的逻辑可以看论文Figure 2的最后一点。注意这部分运行完后,调用rf.applyCV.Broadcast()通知ApplyTicker线程以查看是否有代码可以apply,Follower同理。
一些Bug
Lab2B里遇到的最主要的Bug其实就是上文Lab2A里提到的对于计时器超时的检测。原先我的逻辑是每个计时周期内只会检查一次是否超时。这就导致有时候明明超时了但还是不发起选举的情况发生,最终没有选举出Leader而测试失败。修改后通过测试。此外,在Lab2B还实现了nextIndex索引回退的优化,可以大幅减少Backup2B的测试时间,这一点在上一篇文章的优化部分也提到过,细节会放在Lab2C中讲。
后记
本打算将Lab2的实现放在一篇文章写完的,但写完Lab2B才发现字数已经一万六了,所以还是分成两篇。总结下来,写完Lab2B后的收获还是非常大的,最主要就是关于多线程编程的一些要点:什么时候加锁、什么时候Sleep、Sleep完后的状态检查等,确实对自己的代码设计思想带来了很大的帮助。除此以外,也更加熟悉了Go的一些特性,对Raft的理解也更深了一步。当然,哪怕通过Lab2的测试上千次,也不意味代码肯定没有Bug了——我在写Lab3时就发现了Lab2的测试代码没有覆盖的场景,这一点也会在Lab2C、D的文章里提到。
最后,这篇文章花了六小时的时间,如果能够帮到你,那么就是值得的。















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









