









24年1月北京通用智能研究院、北大和北邮的论文“CivRealm: a learning and reasoning odyssey in civilization for decision-making agents”。
决策智体的泛化包括两个基本要素:从过去的经验中学习和在新的环境中推理。然而大多数交互环境中,主要强调的是学习,以牺牲推理的复杂性为代价。CivRealm,一个受Civilization游戏启发的环境。Civilization与人类历史和社会的深刻契合需要复杂的学习,而其不断变化的情况需要强有力的推理来概括。特别是,CivRealm建立一个玩家数量不断变化的不完全信息总和游戏;它呈现了大量复杂的特征,挑战了智体处理开放式随机环境,这些环境需要外交手腕和谈判技巧。在CivRealm中,为两种典型智体类型提供接口:专注于学习基于张量的智体和强调推理基于语言的智体。基于规范RL的智体在迷你游戏中表现出合理的性能,而基于RL和LLM的智体都难取得实质性进展。代码开源 https://github.com/bigai-ai/civrealm.
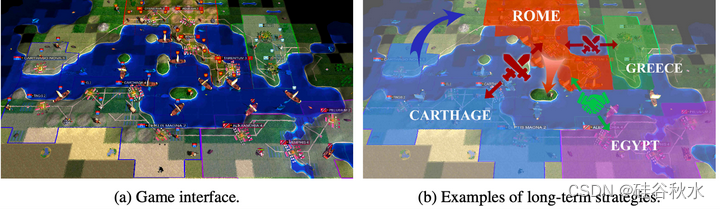
如图所示:Civilization的游戏需要深入的推理,包括长期的战略规划和精细的战术控制。该图描绘了一个类似历史场景的假设情况,罗马人保护西西里岛对抗迦太基,同时与衰落的埃及建立友好的外交关系。这一决定是在一个高度复杂的背景下做出的:参与者需要在特定的地理和外交背景下考虑长期发展战略的各个方面,如技术、军事和外交。他们还参与精细控制动作,例如边境勘探、轮船建造和道路建设。
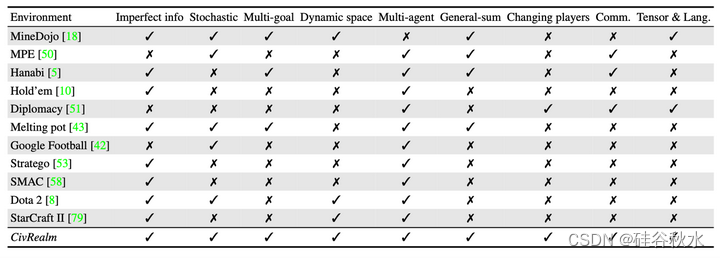
下表是各种环境比较。Imperfect info: 全状态可部分观测. Stochastic: 环境动态是不确定的. Multi-goal: 游戏中有多个胜利条件. Dynamic space: 单个玩家的状态和动作空间在游戏中动态改变. Multi-agent: 游戏中有多个交互玩家. General-sum: 混合动机游戏,其中合作和竞争共存. Changing players: 单个游戏中玩家数可以增加或减少. Comm.: 游戏中玩家显示通信. Tensor & Lang.: 环境提供张量和语言APIs.
CivRealm使每个智体都能在开源回合制战略游戏Freeciv中扮演玩家。CivRealm采用服务器-代理-客户端框架并实现智体API,以便服务器托管游戏,并且代理建立智体(即客户端)与服务器之间的连接。代理将服务器接收的游戏状态分发给每个智体,并将返回的动作提交给服务器。通过这种设计,具有各种架构的智体可以通过解释代理提供的观察结果并生成符合CivRealm规范的动作,无缝地参加Freeciv中。
Freeciv是一款回合制游戏,无需实时反应即可运行。这种速度与LLM智体匹配。
CivRealm提供方法来创建新场景,例如生成不同景观、不同玩家和单位数量的随机地图,或者修改基本游戏规则的集合。智体对潜在的游戏机制进行推理,而不仅依赖记忆中的经验和公共知识,可评估决策智体的泛化能力。CivRealm提供广泛的学习和推理任务,不仅包括Freeciv的全面完整游戏,还包括使用Lua脚本设计的小型迷你游戏。
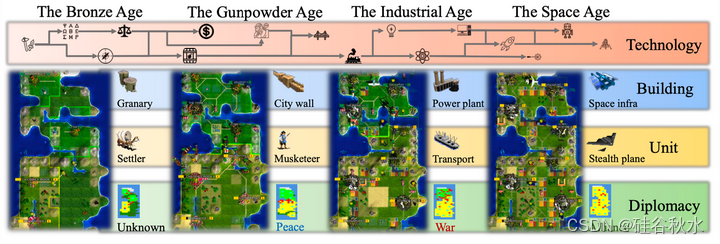
如图所示:文明随游戏展开而进化,潜在状态和行动空间爆炸。这一数字集中在8个时代中的4个,其中技术进步解锁了更多的建筑和单元。在整个游戏过程中,状态可以从1015增长到10650,动作空间可以从104扩展到10166。此图仅显示了一些示例元素;整个游戏包括87种技术、68种建筑、52种单元、6种政府和5个外交国家,所有这些都受规则集的约束,并且是可定制的。
在CivRealm中,设计10种迷你游戏,并使用生成工具为每类生成10000个实例。游戏可以分为三类:开发、战斗和外交。如图是一些例子:
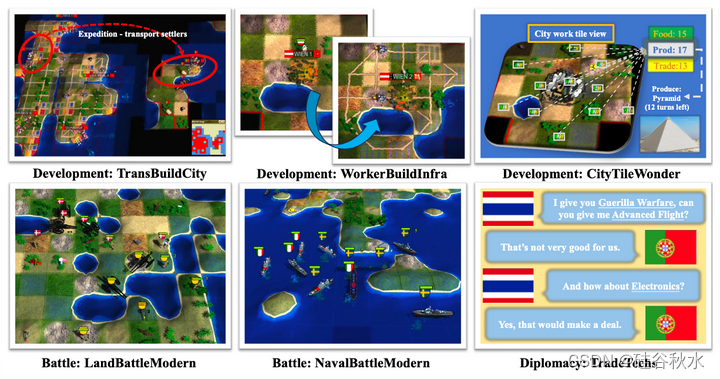
开发迷你游戏旨在培育城市,关注人口增长、生产效率和经济繁荣等因素。这些因素与一个文明的整体实力和进步密切相关。
战斗迷你游戏围绕着敌对部队之间的战术战展开。熟练的指挥官旨在击败敌人,同时最大限度地减少自己的损失。
外交迷你游戏是文明游戏的一大特色。掌握外交技能至关重要,因为与其他玩家保持积极的关系会对游戏过程产生重大影响。
如图所示是三种基线方法,包括:1)受AlphaStar启发,基于正则张量的RL方法,2)与AutoGPT类似的LLM方法BaseLang,3)独个BaseLang模型的分层合并Mastaba。
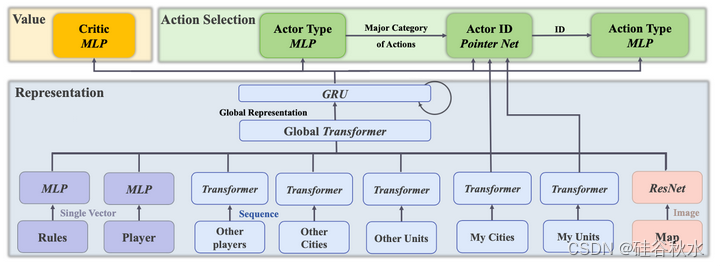
如图是基于正则张量的RL方法架构,其网络有三个主要部分。表征:用MLP、Transformer和CNN模型来提取基于输入(矢量、序列或基于图像)的特征。这些特征通过一个transformer全局连接,RNN将当前状态特征与历史上下文的内存状态相结合。行动选择:用学习的表征来做出决定。行动者模块选择主要动作类别(例如,单位、城市、政府或回合终止),然后是选择特定动作ID的指针网络。价值估计:包括一个价值预测头,实现AC学习,共享训练效率的表征。用PPO训练网络,并采用Ray并行化张量环境。
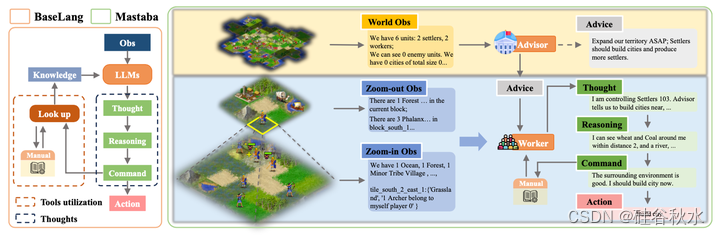
在CivRealm中开发基于LLM智体的需求源于两个因素:1) LLM能够生成任务和解决问题,并通过其广泛的人类知识库得到增强;他们的能力和知识有助于解决决策问题;2) LLM对于复杂推理还不够复杂;在CivRealm中,LLM的优势在于它能够使用自然语言、优先考虑战略游戏和处理外交互动;然而,构建这样一个智体面临着几个挑战,包括管理多个游戏中的角色,处理稀疏和复杂的观察,评估行动的长期影响,以及随时间推移改进智体的决策。
设计一个基于基线语言的智体,由三个组件组成:观察、推理和命令。采用5x5 tiles观察,以每个单元位置为中心,优化战术信息规定,同时适应战略纵深。推理模块模仿AutoGPT,分三个阶段输出:思考、推理和命令。命令使智体能够在“手动和历史搜索”和“最终决策”命令之间进行选择,从矢量数据库中检索数据,或根据环境和历史上下文选择要执行的可用操作。最后,为每个单元分配独个LLM及其上下文历史,以便进行详细规划。
为了促进独立智体之间的合作,Mastaba引入分层结构,将LLM workers、观察和决策组织成金字塔状结构。在Mastaba,LLM worker被分为两层。最重要的是“advisor”,负责监督所有其他LLM员工。 advisor监测全国范围内的整体情况,包括单位数量、城市指标和敌人/玩家信息。在运营层面,Mastaba保留了类似BaseLang结构的LLM worker。Mastaba采用类似金字塔的地图,将来自15×15tiles区域的数据浓缩为9块,每块5×5tiles。这种设计使个体能够在更大范围内掌握信息,同时有效地管理提示的加载,从而提高地-图觉察度。Mastaba的决策工作流程遵循其智体结构。advisor通过全国范围的评估初始化每一回路,包括城市、单位和潜在威胁。它在每个回合中生成建议,并将其传达给其他LLM workers,后者独立地为其实体选择动作。此外,workers还能够查询矢量数据库中的知识,从而能够根据手动或存储的经验做出明智的决策。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









