







作者:李呈祥
作者简介:Intel BigData Team软件工程师,主要关注大数据计算框架与SQL引擎的性能优化,Apache Hive Committer,Apache Flink Contributor。
责任编辑:仲浩(zhonghao@csdn.net)
文章来源:《程序员》2月期
版权声明:本文为《程序员》原创文章,未经允许不得转载,订阅2016年《程序员》请点击 http://dingyue.programmer.com.cn
Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注。本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解,对其他大数据系统开发者也能有所裨益。本文假设读者已对MapReduce、Spark及Storm等大数据处理框架有所了解,同时熟悉流处理与批处理的基本概念。
Flink简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
Flink的技术栈如图1所示:
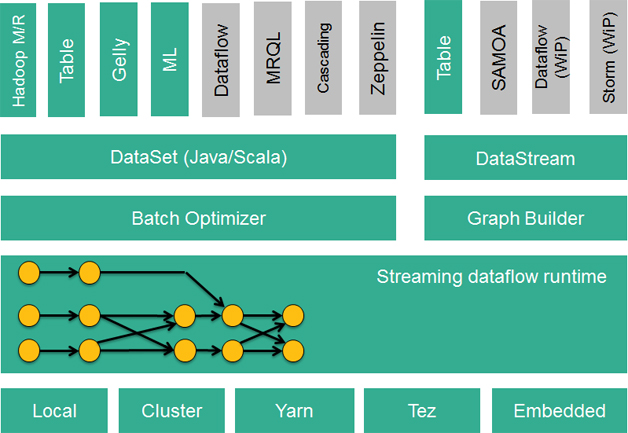
此外,Flink也可以方便地和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce或Storm代码,或是通过YARN申请集群资源等。
统一的批处理与流处理系统
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据项目一般会被设计为只能处理其中一种任务,例如Apache Storm、Apache Smaza只支持流处理任务,而Aapche MapReduce、Apache Tez、Apache Spark只支持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似一个特例,实则不然——Spark Streaming采用了一种micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Apache Storm、Apache Smaza等完全流式的数据处理方式完全不同。通过其灵活的执行引擎,Flink能够同时支持批处理任务与流处理任务。
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求。Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟。如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量。同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
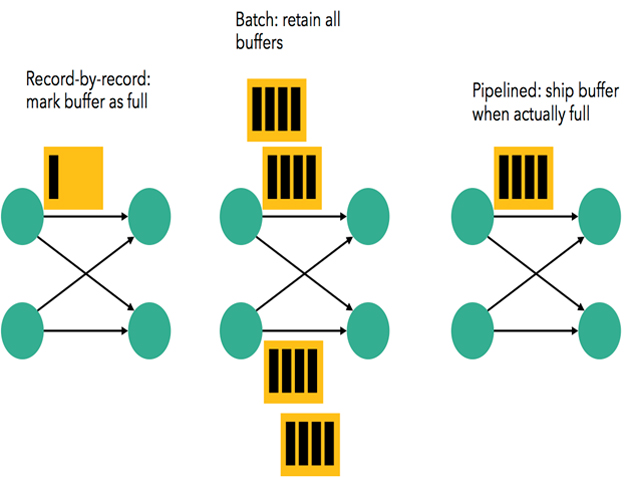
在统一的流式执行引擎基础上,Flink同时支持了流计算和批处理,并对性能(延迟、吞吐量等)有所保障。相对于其他原生的流处理与批处理系统,并没有因为统一执行引擎而受到影响从而大幅度减轻了用户安装、部署、监控、维护等成本。
Flink流处理的容错机制
对于一个分布式系统来说,单个进程或是节点崩溃导致整个Job失败是经常发生的事情,在异常发生时不会丢失用户数据并能自动恢复才是分布式系统必须支持的特性之一。本节主要介绍Flink流处理系统任务级别的容错机制。
批处理系统比较容易实现容错机制,由于文件可以重复访问,当某个任务失败后,重启该任务即可。但是到了流处理系统,由于数据源是无限的数据流,从而导致一个流处理任务执行几个月的情况,将所有数据缓存或是持久化,留待以后重复访问基本上是不可行的。Flink基于分布式快照与可部分重发的数据源实现了容错。用户可自定义对整个Job进行快照的时间间隔,当任务失败时,Flink会将整个Job恢复到最近一次快照,并从数据源重发快照之后的数据。Flink的分布式快照实现借鉴了Chandy和Lamport在1985年发表的一篇关于分布式快照的论文,其实现的主要思想如下:
按照用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3097
3097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









