







介绍
创造出具有自我学习能力的机器——人们的研究已经被这个想法推动了十几年。如果要实现这个梦想的话,无监督学习和聚类将会起到关键性作用。但是,无监督学习在带来许多灵活性的同时,也带来了更多的挑战。
在从尚未被标记的数据中得出见解的过程中,聚类扮演着很重要的角色。它将相似的数据进行分类,通过元理解来提供相应的各种商业决策。
在这次能力测试中,我们在社区中提供了聚类的测试,总计有1566人注册参与过该测试。如果你还没有测试过,通过阅读下面的文章,你可以统计一下自己能正确答对多少道题。
总结果
下面是分数的分布情况,可以帮你评估你的表现:
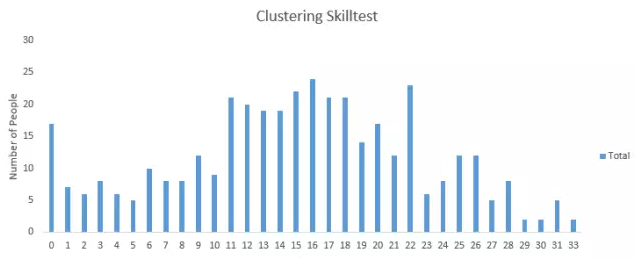
你也可以通过访问这里来查看自己的成绩。超过390个人参加了测试,最高分数是33分。下面是对分数分布的部分统计。
总分布:
平均分:15.11
中位数:15
模型分数:16
相关资源:
- An Introduction toClustering and different methods of clustering
- Getting yourclustering right (Part I)
- Getting yourclustering right (Part II)
Questions & Answers
Q1. 电影推荐系统是以下哪些的应用实例:
1. 分类
2. 聚类
3. 强化学习
4. 回归
选项:
A. 只有2
B. 1和2
C. 1和3
D. 2和3
E. 1 2 3
F. 1 2 3 4
答案: E
一般来说,电影推荐系统会基于用户过往的活动和资料,将用户聚集在有限数量的相似组中。然后,从根本上来说,对同一集群的用户进行相似的推荐。
在某些情况下,电影推荐系统也可以归为分类问题,将最适当的某类电影分配给特定用户组的用户。与此同时,电影推荐系统也可以视为增强学习问题,即通过先前的推荐来改进以后的电影推荐。
Q2. 情感分析是以下哪些的实例:
1. 回归
2. 分类
3. 聚类
4. 强化学习
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









