







 本文介绍了如何使用RNN模型实现文本自动生成,包括基于关键词的文本生成和RNN模型的细节。通过关键词提取、同义词识别、句子相似度计算等技术,生成与输入关键词或句子意思相近的文本。并探讨了不同场景下的文本生成方法,如广告描述的自动生成。
本文介绍了如何使用RNN模型实现文本自动生成,包括基于关键词的文本生成和RNN模型的细节。通过关键词提取、同义词识别、句子相似度计算等技术,生成与输入关键词或句子意思相近的文本。并探讨了不同场景下的文本生成方法,如广告描述的自动生成。
在自然语言处理中,另外一个重要的应用领域,就是文本的自动撰写。关键词、关键短语、自动摘要提取都属于这个领域中的一种应用。不过这些应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括句子的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本自动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词识别等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时候,我们需要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为鲜花广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望产生一定数量的候选一句话广告描述。
对于这种场景,也可能输入的是一句话,比如之前人工撰写了一个例子:“这个周末,小白鲜花只要99元,并且还包邮哦,还包邮哦!”。需要根据这句话复写出一定数量在表达上不同,但是意思相近的语句。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。
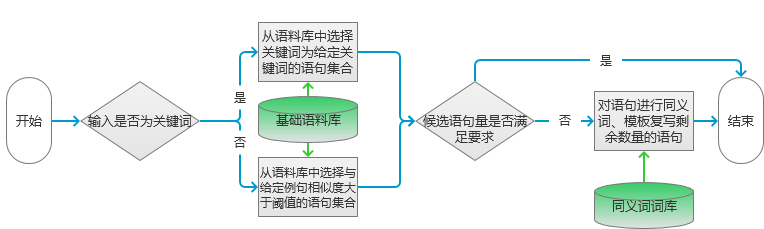
- 首先根据输入的数据类型不同,进行不同的处理。如果输入的是关键词,则在语料库中选择和输入关键词相同的语句。如果输入的是一个句子,那么就在语料库中选择和输入语句相似度大于指定阈值的句子。
- 对于语料库的中句子的关键词提取的算法,则使用之前章节介绍的方法进行。对于具体的算法选择可以根据自己的语料库的形式自由选择。
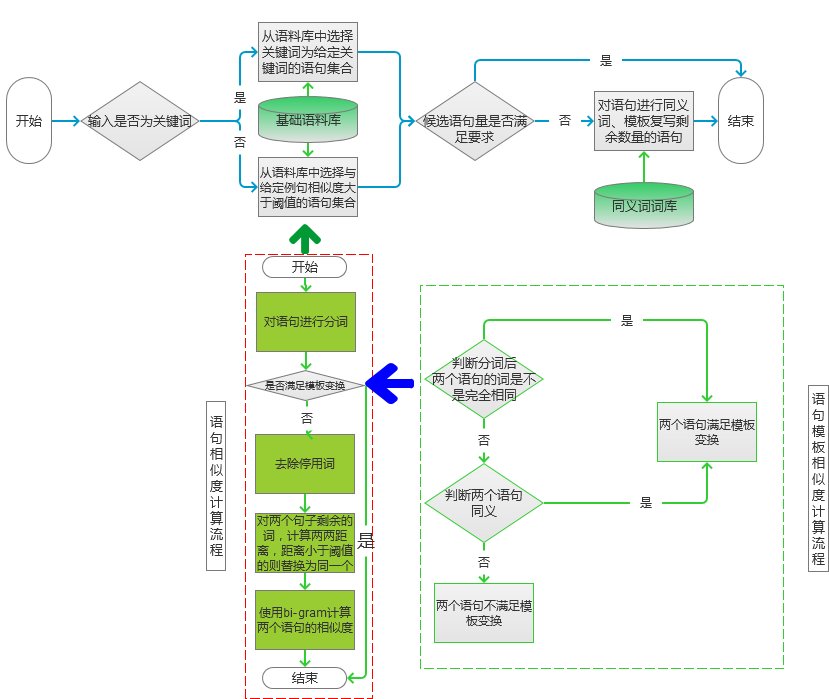
图2 - 语句相似度计算,这里按照图2左边虚线框中的流程进行计算:
- 首先对待计算的两个语句进行分词处理,对于分词后的语句判断其是否满足模板变换,如果满足则直接将语句放入候选集,并且设置相似度为0。如果不满足则进入到c)步进行计算。
- 判断两个语句是否满足模板变换的流程图,如图2中右边虚线框所标记的流程所示:(1)首先判断分词后,两个句子的词是不是完全一样,而只是位置不同,如果是则满足模板变换的条件。(2)如果词不完全相同,就看看对不同的词之间是否可以进行同义词变换,如果能够进行同义词变换,并且变换后的语句两个句子去公共词的集合,该集合若为某一句话的全部词集合,则也满足模板变换条件。(3)如果上述两个步骤都不满足,则两个句子之间不满足模板变换。
- 对两个句子剩余的词分别两两计算其词距离。假如两个句子分别剩余的词为,句1:“鲜花”、“多少钱”、“包邮”。句2:“鲜花”、“便宜”、“免运费”。那么其距离矩阵如下表所示:
- 得到相似矩阵以后,就把两个句子中相似的词替换为一个,假设我们这里用“包邮”替换掉“免运费”。那么两个句子的词向量就变为:句1:<鲜花、多少钱、包邮>,句2:<鲜花、便宜、包邮>。
- 对于两个句子分别构建bi-gram统计向量,则有:(1)句1:< begin,鲜花>、<鲜花,多少钱>、<多少钱,包邮>、<包邮,end>。(2)句2:< begin,鲜花>、<鲜花,便宜>、<便宜,包邮>、<包邮,end>。
- 这两个句子的相似度由如下公式计算:
- 所以上面的例子的相似度为:1.0-2.0*2/8=0.5。
- 完成候选语句的提取之后,就要根据候选语句的数量来判断后续操作了。如果筛选的候选语句大于等于要求的数量,则按照句子相似度由低到高选取指定数量的句子。否则要进行句子的复写。这里采用同义词替换和根据指定模板进行改写的方案。


实现
实现候选语句计算的代码如下:
Map<String, Double> result = new HashMap<String, Double>();
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









