







论文地址:https://arxiv.org/abs/1706.03762
你只需要注意力
1. 引言
递归神经网络(如LSTM和门控递归神经网络)在序列建模和转换问题(如语言建模和机器翻译)中已成为最先进的方法。本文提出了一种新的简单网络架构——Transformer,该架构完全基于注意力机制,摒弃了递归和卷积。实验表明,在机器翻译任务中,Transformer在质量上优于现有模型,且更易于并行化,训练时间显著减少。
2. 背景
减少序列计算的目标也构成了扩展神经GPU、ByteNet和ConvS2S的基础,这些模型都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。然而,这些模型中,任意输入或输出位置之间的操作数量随位置之间的距离增长,这使得学习远距离位置之间的依赖关系变得更加困难。Transformer通过多头部注意力机制减少了这种操作数量。
- 模型架构
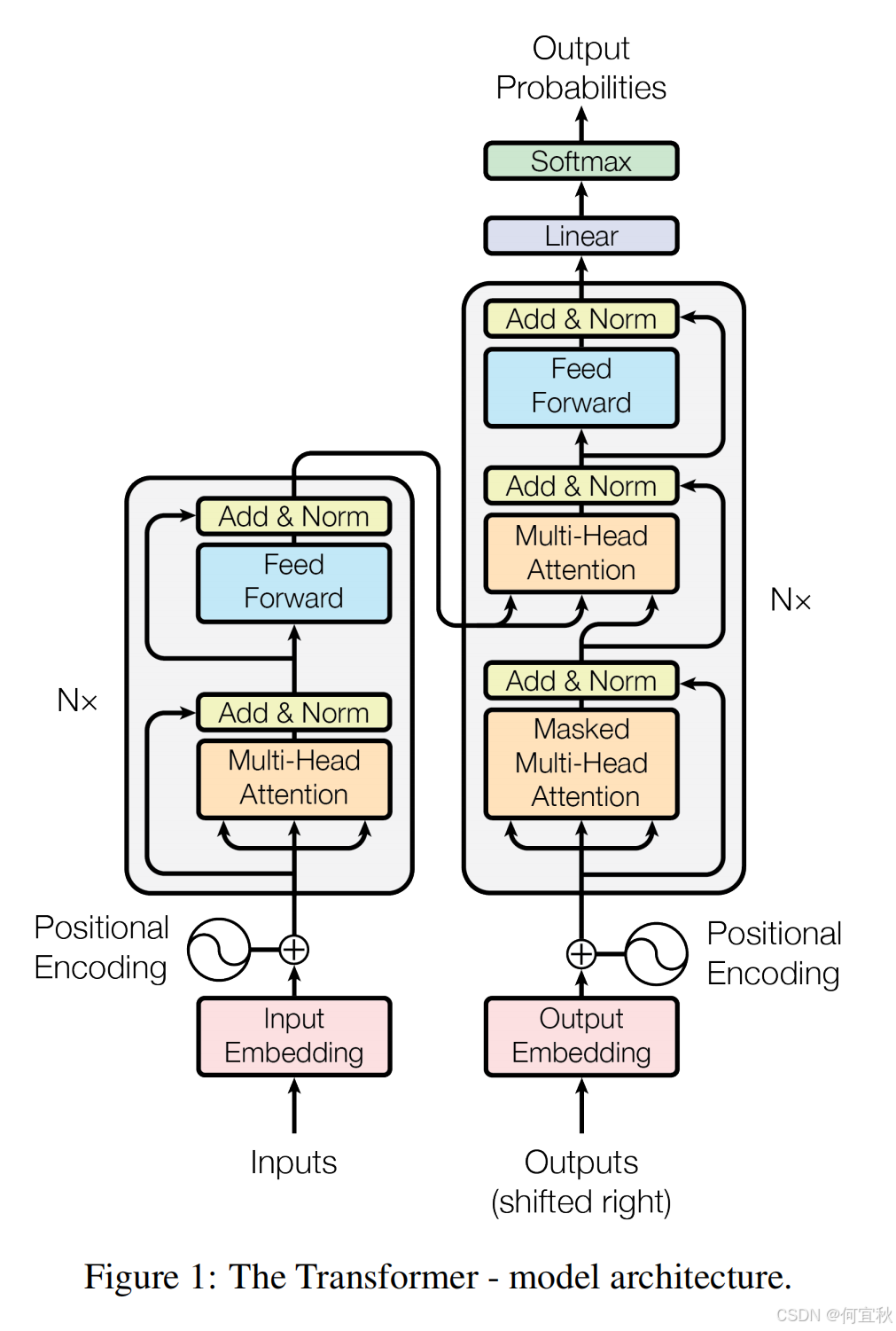
大多数竞争性神经序列转换模型采用编码器-解码器结构。编码器将输入序列映射到连续表示序列,解码器生成输出序列。Transformer遵循这种整体架构,使用堆叠的自注意力和逐点全连接层构建编码器和解码器。
3.1 编码器和解码器堆栈
编码器:由N=6个相同的层堆叠而成,每层有两个子层(多头自注意力和逐点全连接前馈网络),并采用残差连接和层归一化。具体来说,每个子层的输出为:
LayerNorm(x+Sublayer(x))
其中,Sublayer(x)是子层自身实现的函数。为了便于残差连接,所有子层以及嵌入层的输出维度均为dmodel=512。
解码器:同样由N=6个相同的层堆叠而成,除了编码器的两个子层外,解码器还插入了一个子层,用于对编码器堆栈的输出进行多头注意力计算。解码器中的自注意力子层经过修改,以防止位置关注到后续位置。这种掩码与输出嵌入偏移一个位置相结合,确保位置i的预测仅依赖于小于i的位置的已知输出。
3.2 注意力
注意力函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出均为向量。输出计算为值的加权和,权重由查询与相应键的兼容性函数计算。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1720
1720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









