







system.clusters
下面示例了几种常用方式来查看 system.clusters 中的 all-replicated 和 all-sharded 两个内置虚拟集群的信息。
1. 直接查询 system.clusters 系统表
system.clusters 视图会列出所有在 <remote_servers> 配置中定义的集群,以及 ClickHouse 启动时自动生成的两个聚合虚拟集群:
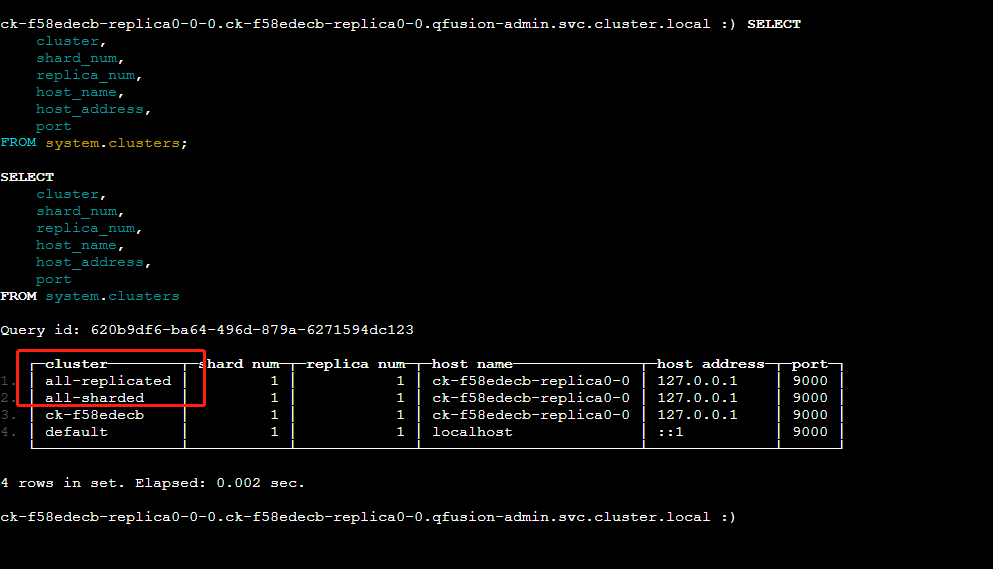
SELECT
cluster,
shard_num,
replica_num,
host_name,
host_address,
port
FROM system.clusters
WHERE cluster IN ('all-replicated', 'all-sharded');
cluster列即为集群名称,包括all-replicated(按副本汇总)和all-sharded(按分片汇总)。shard_num/replica_num分别表示该行对应的分片与副本编号。host_name/host_address/port则为实际节点信息。(ClickHouse)
2. 使用 SHOW CLUSTERS 语句
ClickHouse 提供了 SHOW CLUSTERS 以及针对某个集群的 SHOW CLUSTER <name>:
-- 列出所有集群名称(含虚拟聚合集群)
SHOW CLUSTERS;
-- 查看 all-sharded 集群的详细节点列表
SHOW CLUSTER 'all-sharded';
-- 查看 all-replicated 集群的详细节点列表
SHOW CLUSTER 'all-replicated';
SHOW CLUSTERS会从system.clusters中读取所有cluster值并去重。SHOW CLUSTER <name>则返回与上述SELECT … FROM system.clusters WHERE cluster = <name>等价的行。(ClickHouse)
3. 用 Table Function 跨节点查询(可选)
如果想跨集群节点查询其他系统表(如 system.parts、system.metrics 等),可配合 clusterAllReplicas(或 cluster 函数)使用:
-- 在 all-replicated 虚拟集群上查询所有节点的 system.metrics
SELECT *
FROM clusterAllReplicas('all-replicated', system.metrics)
LIMIT 10;
该方式会自动将查询分发到所有副本(或所有分片),并合并结果,便于集中监控和诊断。(ClickHouse)
通过上述几种方法,即可方便地在 SQL 层面查看并验证 all-replicated 与 all-sharded 这两个内置虚拟集群的节点分布和元数据信息。
all-sharded 与 all-replicated
下面对 system.clusters 中的两个内置虚拟聚合集群 all-sharded 与 all-replicated 的作用进行重新整合说明,并附上官方文档及社区高质量来源。
概览
system.clusters 系统表列出了配置文件 <remote_servers> 中定义的集群,以及在服务启动时自动生成的两种聚合逻辑集群:
all-sharded:将所有节点当作不同的分片(Shard)对待;all-replicated:将所有节点当作同一分片的不同副本(Replica)对待。
这两者为用户在不额外修改配置的情况下,提供了“按分片汇总”和“按副本汇总”两种全局视图,非常方便跨节点的诊断和查询(ClickHouse)。
all-sharded:按分片汇总
-
定义:把集群中每个物理节点都当作一个独立的 Shard,且不考虑副本关系,只在逻辑上分片。
-
用途:
- 当你希望对“每个节点都执行一次查询”并汇总结果(如全量数据扫描、集群范围统计)时使用;
- 与
cluster('all-sharded', …)表函数配合,可直接将查询并发分发到所有节点(ClickHouse); SHOW CLUSTER 'all-sharded'会返回每个节点的shard_num = 1, 2, …,replica_num = 1等信息。
-
来源:Altinity 知识库明确定义了该虚拟集群的含义:
“all-sharded: All nodes are listed as separate shards with no replicas.” (Altinity® Knowledge Base for ClickHouse®)
all-replicated:按副本汇总
-
定义:把集群中每个物理节点都当作同一 Shard 的多个 Replica,即
shard_num = 1且replica_num顺序枚举。 -
用途:
- 当你希望对“同一数据副本的所有节点”执行健康检查或比对,或想并发查看某分片上所有副本的状态时使用;
- 与
clusterAllReplicas('all-replicated', …)表函数配合,可针对所有副本执行查询并合并结果(ClickHouse); SHOW CLUSTER 'all-replicated'会列出shard_num = 1且replica_num = 1, 2, …的所有节点。
-
来源:Altinity 同一篇文档中指出:
“all-replicated: All nodes are listed as replicas in a single shard.” (Altinity® Knowledge Base for ClickHouse®)
生成机制与 SQL 接口
-
自动生成
- 启动时,ClickHouse 读取
<remote_servers>配置后,除了用户自定义的<cluster>节点配置,还会附加这两条“虚拟”聚合集群记录到system.clusters中,实际不写入 ZooKeeper 或持久化文件(ClickHouse)。
- 启动时,ClickHouse 读取
-
SQL 查看方式
-- 查看所有集群名称(含虚拟聚合) SHOW CLUSTERS; -- 查看 all-sharded 节点 SHOW CLUSTER 'all-sharded'; -- 查看 all-replicated 节点 SHOW CLUSTER 'all-replicated';其底层等同于:
SELECT * FROM system.clusters WHERE cluster = 'all-sharded' OR cluster = 'all-replicated'; ```:contentReference[oaicite:6]{index=6} -
表函数对照
cluster('all-sharded', db, table):针对每个分片执行一次,效果等同于all-sharded视图。clusterAllReplicas('all-replicated', db, table):针对每个副本执行一次,效果等同于all-replicated视图(ClickHouse)。
使用场景示例
| 场景 | 推荐虚拟集群 | SQL 示例 |
|---|---|---|
| 全量扫描、全节点聚合 | all-sharded | SELECT count(*) FROM cluster('all-sharded', system.parts); |
| 副本健康检查、比对 | all-replicated | SELECT hostName(), errors_count FROM system.clusters WHERE cluster='all-replicated'; |
| 分片级别写入(单副本) | 自定义 cluster | INSERT INTO my_table ON CLUSTER 'prod_cluster' VALUES (…) |
| 跨副本并行读、容错查询 | clusterAllReplicas | SELECT * FROM clusterAllReplicas('all-replicated', system.metrics) LIMIT 10; |
通过上述整合,可以清晰地理解:
all-sharded用于把“节点”看作分片,适合全扩散型查询;all-replicated用于把“节点”看作副本,适合副本比对和诊断;
并结合SHOW CLUSTER和表函数灵活运用,快速在 SQL 层面完成集群级别的运维与分析。
集群
下面先做一个简要概览,然后分三部分详细说明 ClickHouse 中的 Cluster(集群)概念:它是什么、有什么作用,以及如何配置和使用。
概览
在 ClickHouse 中,Cluster(集群)是指一组逻辑上关联的服务器节点(物理机或容器),通过配置文件中的<remote_servers>定义。系统在启动时会将这些定义加载到系统表system.clusters中,并自动生成两个虚拟聚合集群(all-sharded、all-replicated)。集群的主要作用包括:
- 数据分片与复制:支持按分片(Shard)水平拆分数据,并在每个分片内进行多副本(Replica)复制以保证高可用;
- 分布式查询:通过
Distributed表引擎或表函数(cluster()/clusterAllReplicas()),可将单表查询并行下推到所有节点;- 统一运维:使用
ON CLUSTER语句执行跨节点的 DDL 操作,如创建表、删除表、修改权限等。
一、Cluster 是什么?
1.1 配置文件中的 <remote_servers>
ClickHouse 的集群是通过配置文件(默认 /etc/clickhouse-server/config.xml 或 config.d/*.xml)中 <remote_servers> 节点明确定义的。一个典型示例如下:
<remote_servers>
<prod_cluster>
<shard>
<replica>
<host>node1.example.com</host>
<port>9000</port>
</replica>
<replica>
<host>node2.example.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>…</replica>
</shard>
</prod_cluster>
</remote_servers>
<prod_cluster>即为集群名称;- 每个
<shard>定义一组副本(Replica); - 该配置会被合并到
system.clusters系统表中,供 SQL 层和内部逻辑使用(ClickHouse)。
1.2 系统表 system.clusters
系统表 system.clusters 列出了所有通过 <remote_servers> 定义的集群条目,以及服务启动时自动添加的两个虚拟聚合集群:
all-sharded:将所有节点视为独立分片;all-replicated:将所有节点视为同一分片的多副本。
该表的主要字段包括:cluster、shard_num、replica_num、host_name、host_address、port、is_local 等(ClickHouse)。
二、Cluster 的作用
2.1 数据分片与复制
- 分片(Sharding):将数据按某种策略(如按键哈希、按时间范围)拆分到不同的分片,以实现水平扩展。
- 复制(Replication):使用
ReplicatedMergeTree等引擎在每个分片内部署多个副本,保证单点故障不影响可用性和数据安全(docs.altinity.com)。
2.2 分布式查询
-
Distributed 表引擎:在任意节点上创建
Distributed表,指定其ON CLUSTER <cluster>,后续对该表的<SELECT>会并行地在所有分片上执行,并合并结果。例如:CREATE TABLE dist_logs ON CLUSTER prod_cluster AS local_logs ENGINE = Distributed(prod_cluster, default, local_logs, rand());这样在查询时,ClickHouse 会根据负载均衡策略,将子查询下发到每个分片的一个副本上执行,再聚合返回(ClickHouse)。
-
表函数
cluster('prod_cluster', db, table):对每个分片的主副本(或负载最优副本)执行一次查询,等效于all-sharded视图;clusterAllReplicas('prod_cluster', db, table):对所有副本并行执行查询,等效于all-replicated视图(ClickHouse)。
2.3 跨节点 DDL
-
使用
ON CLUSTER关键字,能够一条语句在整个集群范围内同步执行 DDL。如:CREATE TABLE IF NOT EXISTS default.events ( … ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}/events', '{replica}') ORDER BY timestamp ON CLUSTER prod_cluster;该语句会在
prod_cluster定义的所有节点上,按照各节点的<macros>({cluster}、{replica})自动替换,创建相同结构的表(Altinity® Knowledge Base for ClickHouse®)。
三、如何使用 Cluster
3.1 配置集群
-
编辑配置文件
- 在
/etc/clickhouse-server/config.d/cluster.xml中定义<remote_servers>; - 在
/etc/clickhouse-server/config.d/macros.xml中为每台节点指定<cluster>、<shard>、<replica>宏,简化 DDL 替换。
- 在
-
重启服务
systemctl restart clickhouse-server修改
<remote_servers>和<macros>后,无需重启 ZooKeeper,但需重启 ClickHouse 服务以加载新配置(Altinity® Knowledge Base for ClickHouse®)。
3.2 查看集群信息
-
列出所有集群名称:
SHOW CLUSTERS; -
查看指定集群的节点列表:
SHOW CLUSTER 'prod_cluster'; -
查询系统表:
SELECT * FROM system.clusters WHERE cluster = 'prod_cluster'; ```:contentReference[oaicite:7]{index=7}
3.3 使用分布式表
-
创建本地表(每个节点上都要先建):
CREATE TABLE local.events ( id UInt64, timestamp DateTime, … ) ENGINE = MergeTree() ORDER BY timestamp; -
创建分布式表(只需在任一节点执行):
CREATE TABLE dist.events ENGINE = Distributed(prod_cluster, default, events, cityHash64(id)); -
查询与写入:
SELECT * FROM dist.events WHERE …:并行下推到所有分片;INSERT INTO dist.events VALUES (…):写入时采用路由函数决定写入到哪个分片中的哪一个副本。
通过以上配置与使用方式,ClickHouse 的 Cluster 概念既支持弹性水平扩展,又在高并发场景下提供高可用与跨节点的透明分布式查询能力。结合系统表、表引擎与表函数,能够灵活地管理和运维大规模 OLAP 集群。

















 3862
3862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









