



在现代交换机和路由器中,几乎每一个数据包的转发决策都需要通过“查表”来完成。而这些“表”的大小可以从几条规则增长到几万甚至几十万条。面对如此庞大的转发表,如何快速、高效地完成查找?这就是 TCAM 发挥作用的地方。
一、TCAM 是什么?
TCAM 的全称是 Ternary Content Addressable Memory,即“三级内容可寻址存储器”。
- Content Addressable:不是按地址访问,而是按“内容”查找;
- Ternary:支持三种状态 ——
0、1和X(即 Don’t Care,模糊匹配); - 通俗地说:你给出一个值,TCAM 帮你在所有规则中并行匹配,返回最先命中的那一条。
二、TCAM 与普通内存有什么不同?
| 比较维度 | 普通内存(如RAM) | TCAM |
|---|---|---|
| 查找方式 | 按地址读取 | 按内容查找 |
| 匹配能力 | 精确匹配 | 支持模糊匹配(X) |
| 匹配效率 | 一次只能查一条 | 所有规则并行查找 |
| 延迟 | 随规则数量增长 | 固定,1个时钟周期 |
| 应用领域 | 存储 | 匹配、分类、转发决策 |
三、TCAM 的实际作用:查表提速、保障线速转发
在交换机/路由器中,TCAM 主要用于下列几个核心任务:
1. 路由前缀匹配(Longest Prefix Match)
例如,查找 10.1.5.123 应转发到哪个下一跳:
路由表:
10.0.0.0/8 → 下一跳A
10.1.0.0/16 → 下一跳B
10.1.5.0/24 → 下一跳C
TCAM 会一次性并行比对所有前缀,并直接返回“最长匹配的那条” /24,实现高效路由查找。
2. ACL / QoS / PBR 等规则匹配
现代设备常配置成百上千条ACL、QoS分类、策略路由规则,依赖五元组(源/目IP、端口、协议等)组合匹配。TCAM 支持对这些字段进行并行模糊匹配,大幅减少判断时间。
3. 多字段复杂匹配场景
- 同时匹配 VLAN ID、DSCP、端口号、TCP标志位等多种条件;
- 是 SDN/OpenFlow 等新型转发模型中底层“flow table”的关键实现方式。
四、为什么 TCAM 查表速度极快?
本质原因:硬件电路并行阵列
- 每条规则都是一组电路实现;
- 所有规则组成矩阵结构;
- 报文字段输入后,所有电路同时启动匹配;
- 用一个优先级编码器返回第一个命中的规则。
所以不管你有10条还是10,000条规则,TCAM都能在1个时钟周期内完成查找,实现真正的线速处理。
五、TCAM 的局限性
虽然 TCAM 很快,但它并不是“无限强大”,主要存在以下几个问题:
| 限制 | 说明 |
|---|---|
| 容量小 | 每块TCAM芯片支持的规则条目有限(如2K~32K条) |
| 成本高 | 单位面积比普通内存贵几十倍 |
| 功耗大 | 每条匹配电路常通电,能耗明显 |
| 扩展难 | 想支持上百万条规则需多个芯片堆叠或更复杂架构 |
因此,在大型骨干网络设备中通常会堆叠多个TCAM芯片来提升处理能力,而在中小型设备或软件网关中,为节约成本可能根本不使用TCAM。
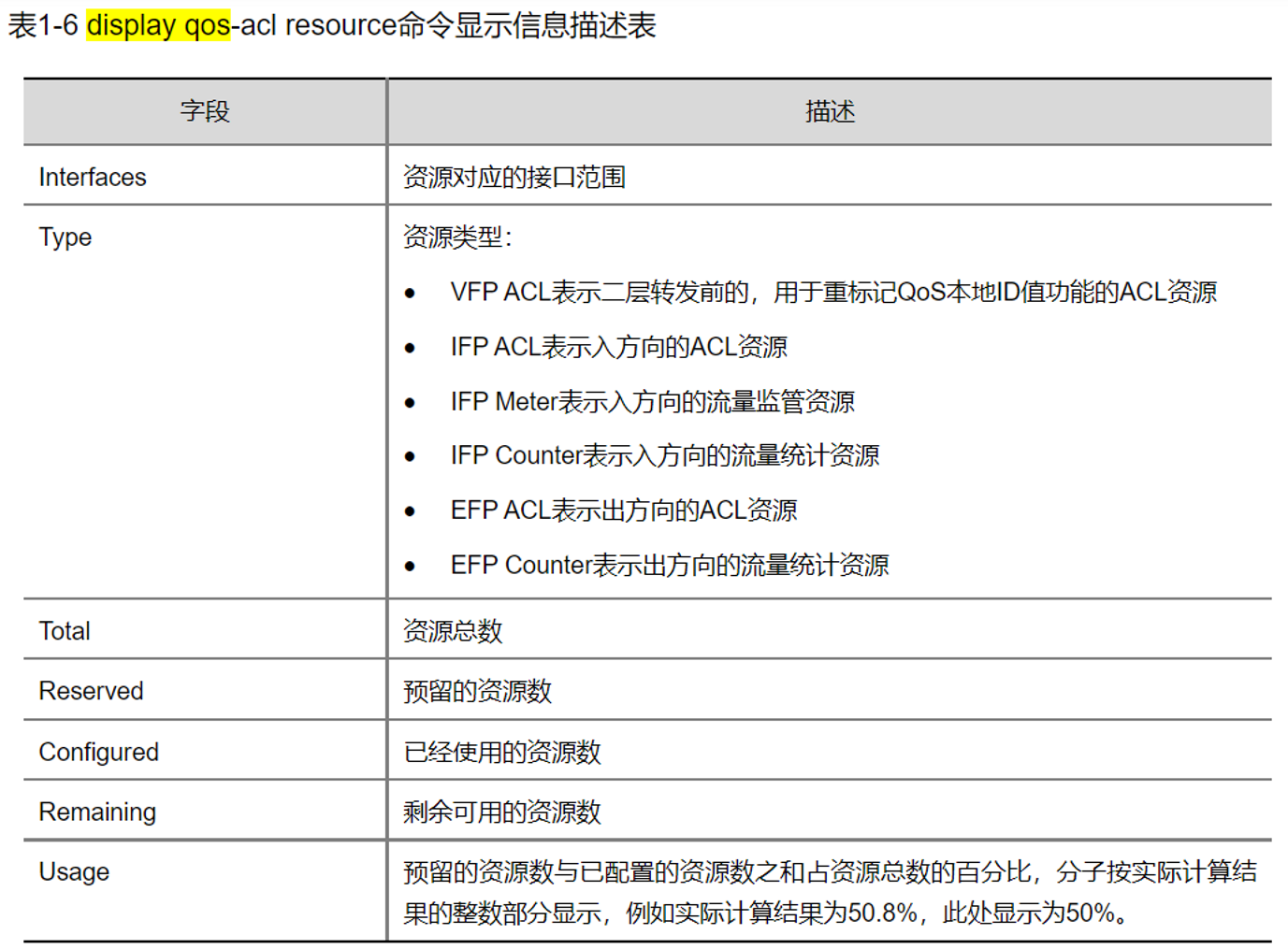
六、实际应用中的TCAM资源管理
设备厂商通常会提供TCAM资源使用情况的监控命令。例如在H3C设备中:
display qos-acl resource
总结
TCAM 就是交换机的“并行查表加速器”,它用硬件电路替代了CPU的逐条比对,实现了ACL、路由、QoS等核心策略的极速匹配。

















 3036
3036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









