







A Compact Embedding for Facial Expression Similarity
文章的主要贡献是提出了一个更贴近人的视觉偏好的简约空间,来描述面部表情。最后,得到一个16维度的特征。文章认为,表情的分布不是完全符合语义特征,For example, smiles can come in many subtle variations, from shy smiles, to nervous smiles, to laughter. Also,not every human-recognizable facial expression has a name.In general, the space of facial expressions can be viewed as a continuous, multi-dimensional space.
文章的主要思想是如果人类认为相对于第三种表情,另外两种表情在视觉上非常像,那么这两个表情在简约空间上的距离就会远远小于他们和第三种表情的距离。为了得到这个空间,作者创建了一个数据集,称为Facial Expression Comparison(FEC) dataset,下载地址:https://ai.google/tools/
datasets/google-facial-expression/
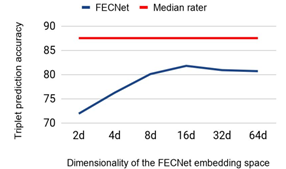
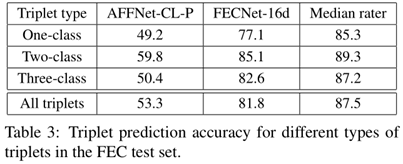
之后作者证明了这个16维度的表情空间可以使用深度网络得到,利用triplet loss.利用这个网络在验证集上得到了81.8%的正确率,而人类的平均值是87.5%,可以说是非常接近了。
1, Facial expression comparison dataset
作者自建的数据集,使用人类评价图片表情的是否属于一类,因为标签并不能说明同一类表情图片的相似程度,如下图 ,经常会出现分错的情况,总之这个数据集就是被早出来了。

数据集里的每一样本,包含三张图片和一个标签,L={1,2,3},1代表相比于图片1,2,3两张图片看起来更像,以此类推。数据集并没有指定anchor,但是提供了两个注释,I 2 is closer to I 3 than I 1 , and I 3 is closer to I 2 than I 1。下表给出了数据集的triplet的数量和包含的人脸的数量,数据集被分为两部分,90%作为训练,10%作为测试。

Each triplet in this dataset was annotated by six raters. For a triplet, we say that the raters agree strongly if at least two-thirds of them voted for the maximum-voted label, and agree weakly if there is a unique maximum-voted label and half of the raters voted for it. The number of such triplets for each type are shown in Table 1.Raters agree strongly for about 80% of the triplets suggesting that humans have a well-defined notion of visual expression similarity.
2, Facial expression embedding network
作者认为自己的数据集太小,所以使用预先训练好的FaceNet(参考FaceNet: A unified embedding for face recognition and clustering),use the NN2 version of pre-trained FaceNet up to the inception (4e) block whose output is a 7×7 feature map with 1024 channels。完整具体的网络图如下。

2.1 triplet loss function
For a triplet (I 1 ,I 2 ,I 3 ) with the most similar pair (I 1 ,I 2 ), the loss function is given by
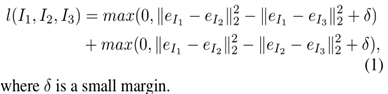
后文,作者把在FEC数据集上训练得到的网络称为FECNet.
3,实验
作者选择了在两种数据集上训练的网络AFFNet-CL(参考AffectNet: A database for facial expression, valence, and arousal computing in the wild),FACSNet-CL(参考DISFA: A spontaneous facial action intensity database),分别选取两种网络的最后一层和倒数第二层作为特征代表,
最终结果如下,
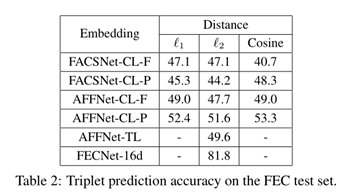
还说明为什么选择16维度作为最后结果,















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









