






一、KNN算法介绍:
KNN 算法,或者称 k最邻近算法,是 有监督学习 中的 分类算法 。它可以用于分类或回归问题,但它通常用作分类算法。
KNN (K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。
一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。
二、KNN核心思想
KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。该算法用 K 个最近邻来干什么呢?其实,KNN 的原理就是:当预测一个新样本的类别时,根据它距离最近的 K 个样本点是什么类别来判断该新样本属于哪个类别(多数投票)。
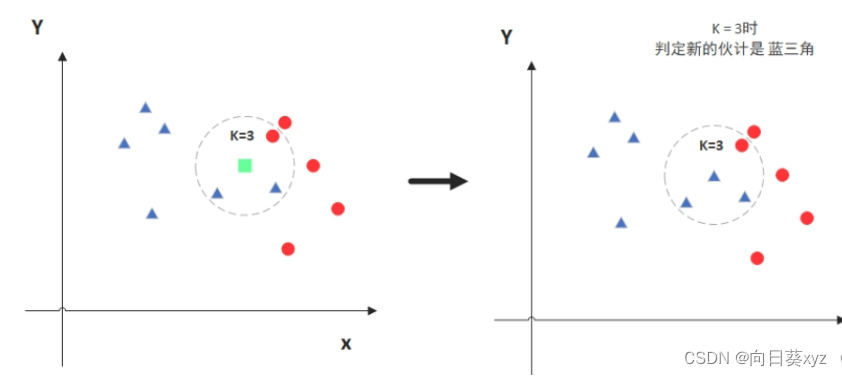
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
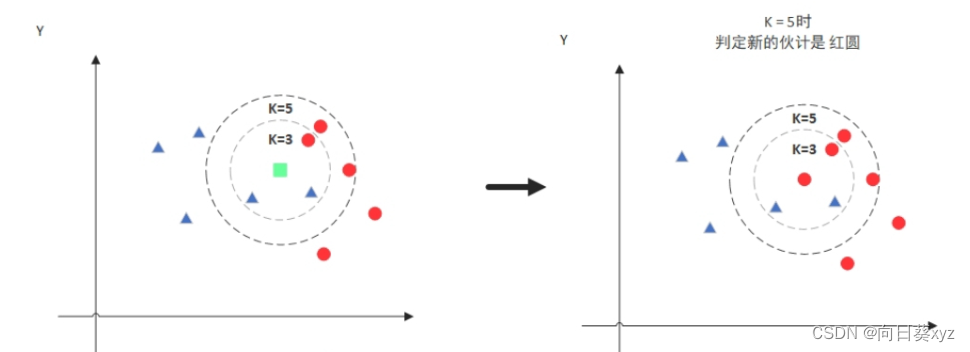
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
明白了大概原理后,我们就来说一说细节的东西吧,主要有两个,K值的选取和点距离的计算。
三、K值选择
通过上面那张图我们知道K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
通过交叉验证计算方差后你大致会得到下面这样的图:
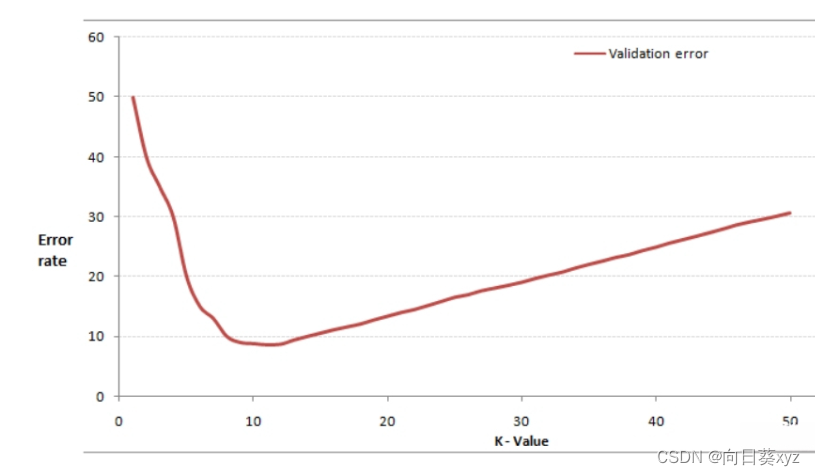
这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。具体如何得出K最佳值的代码,下一节的代码实例中会介绍。
四、 KNN算法的优势和劣势
了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在!
KNN算法优点
1、简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
2、模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
3、预测效果好。
4、对异常值不敏感
KNN算法缺点
1、对内存要求较高,因为该算法存储了所有训练数据
2、预测阶段可能很慢
3、对不相关的功能和数据规模敏感
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











