







目标的目标检测算法大都依赖于大量放置预定义的anchors,即使一些anchor free的算法也是通过gt内部的点来预测proposals。这样的通病是需要用nms处理大量的重叠框来达到dense to sparse的目的。那么,能不能有一个检测器直接暴力预测一个集合的candidate 然后对于这些candidate与gt进行一一匹配随后计算loss呢?
随着算力的提升,我们发现这样的做法是可以的。
下面便介绍set prediction 的一些论文:
- DETR
- Deformable DETR
- Sparse RCNN
DETR
这篇文章开始目标检测领域引入了transformer。

很简单的想法,就是把图像放进backbone中进行卷积 输出下采样的特征图 随后对这个特征图进行reshape处理,加上位置编码 便对所有的pixel level的feature进行自注意力机制的编码,将进行了encode后的feature再与初始化定义的object queries进行cross attention处理。对输出的query输送到检测头里面,对object进行检测。
文章检测出来的object显然是query数目的。那么对于得到的这些proposals我们便需要与GT进行一一的匹配。match过程作为一个函数进行优化 注意 首先我们需要对于GT进行一个补充
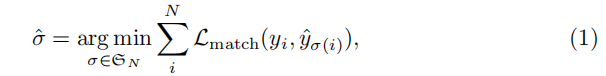
随后 我们便得到了一对一的proposal与GT 对他们我们计算Hungarian loss 即类似faster rcnn的loss计算
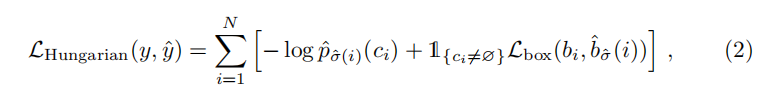
Deformable DETR
这篇文章是对于DETR的改进,作者认为DETR的训练过程是在是太漫长了 往往需要经过几百个epoch的训练才能收敛 这主要是因为DETR计算了特征图上每一个点与其他点的关系,这样的计算是冗余的。其次DETR对于小目标的减小效果也不太好 这是很容易理解 因为相比之前的检测网络都是用了FPN的 这里只用一层feature map 显然不是对所有尺寸的目标都能有很好的检测效果的。本文就是从这个目标出发的。
这篇文章 作者用了变形卷积

对于feature map上每一个pixel 我们计算它的偏移量 偏移到的feature pixel 我们把它们作为transformer 的value 进行编码 他们的权重也是有query经过一个linear加softmax层来进行计算得到的。
这样 我们的计算量便大大减少 使得每个feature map上的pixel仅仅与经过计算的偏移点相关。
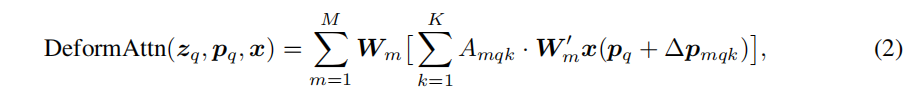
针对不同scale的feature map 我们还计算了分scale的feature
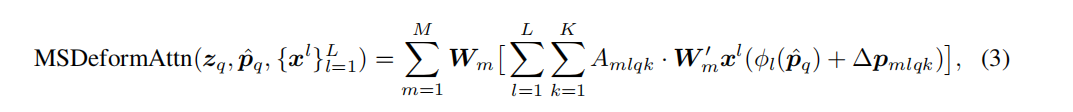
decode则是用初始化的object query与经过自编码后的多层的feature map进行cross attention。
decode中每一层的query是经过上一层编码refine后的query

这里的loss计算也是类似DETR的set to set形式 没有后续的nms处理。
Sparse RCNN
这便是一个更加简单的网络
backbone用的是resnet 生成特征图后 作者提出了可学习的proposal box 用4个0-1之间的数来代表这个box 和可学习的box feature 256维度的一个向量 开始都是对他们进行一个初始化

对于选择box对应特征图上的roi特征 我们采用roi align的操作,首先对于预义的feature我们直接进行self attention处理后 分别于roi align选择出来的feature进行iteract,操作细节如下:

输出obj维度的feature 并利用他输入到head中预测box 把box作为可学习的box 进行下一轮的迭代。
这样我们预测出数目大小是预定义的box 同样进行一个set to set的loss 计算。
















 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









