










SVM支持向量机进行分类与回归操作:
【机器学习】使用scikitLearn进行SVM支持向量机线性分类
【机器学习】使用scikitLearn进行SVM支持向量机进行回归
一、添加多项式特征
对于非线性可分的数据集,线性SVM分类器需要添加跟多的特征,常见的有先经多项式特征处理:
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline([
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge", random_state=42))
])
polynomial_svm_clf.fit(X, y)
前面提到过,对于高阶多项式特征添加,时间复杂度是阶乘级增加的。
为解决这一问题,SVM有核技巧,通过数学变换,达到跟添加多项式特征近似的效果,同时避免了复杂度激增:
下面的代码使用了多项式核:
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
])
poly_kernel_svm_clf.fit(X, y)
其中参数的意义见下表:

一般而言,采用网格搜索的方式,确定核函数中的各项参数。
二、添加相似特征
采用高斯径向基函数(RBF)作为相似函数,计算相似特征替代原特征,再以新特征进行分类。
这种方法的特点是,先选地标,一般将每个原实例设为一个地标,这样原先m个实例变成m个地标,每个地标变成转换后的一个新特征,即新数据实例集转换为m个特征。
时间开销较大,比较适用于待分类数据集实例数小于特征数的情况。
代码如下:
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
])
rbf_kernel_svm_clf.fit(X, y)
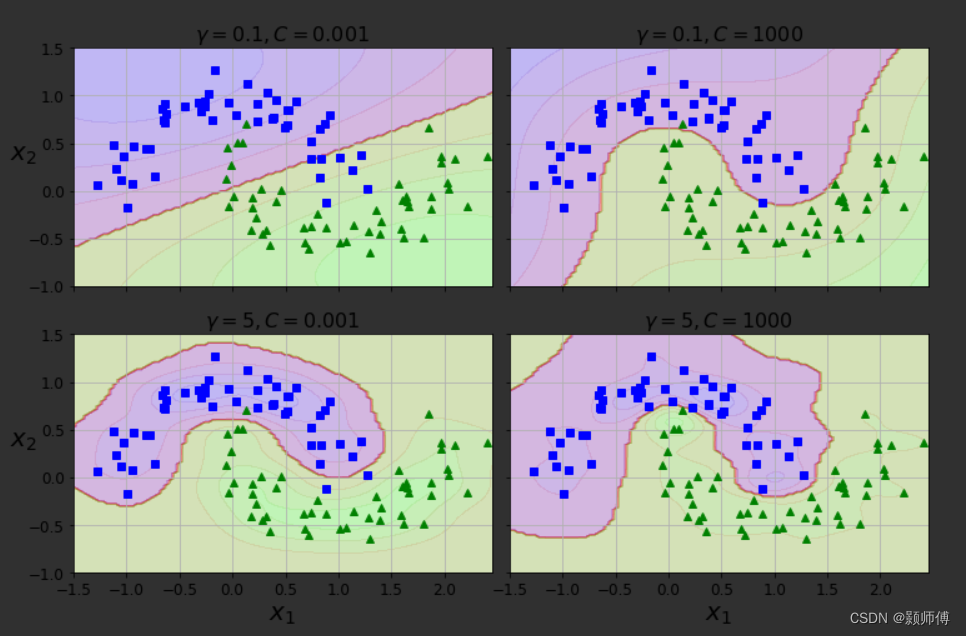
如图gamma 和 C 越小,其分类器泛化程度越好。越高则倾向于过拟合。
(gamma值使高斯函数钟形曲线越债,影响同单个实例越紧密)
实际上,核函数有很多,不同核函数可以适应不同领域的数据集,一般从线性核函数开始进行尝试,LinearSVC比SVC(kernel=“linear”)快得多。
liblinear库为线性SVM实现了一个优化算法,LinearSVC正是基于该库的。该算法不支持核技巧,不过它与训练实例的数量和特征数量几乎呈线性相关:其训练时间复杂度大致为O(m×n)。


















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











