










数据降维:投影及流形学习降维方法
【机器学习】使用scikitLearn对数据进行降维处理:PCA法及增量训练
【机器学习】使用scikitLearn对数据进行降维处理:KPCA法及参数选择
流形的概念:流形是n维空间中的一部分,类似于低维超平面。(如2维曲面在3维空间中卷曲,2维曲面的局部,可以视为是2维的。
基本假设流形学习认为大部分数据集都是高维空间中的低维流形。
其思路为,取某实例点附近的若干点,将该实例点做若干点的线性表示,然后寻找可以最好地保留这些局部关系的低维表示形式。
流形学习中,具有代表性的是局部线性嵌入LLE。
其基本代码如下:
from sklearn.manifold import LocallyLinearEmbedding
#选取了实例周围10个邻域去表示该实例:
lle = LocallyLinearEmbedding(n_components=2, n_neighbors=10, random_state=42)
X_reduced = lle.fit_transform(X)
下面介绍原理:算法的约束条件如下图所示:
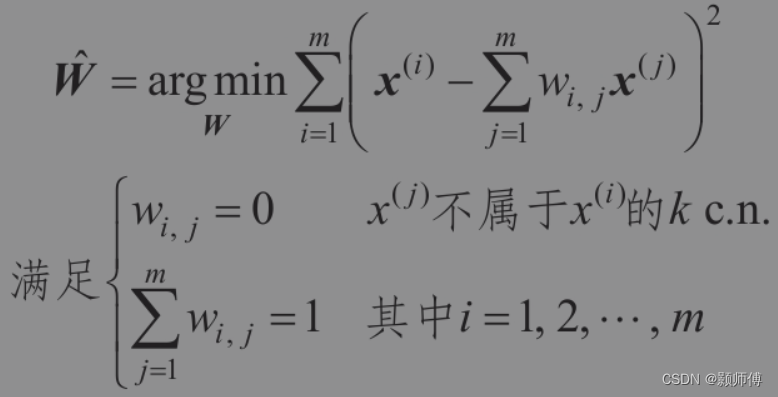
首先,第一个约束确保线性表示的误差尽可能小;第二个约束确保线性表示的权重加和为1.
然后使用下式,下式中z为降维后x对应的实例,该式的精神是固定线性表示的权重,寻找新实例z的最佳位置。
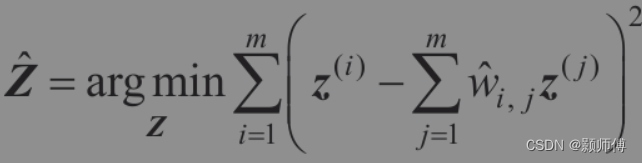
注意,对于非常大的数据集,其时间长度有一个实例数的2次方项,LLE难以适用。
PCA的最大特点是可以消除远数据中无用的维度,这是因为PCA是稀疏假设,如果原数据集无用的维度很少,降维会造成较高的信息损失。但是PCA运算非常迅速。为了在大数据时加速LLE的运算,可以连接PCA及LLE:
使用PCA快速去除大量无用的维度,然后应用LLE,以达到提升速度的效果。
其它scikitLearn中常用的降维方法:
降低维度的同时,能够保留实例间的相对距离:
from sklearn.manifold import MDS
mds = MDS(n_components=2, random_state=42)
X_reduced_mds = mds.fit_transform(X)
图方法,同样是保留实例间距离:
from sklearn.manifold import Isomap
isomap = Isomap(n_components=2)
X_reduced_isomap = isomap.fit_transform(X)
t分布随机近邻嵌入,该方法无法逆转降维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_reduced_tsne = tsne.fit_transform(X)
线性判别分析(LDA)
LDA的一个非常大的好处是,最适用于做分类问题的预处理步骤,它使不同的类之间的距离保持尽可能的远。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
X_mnist = mnist["data"]
y_mnist = mnist["target"]
lda.fit(X_mnist, y_mnist)
X_reduced_lda = lda.transform(X_mnist)
















 6261
6261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











