







WDSR是18年比较新的模型,现在又对应的官方pytorch版本,其链接为:https://github.com/JiahuiYu/wdsr_ntire2018
WDSR(2018年冠军模型)
模型架构
主要由于目前使用的结构要么是丢失掉了浅层的信息,比如上述提到的网络,通过各种激活函数,当浅层信息传递到最后时已经丢失了;要么就是采用跳跃链接的方式比如SRDenseNet,此时虽然浅层信息通过连接传到了后面,但是结构相对较复杂。所以为了解决这个问题,作者提出了WDSR网络模型。
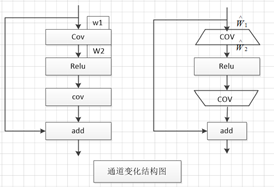
在介绍该方法之前首先介绍一个概念即:恒等映射(identity mapping pathway)。意思也就是在不增加参数的情况下扩大激活层的输入通道数,其具体结构如下图(通道变化结构图)。假设W1表示卷积的输入通道,W2表示卷积的输出通道也就是Relu函数使用时的输入。现在我们假设![]() ,其中r表示通道需要扩大的倍数。则对于EDSR中使用的激活(左边的图),其需要的参数为:
,其中r表示通道需要扩大的倍数。则对于EDSR中使用的激活(左边的图),其需要的参数为:![]() ,此时相当于r=1。对于右边的计算方式此时需要的参数量为:
,此时相当于r=1。对于右边的计算方式此时需要的参数量为:![]() 。k表示卷积核。要保证参数量不增加则有
。k表示卷积核。要保证参数量不增加则有![]() ,对应的
,对应的![]() 。由上述过程可以看出,此时Relu的输入通道数比原来扩大了
。由上述过程可以看出,此时Relu的输入通道数比原来扩大了![]() 倍,而对应总的参数量并没有增加。
倍,而对应总的参数量并没有增加。
根据上述思想,作者在不改变原有参数量的情况下(因为改变原有参数量意味着计算的复杂度增加,其对应的性能消耗更大),在Relu激活之前对整个通道数进行了扩张,促使更多的低层次信息可以通过以达到尽可能将低层信息传递到后面的目的。根据上述激活策略,并将其运用在Residual Block中就行成了本文使用的激活结构。具体如下:
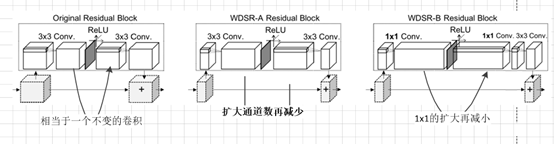
本文采用的主要是WDSR-A和WDSR-B两种结构。对于WDSR-A而言,相当于只是使用3X3的卷积先对通道数进行增大,再使用激活函数,接着使用3X3的卷积对通道数进行缩小,这种结构主要针对的是扩大倍数较小的情况(的取值在2到4之间)。对于取值较大时,该方式就不在适用了。主要是此时随着r的增大![]() 就会变的很小,而最终输出的通道数是和
就会变的很小,而最终输出的通道数是和![]() 相关的,就有可能出现其值小于
相关的,就有可能出现其值小于![]() 的情况。
的情况。![]() 表示的是使用亚像素卷积扩大倍时,重排之前需要的通道数。所以此时又提出了WDSR-B的结构。可以看出WDSR-B是采用1X1的卷积核进行通道数的改变,再使用3X3的卷积核进行特征提取。
表示的是使用亚像素卷积扩大倍时,重排之前需要的通道数。所以此时又提出了WDSR-B的结构。可以看出WDSR-B是采用1X1的卷积核进行通道数的改变,再使用3X3的卷积核进行特征提取。
采用上述Residual Block结构,作者在EDSR的基础上构建出了对应的WDSR模型,其具体结构如下:
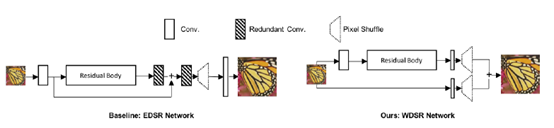
由上述结构可以看出,WDSR基本的框架和EDSR一样,除了采用上述提到的Residual Block中的激活结构之外,作者还认为EDSR在残差块之后的两个线性卷积(只是卷积没有激活相当于是线性变换)是可以被Residual Block吸收的,所以可以去掉并且在输入和输出时直接采用5X5的卷积进行计算。
除了上述改变之外,作者还在整个网络中采用了权值归一化的操作。作者通过实验发现如果加上BN会影响模型的性能(如EDSR去掉BN的原因一样),但是如果直接去掉BN当模型达到一定的深度(180层)时,其训练起来又比较困难,因此提出了权值归一化操作,该操作能够更好提高模型的准确度。其目的是为了在网络中重新计算网络的分布,其公式为:![]() ,w表示权重,g表示一个系数,v是一个维的向量,具体怎么来的还不详。最后整个网络也是采用了亚像素卷积的方法来扩大倍数以达到增加分辨率的目的。
,w表示权重,g表示一个系数,v是一个维的向量,具体怎么来的还不详。最后整个网络也是采用了亚像素卷积的方法来扩大倍数以达到增加分辨率的目的。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









