





在地球物理学中应用 DL 的最直接方法是将地球物理任务转移到计算机视觉任务,例如去噪或分类。然而,在某些地球物理应用中,地球物理任务或数据的特征与计算机视觉的特征有很大不同。例如,在地球物理学中,我们拥有大规模高维数据,但标注的标签较少。
1 勘探地球物理
地震勘探的主要过程包括地震数据的采样和处理(去噪、插值等)、反演(偏移、成像等)和解释(断层检测、相分类等)其中断层检测为根据你的地震剖面判断哪个地方有断层,因为断层附近的区域可能有油气藏等;相分类:就是炮记录经过一系列地震数据处理流程(去噪,滤波,偏移成像等等)得到的能大致反映地下地层分布状况的一个剖面,如图:
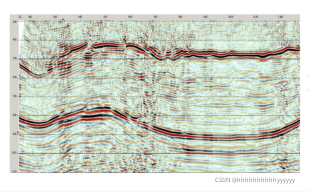
具有某些特征的地质现象就叫做相。在地质上,有很多种不同的相,河流相、沉积相等等,都是由于不同的地质年代、气候条件生成的,可以根据地震剖面来判断地下某一个位置曾经是什么相,这种能表明一种地质相的地震剖面的特征称为一种地震相。
1.1地震数据处理
地震数据受到不同类型噪声的污染,例如来自背景的随机噪声、沿地表以高能量传播并掩盖有用信号的地滚波,以及在界面之间多次反射的多次噪声。传统方法使用手工滤波器或正则化通过分析相应的特征来对某些类型的噪声进行去噪。然而,当信号和噪声共享一个共同的特征空间时,手工制作的滤波器就会不起作用。
DL 方法在用于地震去噪时避免特征选择。使用 DnCNN,一种用于去噪的 CNN,只要构建相应的训练集,相同的架构就可以用于三种地震噪声,同时实现高信噪比 。然而,还有很长的路要走。在合成数据集上训练的 DNN 对现场数据没有很好的泛化能力。 为了使网络可重用,迁移学习可用于现场数据去噪。 但有时难以获得干净数据的标签,一种解决方案是使用用户生成的白噪声进行多次试验来模拟真实的白噪声。
由于环境或经济的限制,地震检波器在奈奎斯特采样原理下通常不规则或不够密集。将地震数据重建或正则化为密集且规则的网格对于提高反演分辨率至关重要。我们可以从自然图像数据集中形成训练数据来训练 DnCNN,然后将其嵌入到传统项目中的凸集框架中。由此产生的插值算法可以很好地推广到现场地震数据。
首先,端对端的深度学习的成像方法输入为记录数据,使用速度模型作为输出,这提供了一种完全不同的成像方法。 DL 方法避免了上述瓶颈。 DL 在 staking、断层扫描和 FWI中首次在合成 2D 数据上尝试,显示出有希望的结果。然而,端对端 DL 成像也有缺点,例如缺乏训练样本和由于内存限制而限制输入的大小。
为了使基于 DL 的成像适用于大规模输入,更多的工作旨在与传统方法合作并解决上述瓶颈之一。
1.2地震资料成像
地震成像是一个具有挑战性的问题,因为断层扫描和全波形成像 (FWI) 等传统方法存在几个瓶颈: 1. 由于维数灾难,成像很耗时。 2. 成像在很大程度上依赖于人机交互来选择合适的速度。 3. 非线性优化需要良好的初始化或低频信息,但记录数据中缺乏低频能量。 DL 方法有助于从多个角度缓解瓶颈。
首先,端对端的DL的成像方法输入为记录数据,输出为速度,这提供了一种完全不同(之前需要去噪、插值等再反演速度)的成像方法。但去噪等后使用 DL 效果更好。 DL 方法避免了上述瓶颈,提供了下一代成像方法。然而,端对端 DL 成像也有缺点,例如缺乏训练样本和由于内存限制而限制输入的大小。U-Net 用于从不同维度的不同空间进行迁移,在训练 DNN 时使用下采样(将在文末介绍)来减少参数。
为了使基于 DL 的成像适用于大规模输入,更多的工作旨在与传统方法合作并解决上述瓶颈。
2 深度学习在地球物理学的未来趋势方向
第一次尝试是从简单的 FCNN开始,然后是复杂的网络,例如 CNN、RNN 和 GAN。关于训练集,早期的工作使用了从计算机视觉领域借鉴来的端对端训练,这需要大量带注释的标签,而最近的工作开始考虑无监督学习和DL 与物理模型的结合。 2020 年,更多的工作集中在 DL 方法的不确定性(文末介绍)上。
尽管DL在一些地球物理应用中取得了成功,例如地震探测器或采集器,但把它们作为大多数实际地球物理学的工具仍处于起步阶段。主要问题有训练样本不足、信噪比低、强非线性(需要去构造)。与其他行业相比关键的挑战是,地球物理应用中缺乏训练样本。已经提出了几种与这一挑战相关的高级 DL 方法,例如半监督和无监督学习、迁移学习、多模态 DL、联邦学习和主动学习。
2.1半监督和无监督学习
实际地球物理应用中,获取大型数据集的标签非常耗时,甚至不可行。因此,需要半监督或无监督的学习来减轻对标签的依赖。通常,我们必须为特定数据集和特定任务训练一个 DNN。例如,DNN 可以有效处理陆地数据但不能有效处理海洋数据。
2.2迁移学习
通常,我们必须为特定数据集和特定任务训练一个 DNN。例如,DNN 可以有效处理陆地数据但不能有效处理海洋数据。建议通过使用迁移学习来提高网络对不同数据集或不同任务的可重用性。
2.3 深度学习与传统方法的结合
2.4多模态深度学习
2.5联邦学习
输入来自不同来源的数据,例如地震数据和重力数据。从不同来源收集数据有助于缓解训练样本数量有限的瓶颈。
2.6 不确定性估计
2.7主动学习
主动学习模型根据手动标注的采样策略选择最有用的数据,并将这些数据添加到训练集中;然后,更新后的数据集用于下一轮训练。
附录:
① 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。对图像的缩放操作并不能带来更多关于该图像的信息, 因此图像的质量将不可避免地受到影响。然而,确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量的。
下采样原理:对于一幅图像I尺寸为M*N,对其进行s倍下采样,即得到(M/s)*(N/s)尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值:
上采样原理:图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
(下上采样原文链接:https://blog.csdn.net/stf1065716904/article/details/78450997)
② 模型不确定性包括偶然不确定性和认知不确定性两种
偶然不确定性又称为数据不确定性,是由于观测数据中的噪声产生的,通过获取更多的观测数据是无法降低偶然不确定性的,降低偶然不确定性的可行办法主要包括提高观测精度和对观测数据进行降噪处理两种
认知不确定性又称为模型不确定性,是由于模型参数的不确定性、模型结构的不确定性产生的,通过增加训练数据的数量可以一定程度上降低认知不确定性。认知不确定性是预测不确定性的主要来源,对预测结果的影响最大。
(链接:https://www.zhihu.com/question/431505006/answer/1593313356)

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









