







文章目录
Info
本文首发于公众号:code路漫漫,欢迎关注
官方代码:https://github.com/SamHaoYuan/DSANForAAAI2021
思维导图地址:https://github.com/hhmy27/MyNotes

这篇文章是 AAAI21 的文章
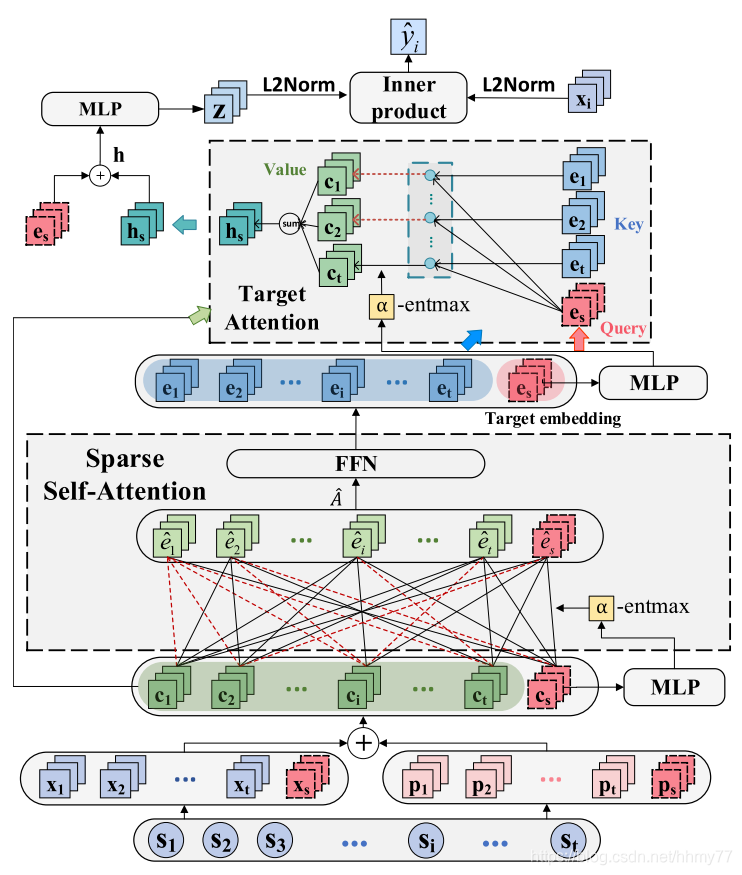
模型图
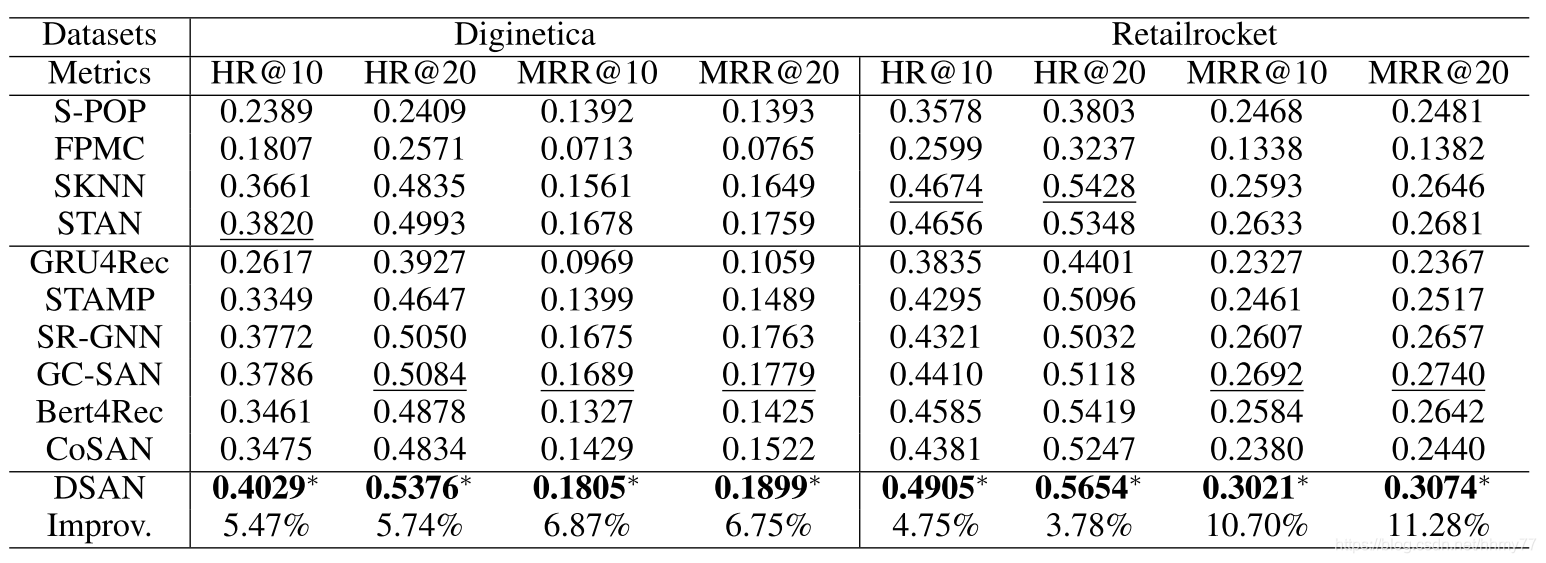
实验结果
1 Motivation
作者提了两个问题
- 以往工作直接用 last click item embedding 用来表示 current preference 不妥
- session 中所有的 item 并不一定能反映用户偏好,有些交互可能是因为误触、浏览无关的促销广告等行为产生的
对于 1,例子如下
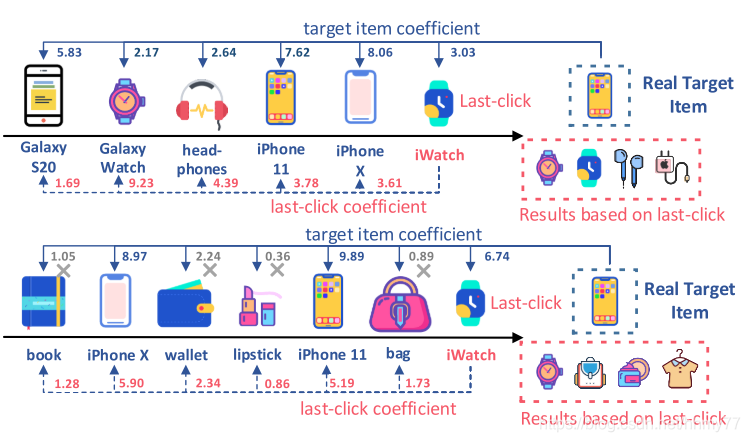
例子中使用最后一个 item 预测的物品集合里面不存在真实的 target item
两个问题都是很直观的问题,下面看看它怎么解决的
解决方法:
- 论文提出了一个可学习的 embedding 用来刻画用户的 current preference,称为 target embedding
- 论文引入了 alpha-entmax 函数,其中 alpha 也是可习得的参数,用来消除小权重 item 的影响。考虑到小权重 item 的语义正是那些不能反映用户偏好的 item。
2 Contribution
- 提出了 DSAN 这个新框架,它由 self-attention 和 vanilla attention 组成。通过 item-level collaborative information 学习 target embedding ,使用不同的 query, key and value 向量作为高阶信息去建模session推荐
- 引入基于上下文的 adaptively sparse attention mechanism 去寻找 session 中可能无关的 item,保留高权重给有关 item
- 实验表示达到了最优的效果
3 Solution
论文里面细节比较多,这里先简单概括一下怎么做的,写一下用到的 embedding 符号,后面再细说具体做法
首先论文引入了两个 attention 机制,第一个称为 Sparse Attention Network,第二个是 Vanilla Attention Network,两个 attention network 是串联机制,最终产生 session 的 embedding 和 current preference embedding(论文中称为 target embedding)。
这里产生的 session embedding 是考虑到 current preference embedding 的,以往工作大多都直接对 item 进行 embeedding,然后再聚合得到 session 的 embedding。而这篇文章在计算 session embedding 的过程中加入了 current preference embedding,同时训练两个 embedding
得到 session embedding 之后,我们将它和原始的 item embedding 结合起来,进行预测,即可得到结果
具体而言,生成 session embedding 的步骤如下
-
把 input session 转换成两个向量,一个是 item embedding,另一个是 positional embedding,存储着 item 的位置信息

-
把 item embedding 和 positional embedding 结合起来,得到每个 item 的表示,此时属于预处理部分,没有输入到网络中
需要注意的是,这里有一个红色的 Cs,它是我们要计算的 target embedding,能够反应 current preference embedding -
输入第一个 att,得到 item-level 的信息
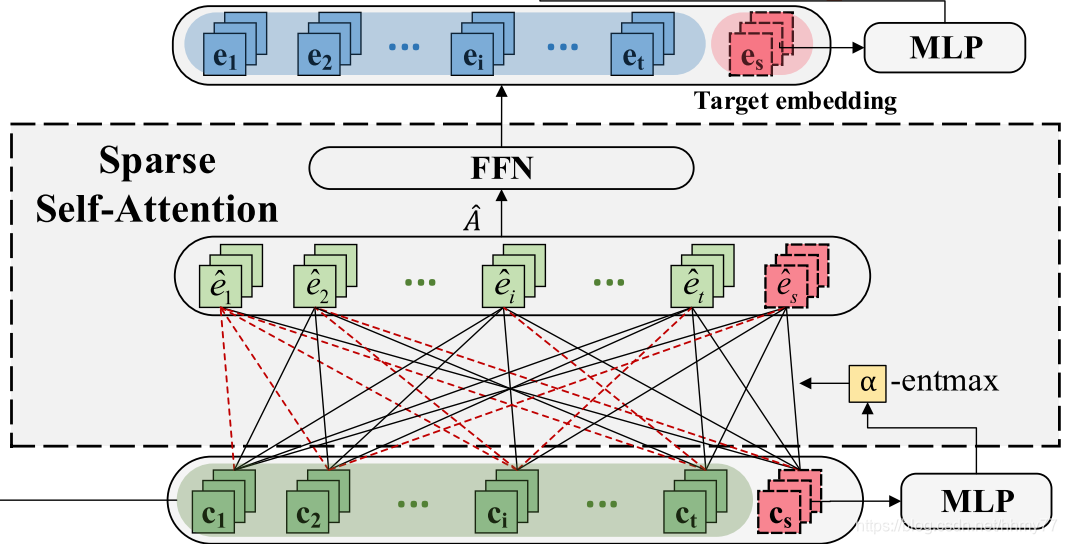
-
继续输入第二个 att,最终通过聚合得到 session 的表示 hs(是一个值)
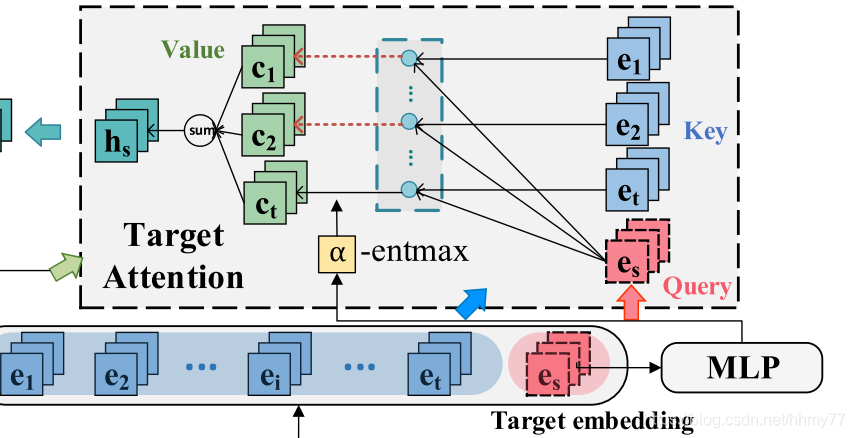
-
进一步结合 target embedding 聚合信息
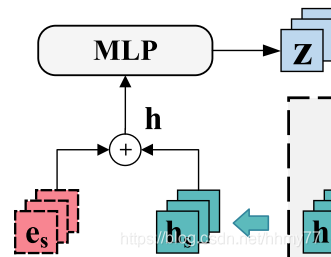
-
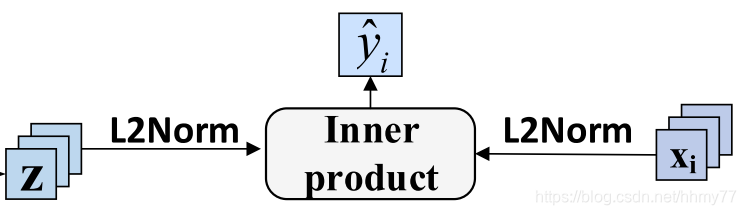
进行预测
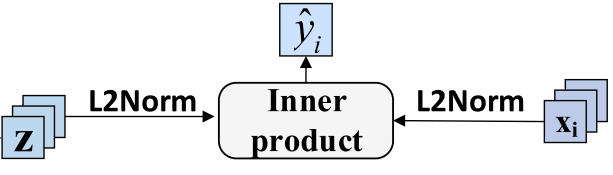
下图总结了流程中出现的符号以及意义
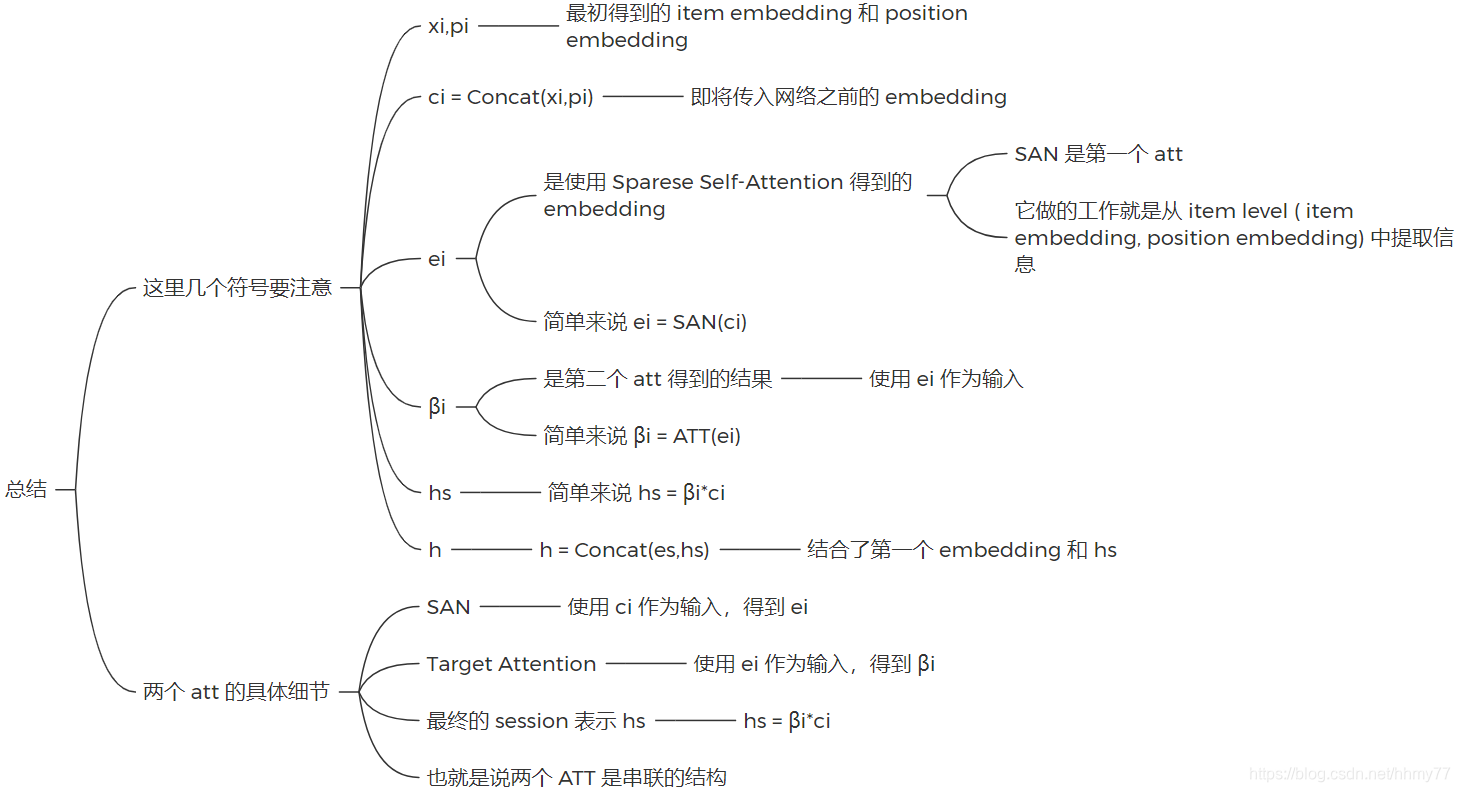
文章中session embedding 的构造还是挺复杂的。。
下面我们分步骤来看
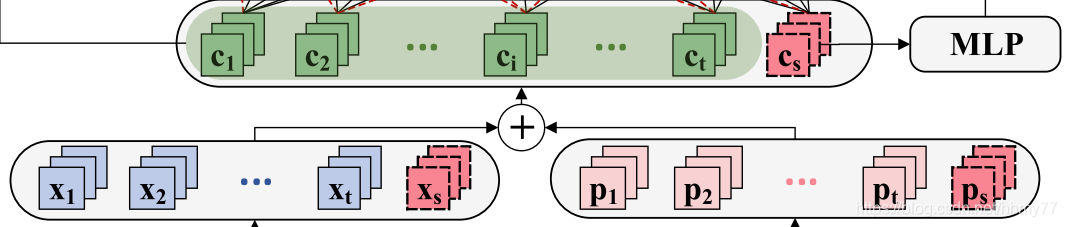
3.1 初步 embedding
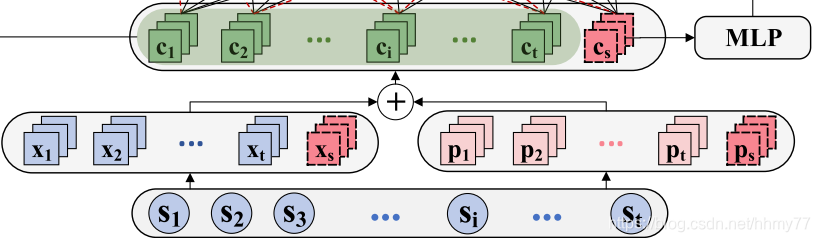

生成两个 embedding,xi 和 pi,然后结合起来得到 ci
c i = C o n c a t ( x i , p i ) ci = Concat(xi, pi) ci=Concat(xi,pi)
3.2 Target embedding learning
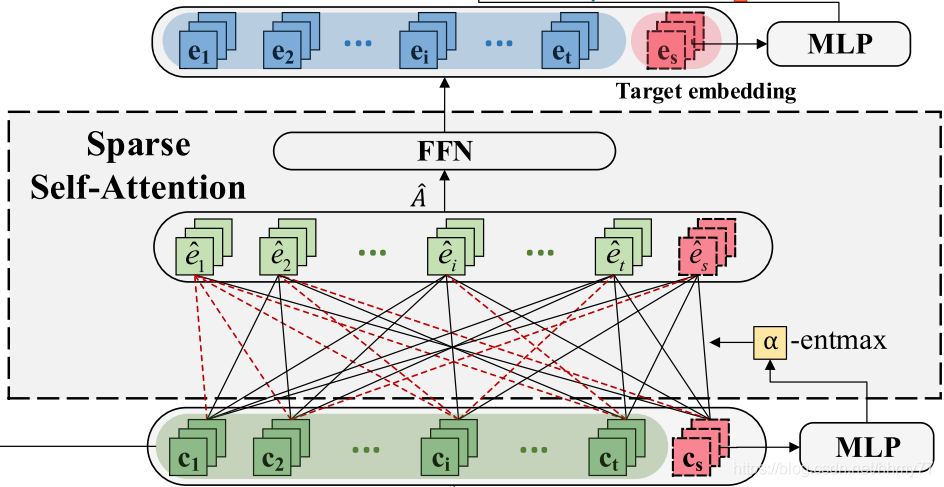
传入第一个 att,计算 target embedding 和初步的 session embedding

计算公式就不细说了,就是传统的 attention 机制运用方法
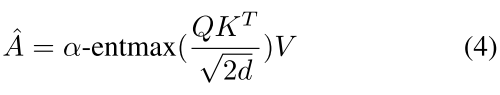
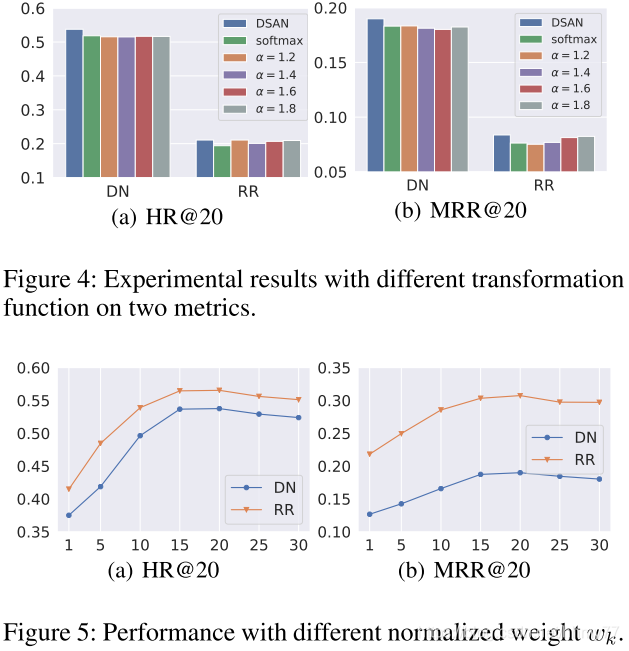
值得注意的是,这里出现的 alpha-entmax 替代了传统的 softmax,观察它的图像我们可以知道,alpha 越大,较小的权重将越有可能直接标记为0
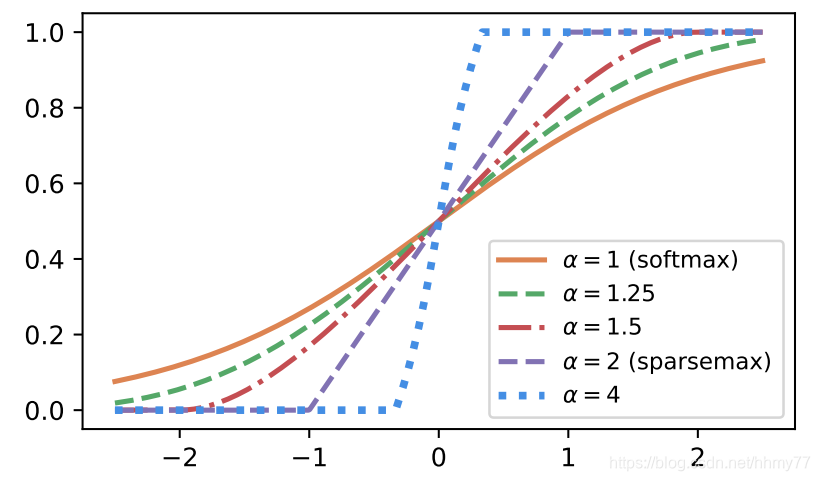
同时 alpha 这个参数也是通过 MLP 习得的
最终结果:

其中
E
=
{
e
1
,
e
2
,
.
.
.
,
e
t
,
e
s
}
E = \{e_1,e_2,...,e_t,e_s\}
E={e1,e2,...,et,es}
3.3 学习进一步的 session 表示
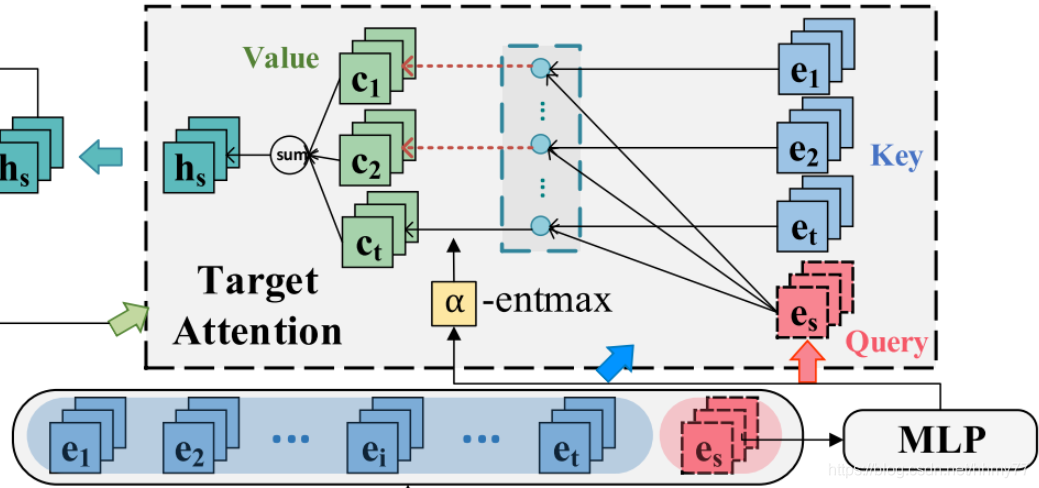
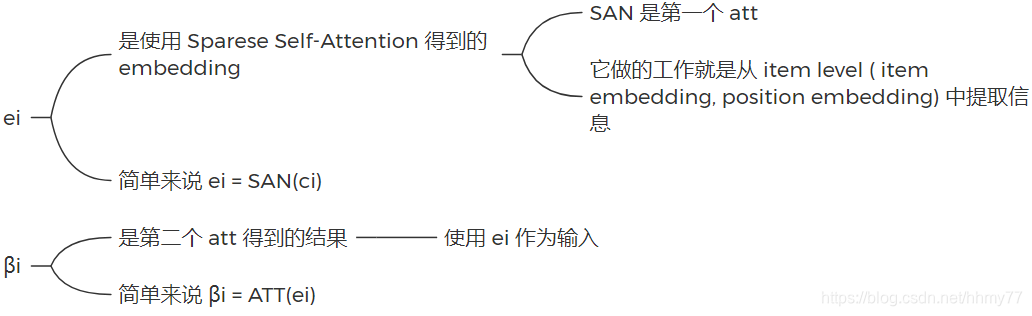
首先按公式 9 计算 β,即权重,图中没有画出来
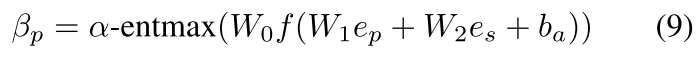
alpha 同样是计算得出
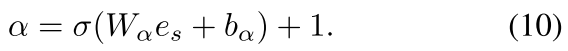
然后按照 h s = ∑ p = 1 β p c p h_s = \sum_{p=1} \beta_pc_p hs=∑p=1βpcp 聚合得到 session 的表示
3.4 聚合信息并进行预测
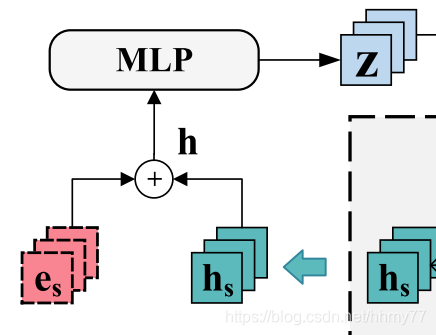
这一步我有一个疑问,h_s 生成过程中已经使用了 e_s,为什么还要再聚合一遍?感觉挺奇怪的
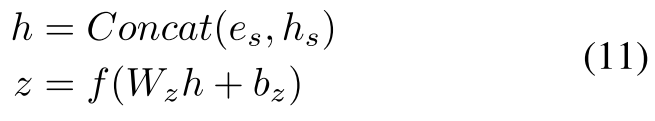
z 表示模型的最后输出

这一步还要各自正则化后做点积,得到预测分数
目标函数选择交叉熵
4 Evaluation
由于官方放出了 code,这一步就不细说了,我们直接看结果

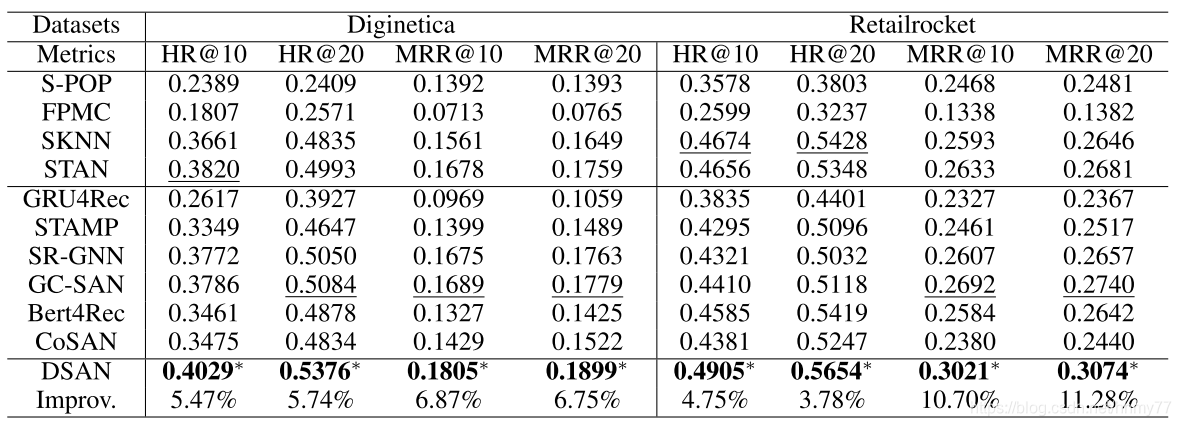
消融实验部分:
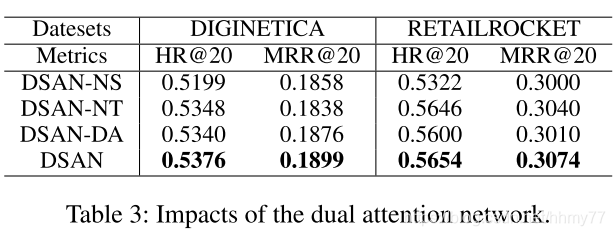
三个变形
- DSAN-NS
没有 target embedding - DSAN-NT
没有 target attention layer - DSAN-DA
把两个 att 变成平行结构而不是顺序结构,同时没有 target embedding
超参部分:
5 Summarization
回顾提出的两个问题:
- 以往工作直接用 last click item embedding 用来表示 current preference 不妥
- session 中所有的 item 并不一定能反映用户偏好,有些交互可能是因为误触、浏览无关的促销广告等行为产生的
解决方法:
- 学习 target embedding
- 使用 alpha-entmax
个人感觉
既然表示的是 current preference,应当用末尾的几个物品来综合考虑,论文直接使用所有 item 的 embedding 学习 target embedding,从语义上来说,不是和 global preference 撞车了吗,感觉这方面还可以再改进下
另外学习 target embedding 的过程又训练了 session embedding,得到 session embedding 之后又和原始的 item embedding 进行聚合,文中也没有解释,给人一种 “是实验显示这么处理效果好所以要这么做” 的感觉
使用 alpha-entmax 是 make sense 的
论文提出了将来的研究方向:
In the Future work, we plan to explore the way of using automated machine learning to delete the unrelated item in the session before entering into the network, so that the model can learn more useful information.















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









