







作者提出动量对比度(MoCo)用于无监督的视觉表示学习。从作为字典查找的对比学习[29]的角度来看,作者构建了一个带有队列和移动平均编码器的动态字典。这样就可以动态地构建大型且一致的词典,从而促进对比性的无监督学习。MoCo在ImageNet分类的通用线性协议下提供了竞争性的结果。更重要的是,MoCo学习到的表示将转移到下游任务。 MoCo可以胜过在PASCAL VOC,COCO和其他数据集上进行监督的预训练对等任务中的7个检测/细分任务,有时会大大超过它。这表明,在许多视觉任务中,无监督和有监督的表征学习之间的鸿沟已被缩小。
MoCo模型原理与早些年Google的FaceNet(用作人脸比对的模型非常相似),训练学习过程中,尽量让当前图片与其他图片的特征距离拉大。
网络结构如图:
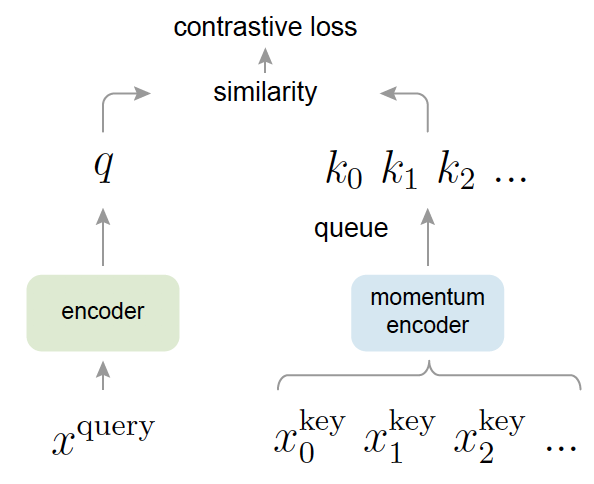
实际上模型分为encoder与momentum encoder两部分,与end to end和memory bank模型不同,MoCo在训练过程中,梯度反向传播只更新encoder,momentum encoder实际上是encoder经过ExponentialMovingAverage操作时的shadow。如图:

ExponentialMovingAverage,这种更新方式,按比例m更新历史权重,通常m是一个接近1的小数,论文里取0.9999计算公式:
![]()
Loss计算公式:
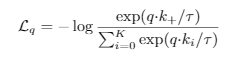
整个训练流程伪代码如下:

训练流程:
- 将图片经过两次不同的图片增强,分别传入f_q(encoder)与f_k(momentum encoder),分别得到q与k结果。
- 计算l_pos(同图片,正向比对loss),l_neg(不同图片特征队列queue,反向比对loss)。合起来经过交叉熵计算出总的loss,按batch求平均。
- 梯度更新f_q,将梯度更新后的f_q按ExponentialMovingAverage方式更新到f_k。
- 将k加入队列,同时把队列末尾值出列。
encoder可以是任何结构的模型,可以是ResNet、Efficientnet等。最后学习到的图片特征,用于图片分类、目标检测等任务,可提高模型效率。
Tensorflow 2.0实现源码:https://github.com/tfwcn/tensorflow2-machine-vision/tree/master/AIServer/ai_api/ai_models/momentum_contrast
欢迎关注,你的关注是我创作的动力,谢谢
参考资料
论文:https://arxiv.org/abs/1911.05722
V2论文:https://arxiv.org/abs/2003.04297
Pytorch源码:https://github.com/facebookresearch/moco/tree/master

















 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











