




 本文介绍了如何在JIRA中通过CSV格式导入问题,详细步骤包括创建Excel并定义表头,确保问题类型和经办人信息正确,以及进行数据导入的六个步骤,包括字段匹配和配置信息的保存。
本文介绍了如何在JIRA中通过CSV格式导入问题,详细步骤包括创建Excel并定义表头,确保问题类型和经办人信息正确,以及进行数据导入的六个步骤,包括字段匹配和配置信息的保存。
之前在工作中,很多人问过能不能导入,我都说不能(捂脸)。
在疫情期间远程办公,突然发现了这个功能 import issues from CSV,就研究了下。
1、创建Excel,定义好表头,转换为CSV格式。

注意:问题类型值必须要与JIRA系统中对应,经办人也必须对应,是JIRA账号而不能输入中文姓名。
2、导入数据
步骤1:在问题-选择 import issues from CSV

步骤2:选择导入文件(步骤1中的文件),若已有配置文件可以选择。

步骤3:选择需要导入的项目,file encoding选择GB2312,否则下一步时文件中的中文会显示乱码。

步骤4:设置导入文件中字段与JIRA字段的匹配关系
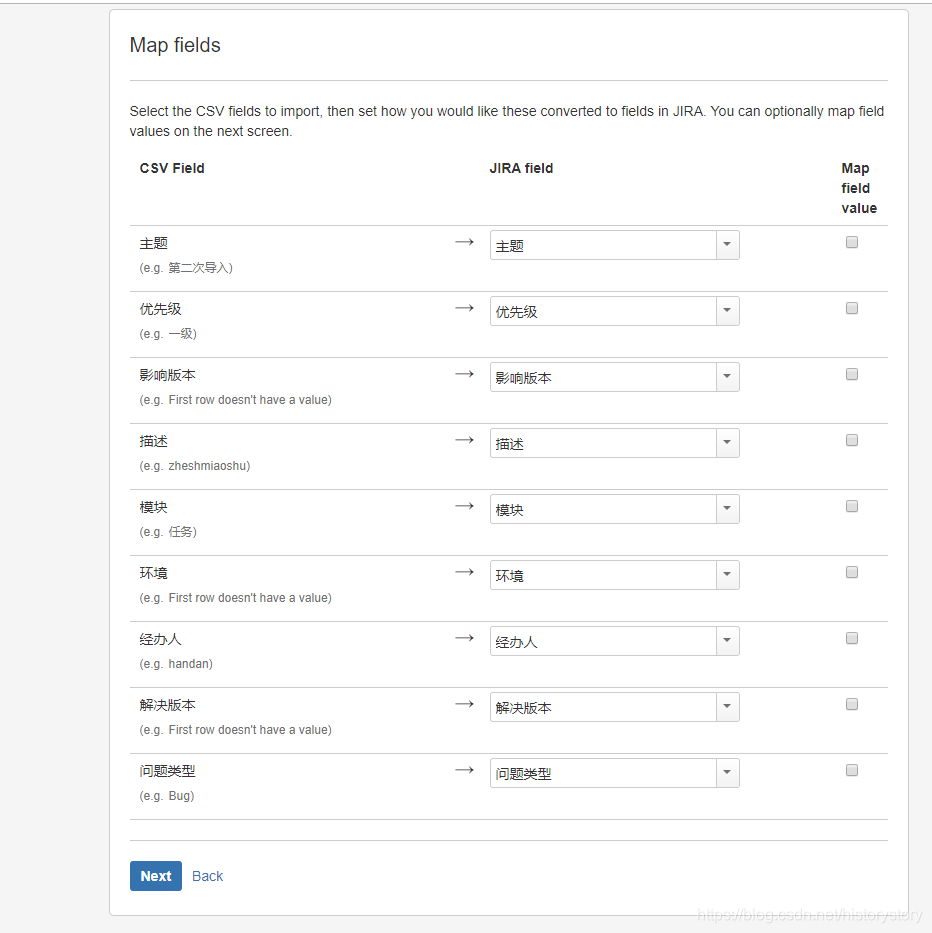
步骤5:开始导入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









