







先贴一篇讲的比较全的
http://www.cnblogs.com/dudumiaomiao/p/6560841.html
http://blog.csdn.net/myarrow/article/details/51878004
一 全连接层
1.整体的结构框图
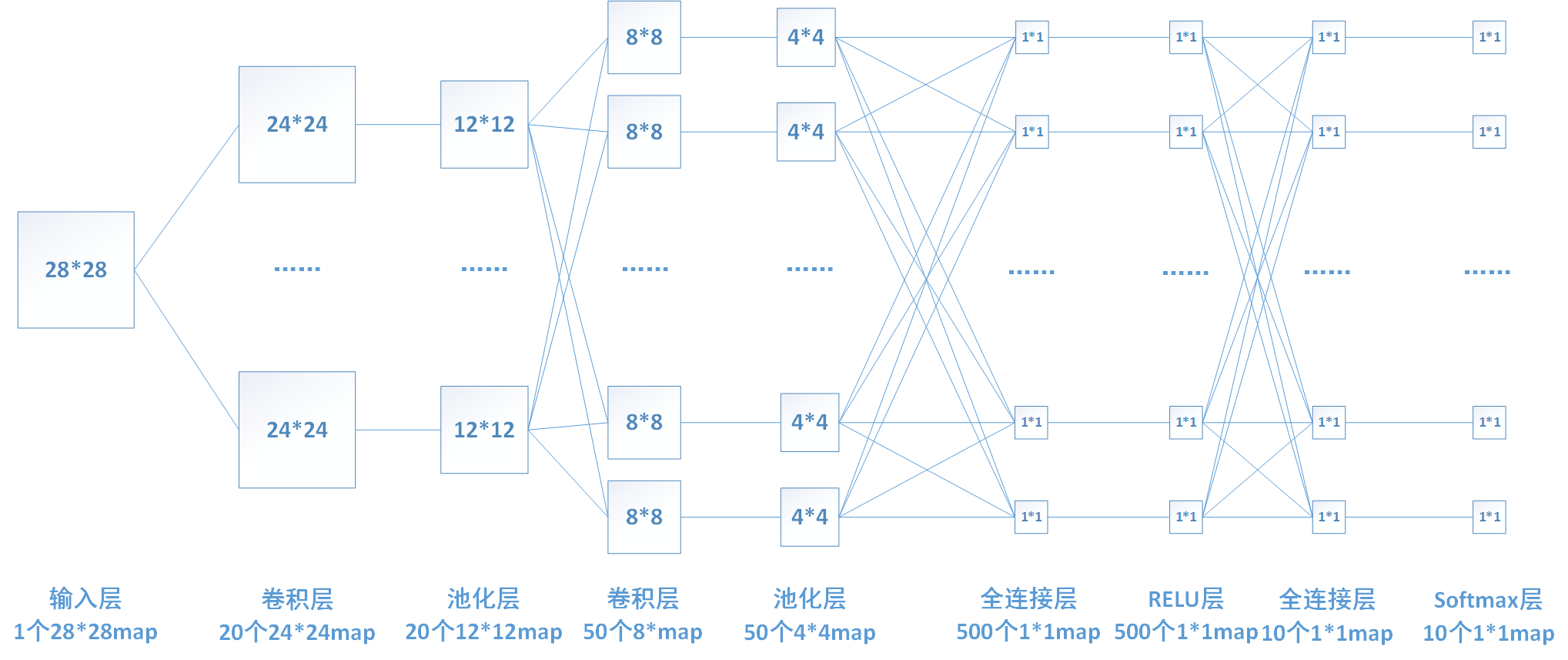
2.全连接层的推导:
转自如下链接
http://blog.csdn.net/daydayup_668819/article/details/59486223
3。全连接层的具体含义:
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽。
卷积层模仿人的视觉通路提取特征,全连接层一般负责分类或者回归,由于全连接层会丢失一些特征位置信息,所以最近FCN火了起来,全部卷积层,不用全连接层。
转自:https://www.zhihu.com/question/41037974/answer/150522307
全连接的核心操作就是矩阵向量乘积
本质就是由一个特征空间线性变换到另一个特征空间。目标空间的任一维——也就是隐层的一个 cell——都认为会受到源空间的每一维的影响。不考虑严谨,可以说,目标向量是源向量的加权和。
在 CNN 中,全连接常出现在最后几层,用于对前面设计的特征做加权和。比如 mnist,前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。(卷积相当于全连接的有意弱化,按照局部视野的启发,把局部之外的弱影响直接抹为零影响;还做了一点强制,不同的局部所使用的参数居然一致。弱化使参数变少,节省计算量,又专攻局部不贪多求全;强制进一步减少参数。少即是多)
在 RNN 中,全连接用来把 embedding 空间拉到隐层空间,把隐层空间转回 label 空间等。

2. RoI的输入输出
ROI pooling 层:
- 输入 shape :(N, W/16, H/16, channels),为什么 除了16,因为使用VGG16的话,会经历四次 2*2 的 max poolinig。
- 输出 shape :(num_rois, expected_H, expected_W, channels) ,论文中提到如果使用 VGG-16 的话,expected_H=expected_W=7
- 既然图片的 大小已经下降了16 倍,那么输入的 roi 也会相应的就行缩小16倍。(在代码中也有体现)
- 这样的话,我们就可以用放缩后的 roi 来取图片的 roi 区域,然后对这些区域进行 roi-pooling

roi的主要目的还是从feature map上抠出感兴趣区域,然后pooling。
为什么要做pooling呢?因为只要pooling出来了最大值,那么不管这个最大值在图片中的哪个位置,都会被检测出来,也就引入了不变性。
注意;pooling的尺度是不一样的,比如可以设置成9*9的,4*4的,最后都卷积为一个值。
pooling的连接: http://www.cnblogs.com/573177885qq/p/6071646.html
三 rpn
转自:http://www.cnblogs.com/EstherLjy/p/6774848.html
RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的滑窗(论文中作者选用了n=3,即3*3的滑窗)生成一个长度为256(对应于ZF网络)或512(对应于VGG网络)维长度的全连接特征。然后在这个256维或512维的特征后产生两个分支的全连接层:1.reg-layer,用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h;2.cls-layer,用于判定该proposal是前景还是背景。sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间。事实上,作者用全连接层实现方式介绍RPN层实现容易帮助我们理解这一过程,但在实现时作者选用了卷积层实现全连接层的功能。个人理解:全连接层本来就是特殊的卷积层,如果产生256或512维的fc特征,事实上可以用Num_out=256或512, kernel_size=3*3, stride=1的卷积层实现conv5-3到第一个全连接特征的映射。然后再用两个Num_out分别为2*9=18和4*9=36,kernel_size=1*1,stride=1的卷积层实现上一层特征到两个分支cls层和reg层的特征映射。注意:这里2*9中的2指cls层的分类结果包括前后背景两类,4*9的4表示一个Proposal的中心点坐标x,y和宽高w,h四个参数。采用卷积的方式实现全连接处理并不会减少参数的数量,但是使得输入图像的尺寸可以更加灵活。
 最后贴一个cs231n学习笔记:http://blog.csdn.net/myarrow/article/details/51878004
最后贴一个cs231n学习笔记:http://blog.csdn.net/myarrow/article/details/51878004















 4480
4480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









