






- 线性回归
- 定义与要素:利用回归分析确定变量间定量关系。涉及训练集(输入数据 x)、输出数据 y、拟合函数(如y=kx+b 或 y=θ⊤x)、训练数据条目数和输入数据维度。
- 代价函数与求解:构造代价函数 J(θ)=21∑i=1N(y(i)−hθ(x(i)))2,目标是找到使 J(θ) 最小的超平面参数 θ。通过令 ∂θ∂J(θ)=0,可得到解析解 θ=(X⊤X)−1X⊤y (适用于维数不高的情况)。
- 线性二分类问题
- 问题描述:线性分类器通过特征的线性组合进行分类决策,样本通过直线或超平面可分。其与线性回归在输出意义、参数意义和维度上存在差别。
- Sigmoid 函数与代价函数:引入 Sigmoid 函数 y=1+e−z1 (z=θ1x1+θ2x2+θ0 )将线性函数值转换为 0 - 1 之间的概率。构造代价函数 J(θ)=21∑i=1N(y(i)−hθ(x(i)))2 (hθ(x(i))=1+e−θ⊤x(i)1 ),由于 J(θ) 是非线性的,无法直接求解,采用迭代的梯度下降法,即 θk+1=θk−αdθdJ ,使 J(θ) 逐渐减小。
- 对数回归与多分类回归
- 对数回归:从概率角度,二分类问题可用条件概率描述,如 P(y(i)=1∣x(i))=hθ(x(i))=1+e−θ⊤x(i)1 。重新修改指标函数为 J(θ)=−∑i(y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))) ,对其最小化得到梯度 ∇θJ(θ)=∑ix(i)(hθ(x(i))−y(i)) 。这一过程基于极大似然估计,取似然函数 L(θ)=∏i=1mp(y(i)∣x(i),θ) ,最大化 L(θ) 等价于最小化 −l(θ) (l(θ)=logL(θ) )。
- 多分类回归:对于有 k 个标记的分类问题,分类函数为 hθ(x(i))=∑c=1keθc⊤x(i)1eθ1⊤x(i)eθ2⊤x(i)⋮eθk⊤x(i) ,取代价函数 J(θ)=−[∑i=1N∑k=1K1{y(i)=k}log∑j=1Kexp(θ(j)⊤x(i))exp(θ(k)⊤x(i))] ,对应梯度为 ∇θ(k)J(θ)=−∑i=1N[x(i)(1{y(i)=k}−P(y(i)=k∣x(i);θ))] ,这种方式称为 Softmax。代价函数也可简写为交叉熵损失 l(y,y^)=−∑j=1Kyjlogy^j 。
- 神经元模型
- 模型介绍:人工神经元模型 M - P 模型于 1943 年由 W.McCulloch 和 W.Pitts 提出,公式为 y=f(∑j=1nwjxj−θ) (f(x)={1,0,x≥0x<0 )。
- 作用函数:包括非对称型 Sigmoid 函数(f(x)=1+e−x1 或 f(x)=1+e−βx1 ,β>0 )、对称型 Sigmoid 函数(f(x)=1+e−x1−e−x 或 f(x)=1+e−βx1−e−βx ,β>0 )和对称型阶跃函数(f(x)={+1,−1,x≥0x<0 )。
- Hebbian 规则:连接权值的调整量与输入和输出的乘积成正比,即 Δw=α⋅x⋅y 。
- 感知机模型
- 原理:1957 年由 Rosenblatt 提出,用于解决线性分类问题。点到超平面的距离公式为 d=∥w∥w⊤x 。
- 模型与损失函数:感知机模型为 y=f(x)=sign(w⊤x) (sign(x)={−1,1,x<0x≥0 ),定义损失函数 L(w)=−∥w∥1∑y(i)(w⊤x(i)) ,目标是找到使 L(w) 最小的超平面参数 w∗ 。
- 训练过程:输入训练数据集,赋初值 w0 ,按顺序选择数据点判断是否为误分类点,若是则根据 wk+1=wk+ηy(i)x(i) (与 Hebbian 规则相同)更新权值,直到训练集中没有误分类点。但实际中很多问题线性不可分,此时迭代不收敛
问题做答:
1、尝试自行推导第10页PPT中𝛉的求解。

2、线性分类问题处理时为什么没有像回归直接使用最小二乘,而是引入了Sigmoid函数?尝试给予解释。
主要原因与两类问题的目标、输出要求以及模型特性差异有关:
- 输出性质差异:线性回归旨在预测连续的数值,其输出值本身具有实际意义。例如预测房价,输出的数值直接代表价格。最小二乘法通过最小化预测值与真实值之间的平方误差,能有效拟合数据,使得预测值尽可能接近真实值。而线性分类问题的目标是将样本分类到不同类别,输出是类别标签或属于某类别的概率。如苹果分类问题,结果是判断苹果属于某一类别,不是具体数值。直接使用最小二乘无法满足分类的需求,因为平方误差对于分类任务来说,不能很好地反映分类的准确性。引入 Sigmoid 函数,可以将线性组合的结果映射到 0 - 1 之间,用于表示样本属于某一类别的概率,更符合分类问题的输出要求。
- 模型决策边界特性:线性回归的最小二乘解确定的是最佳拟合直线(或超平面),目的是使数据点到直线(或超平面)的误差平方和最小。但在分类问题中,需要找到的是能将不同类别样本分开的决策边界(直线或超平面)。最小二乘得到的直线不一定能有效区分不同类别。Sigmoid 函数的特性使其可以将线性函数的值域(-∞, +∞)映射到(0, 1)区间,通过设置阈值(如 0.5),可以方便地确定分类决策边界。当 Sigmoid 函数的输出大于阈值时,判定样本属于一类;小于阈值时,属于另一类,这使得模型能够实现分类功能。
- 分类问题的非线性本质(部分情况):虽然线性分类器是基于特征的线性组合进行分类,但实际数据分布可能较为复杂,并非完全线性可分。最小二乘在处理非线性可分的数据时表现不佳。Sigmoid 函数的非线性特性,使得基于它构建的模型能够学习到数据中的非线性关系(尽管只是初步的非线性处理)。它可以对线性组合的结果进行非线性变换,增加模型的表达能力,更好地适应复杂的数据分布,提高分类的准确性。
3.什么是Softmax? 针对多分类问题,给出Softmax输出的图示。
Softmax 是一种用于多分类问题的函数,它将多个神经元的输出,映射为 0-1 之间的概率值,且所有概率值之和为 1,从而可以将其理解为每个类别对应的概率,以实现多分类的功能。
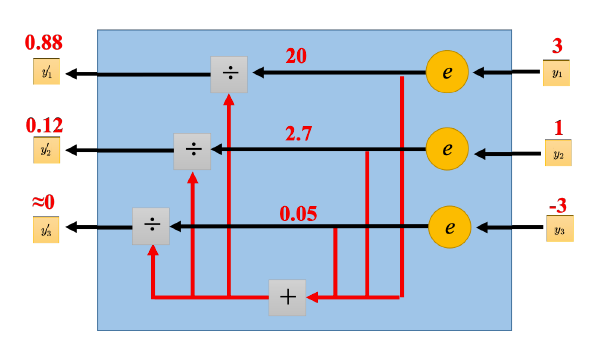
上图是一个简单的多分类问题的softmax使用,一般两个分类用sigmoid就可以了,三个以上用softmax,当然两个分类时二者等价。
4.写出神经元的M-P模型,并与线性回归的表达式进行对比。


相同点
- 线性组合部分:两者都包含了输入信号与权重(或参数)的线性组合。在 M - P 模型中的\(\sum_{j = 1}^{n}w_{j}x_{j}\) 和线性回归中的\(\theta_{1}x_{1}+\theta_{2}x_{2}+\cdots+\theta_{n}x_{n}\) 本质上都是对输入特征进行加权求和的过程,都体现了输入信号与对应权重的线性关系。
不同点
- 输出性质:
- 线性回归的输出y是连续的数值,用于预测一个具体的量,例如房价、销售额等。
- M - P 模型的输出是经过激活函数处理后的离散值(通常为 0 或 1),用于表示神经元的激活状态,常用于分类或逻辑判断等问题。
- 激活函数:
- 线性回归没有激活函数,输出直接是线性组合的结果。
- M - P 模型引入了激活函数\(f(\cdot)\),通过激活函数将线性组合的结果映射到特定的离散值,从而实现神经元的非线性特性,增加了模型的表达能力,能够处理更复杂的问题。
- 模型用途:
- 线性回归主要用于回归分析,即根据输入特征预测一个连续的目标值,重点在于找到最佳的拟合直线(或超平面)来最小化预测值与真实值之间的误差。
- M - P 模型是神经网络的基本单元,用于构建更复杂的神经网络结构,可用于解决分类、模式识别等多种机器学习问题,是神经网络实现智能计算的基础。
下面是第二节课内容
- 多层感知机
- XOR 问题:线性不可分问题,无法用线性分类解决。
- 多层感知机解决 XOR 问题:在输入和输出层间加隐单元构成多层感知器,加一层隐节点的三层网络可解决异或问题。通过特定的权值和阈值设置,各节点输出由输入和权值计算得出,且三层感知器可识别凸多边形或无界凸区域,更多层可识别更复杂图形。还介绍了相关定理,如三层阈值节点网络可实现任意二值逻辑函数,三层 S 型非线性特性节点网络可逼近连续函数或平方可积函数。
- 多层前馈网络及 BP 算法概述
- 多层前馈网络:多层感知机是多层前馈网络,由输入层、隐层和输出层组成,神经元间权值连接仅在相邻层,若每个神经元连接上一层所有神经元则为全连接网络。
- BP 算法简述:BP 算法是有导师的学习算法,由正向传播和反向传播组成。正向传播是输入信号从输入层经隐层传向输出层,若输出符合期望则学习结束,否则进入反向传播;反向传播是将误差按原连接通路反向计算,用梯度下降法调整各层节点权值和阈值以减小误差。
- BP 算法详解
- BP 算法基本思想:选取特定的损失函数,利用梯度下降法更新权值,通过推导得出不同层权值的更新公式。
- 程序示例:详见 D2L 4.2 节多层感知机的从零开始实现。
- 程序使用数据集:介绍了 Fashion - MNIST 数据集,它可替代 MNIST 手写数字集,涵盖 10 种类别共 7 万个不同商品的正面图片,大小、格式和训练集 / 测试集划分与 MNIST 一致。还给出了 MNIST 数据集加载的代码示例。

















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









