






论文:《You Only Look Once: Unified, Real-Time Object Detection》(CVPR2016)
代码:https://gitcode.net/mirrors/alexeyab/darknet?utm_source=csdn_github_accelerator
目录
1、创新点
(1)Two-stage(RCNN,fastRCNN,faster-RCNN)→ One stage(YOLO系列);
(2)检测任务 → 回归任务,仅仅通过一个神经网络,就可以得到bounding box的位置及其所属类别(端到端检测);
(3)在整张图像上进行推断,与fast-RCN相比,有效减少了背景误检数量;
(4)检测速度快:45FPS (448×448),准确率高:63.4mAP。
2、处理过程

(1)将输入图像的大小调整为448×448,分割得到7×7大小的网格;
(2)通过CNN提取特征和预测;
(3)利用非极大值抑制(NMS)进行筛选。
3、主要思想
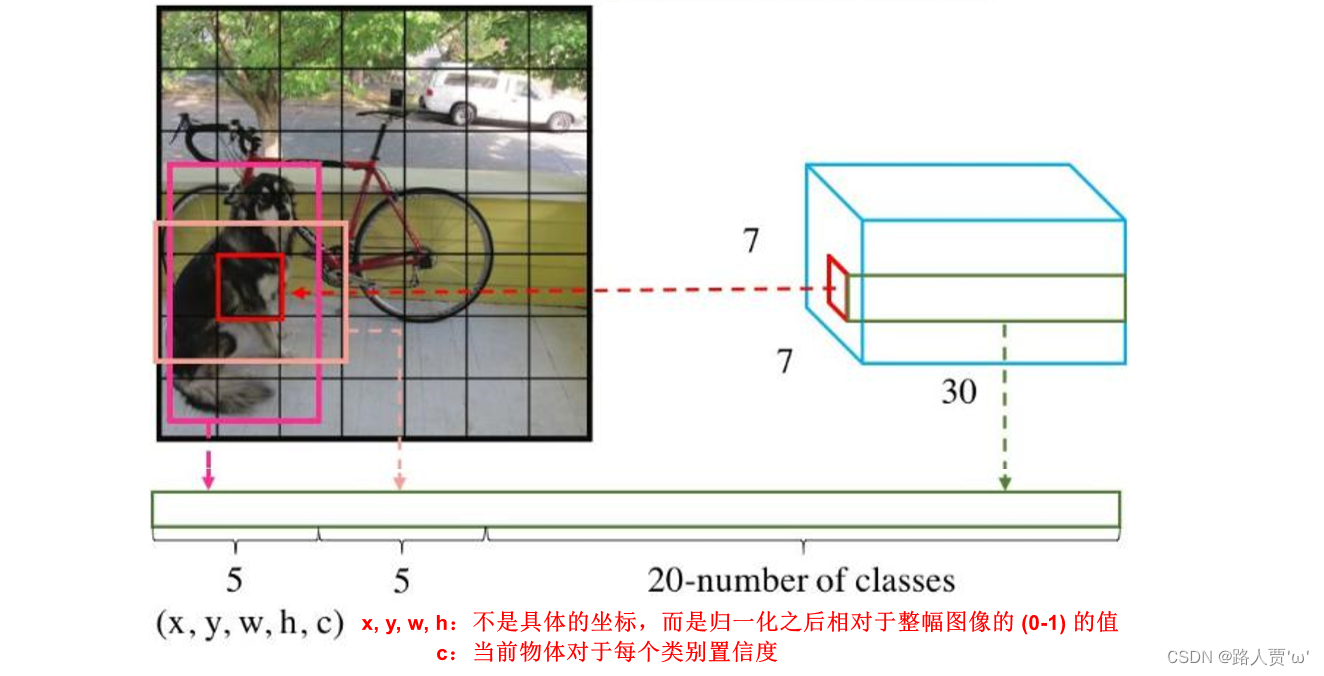
(1)YOLO将目标检测问题作为回归问题。将输入图像分成S×S的网格(grid cell),如果一个物体的中心点落入到一个grid cell中,那么该grid cell就要负责预测该物体。
(2)每个grid cell只预测一个目标,会生成B个预测框(bounding box),每个预测框包含一组(x, y, w, h, c)参数。
(3)除此之外,每个bounding box还要预测C个类别分数。
x, y:bounding box的中心坐标相较于该bounding box归属的grid cell左上角的偏移量,在0-1之间。
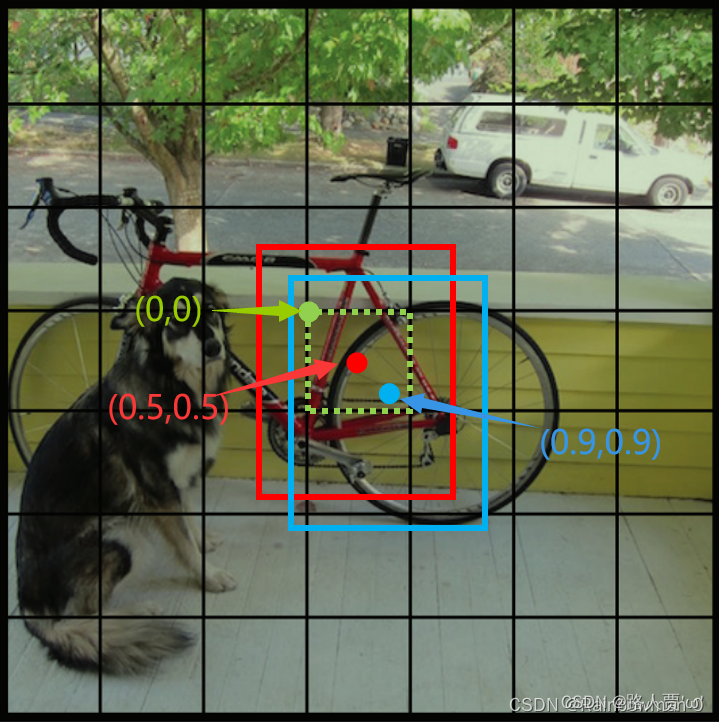
w, h:bounding box的宽和高,也归一化到了0-1之间,表示相较于原始图像(448×448)的宽和高的比例。

c:置信度(confidence)
grid cell中有目标时:Pr(Object)=1,;
grid cell中没有目标时:Pr(Object)=0,。
类别分数:属于该类别的概率(0-1之间),条件概率与置信度的乘积。
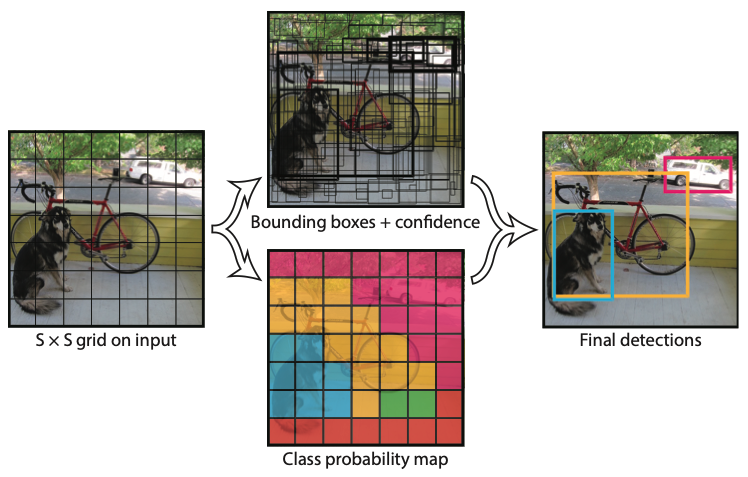
在PASCAL VOC数据集上,S=7,B=2,C=20,因此网络的输出为S × S × (5×B+C) → 7 × 7 × (2×5+20)。
4、网络结构
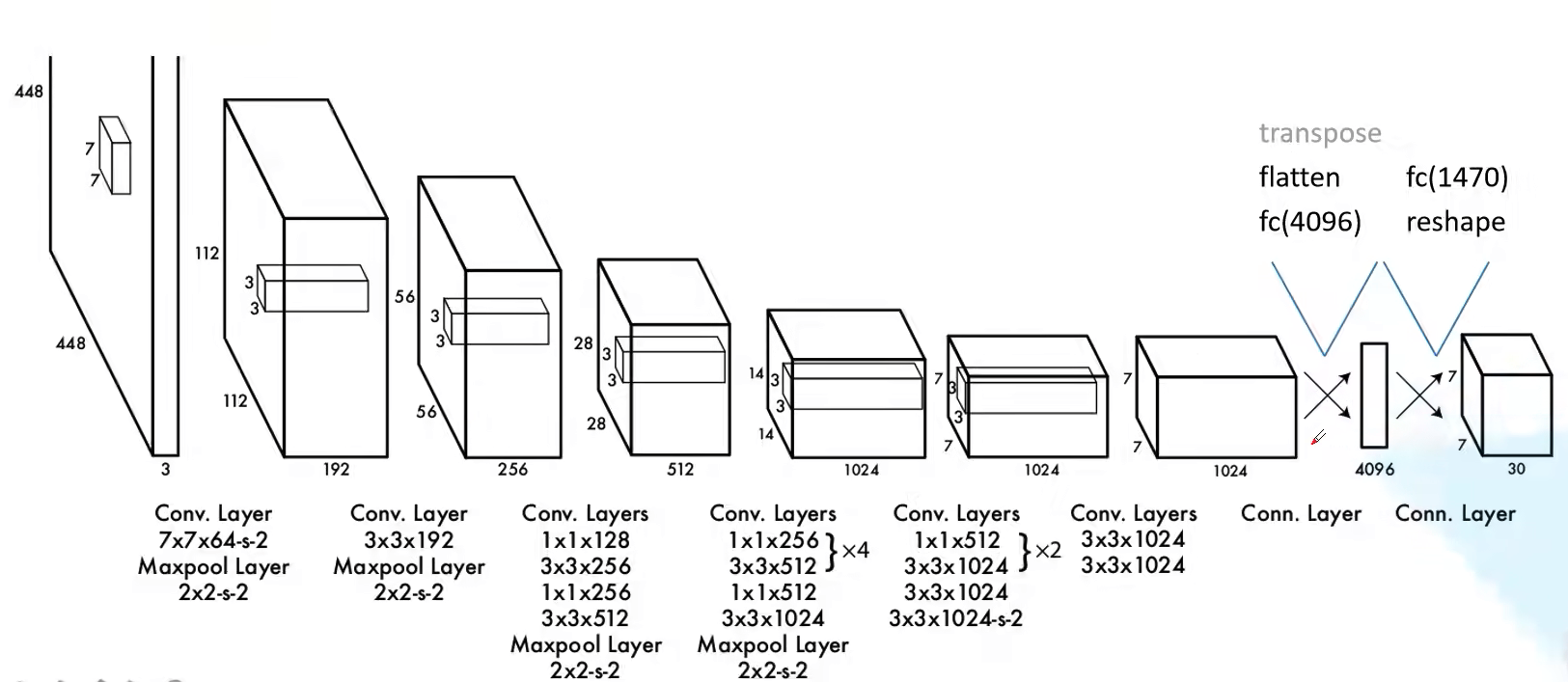
YOLO网络借鉴了GoogLeNet,输入图像尺寸为448×448,经过24个卷积层,2个全连接层,最后reshape操作,输出特征图大小为7×7×30。
5、损失函数
- localization loss -> 坐标损失
- confidence loss -> 置信度损失
- classification loss -> 分类损失
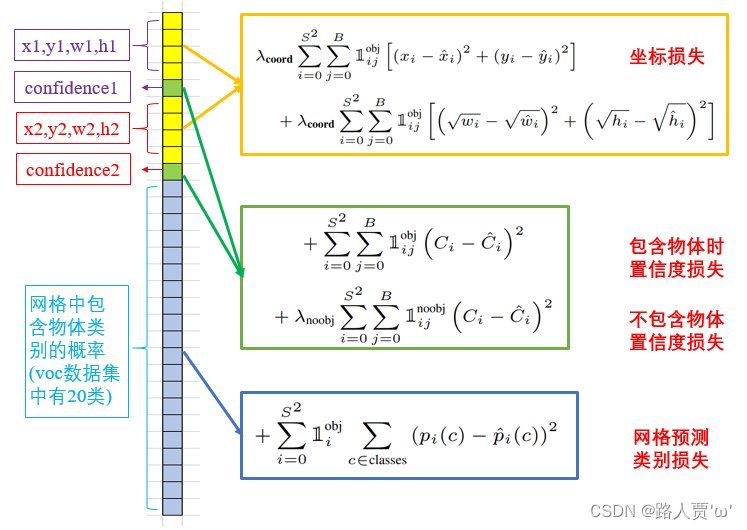
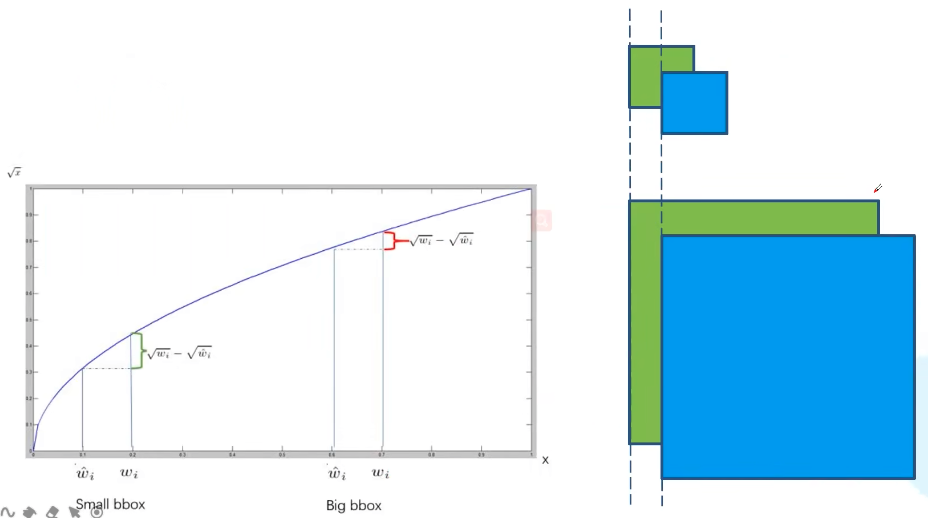
(1)坐标损失

对宽和高加根号能够使得同样的IoU误差对大目标与小目标的惩罚值不同:
(2)置信度损失
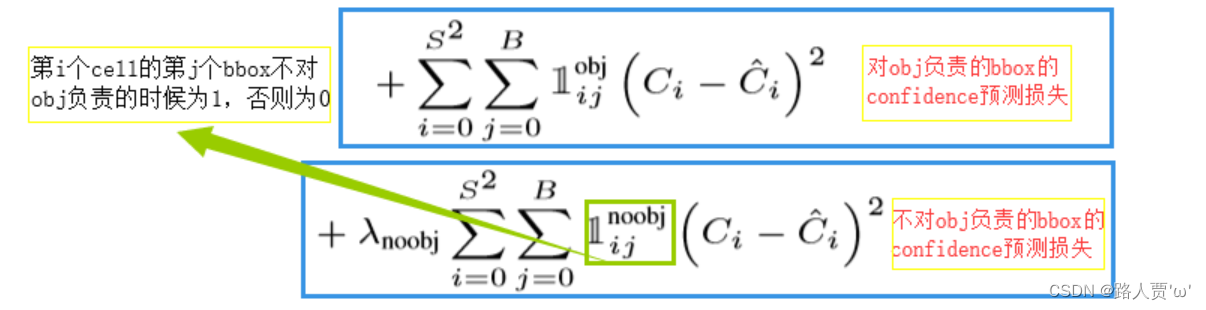
正样本损失:第i个grid cell中存在目标的情况,
负样本损失:第i个grid cell中不存在目标的情况,
(3)类别损失

6、局限性
1、YOLO对相互靠近的物体,以及群体小目标的检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。
2、由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,small error影响更大)
3、当目标出现新的尺寸或比例时,预测效果较差(直接预测坐标信息,而不是回归参数,泛化能力差)。
参考:















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









