






目录
1、CodeFormer: Towards Robust Blind Face Restoration with Codebook Lookup Transformer
(1)Stage I: 获得一个高质量的codebook和一个Decoder
(2)Stage II: 将LR图像的Feature与码本中的编码进行匹配
2、BFRffusion:Towards Real-World Blind Face Restoration with Generative Diffusion Prior
(1)Shallow Degradation Removal Module(SDRM)
(2)Multi-scale Feature Extraction Module(MFEM)
(3)Trainable Time-aware Prompt Module(TTPM)
(4)Pretrained Denoising U-Net Module(PDUM)
1、背景
传统基于人脸先验的方法:
(1)参考先验:通常使用从额外的高质量人脸图像中获得的面部结构或面部成分词典作为参考先验来指导人脸恢复过程,但可能会改变恢复人脸的身份信息。
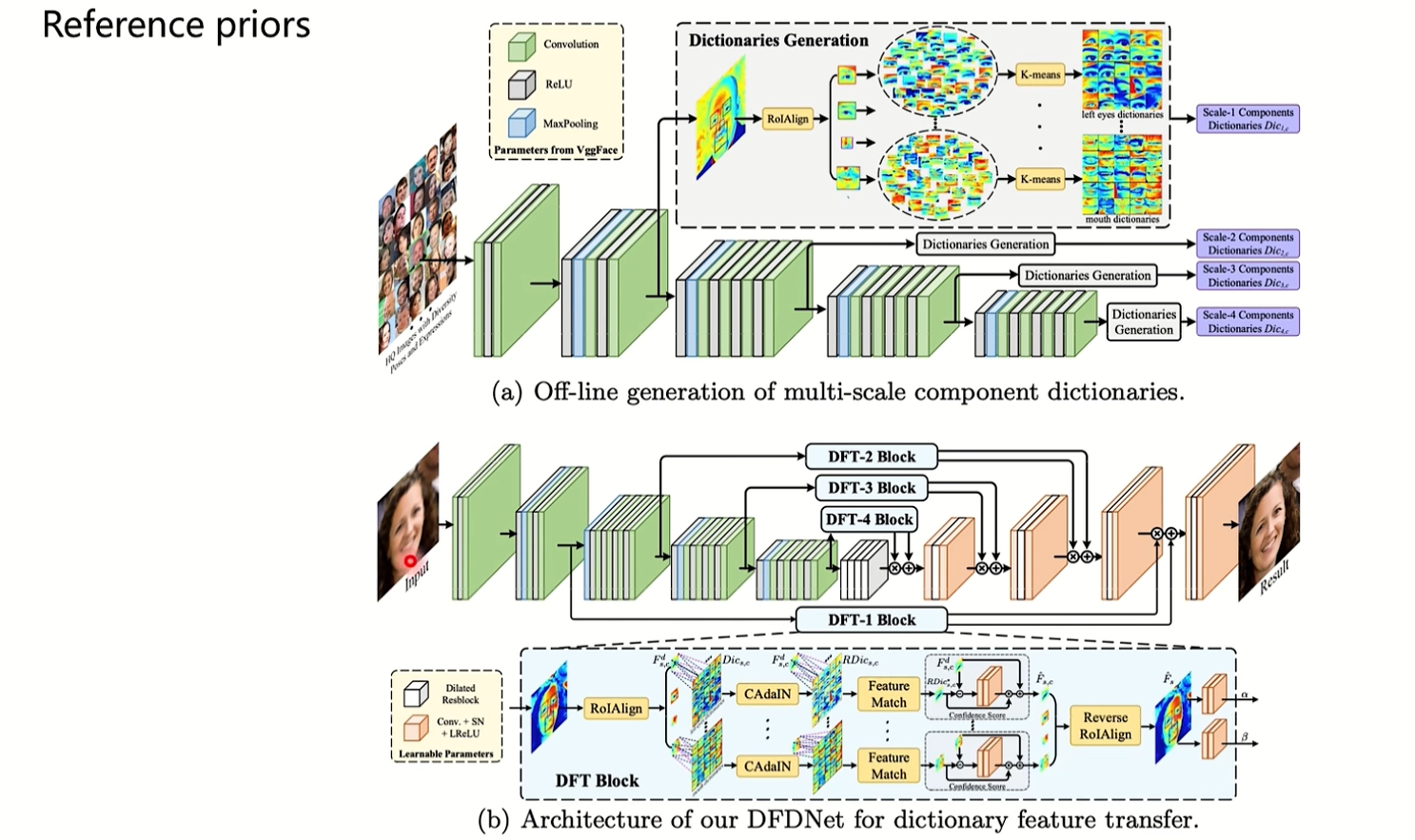
上图是参考先验,在生成过程中,会拿一些高质量的人脸图像去训练,模型会从高质量人脸图像中自动学习到一些人脸的结构或者特征,把它当成一个参考先验去指导去指导低质量图像的生成。
(2)几何先验:从低质量的人脸图像中提取面部关键点、面部热图、面部解析图等先验知识,来逐步恢复高质量的人脸图像,这也导致恢复效果与退化程度有关。
(3)生成先验:生成先验通常包括GAN反演和预训练的面部GAN模型,以提供更丰富,更多样化的面部信息。
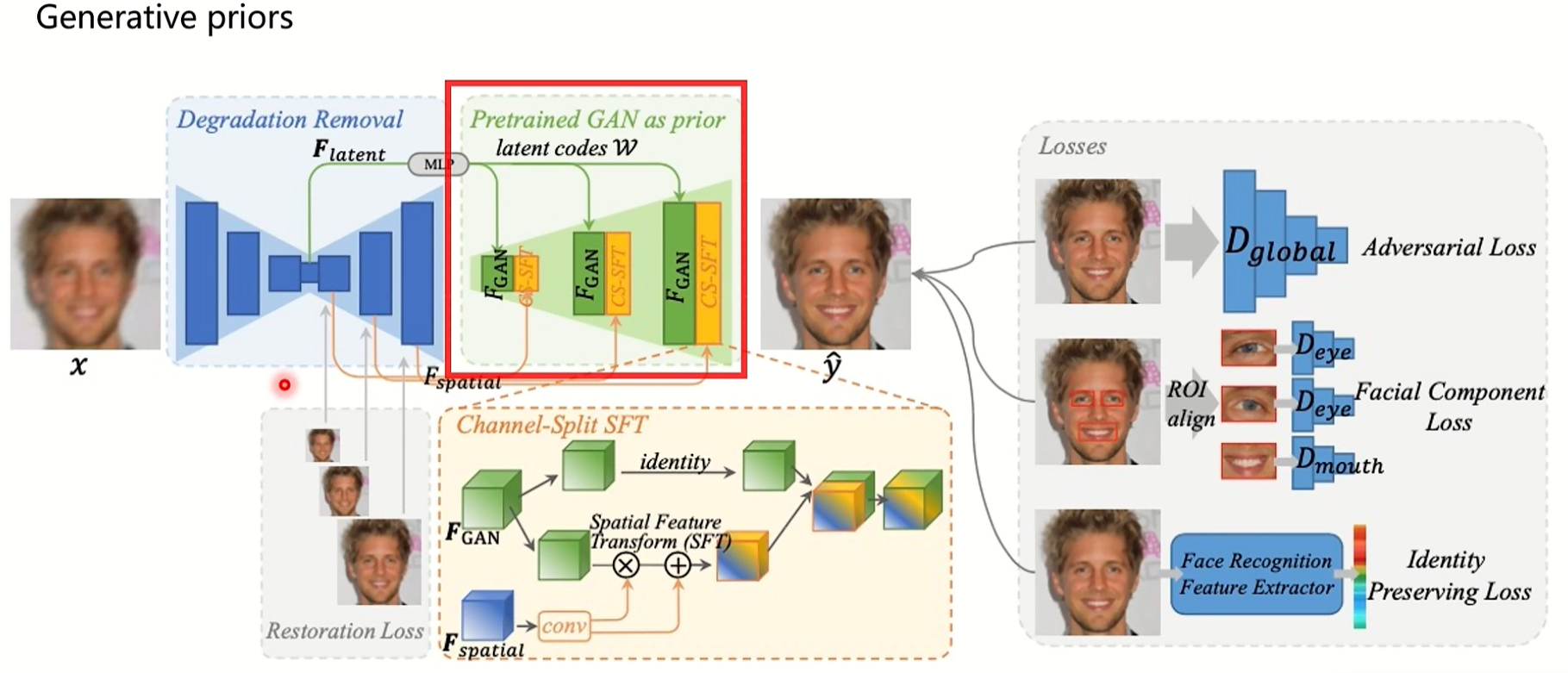
上图是gfpgan,属于生成先验,用一个训练好的网络作为一个生成器,把低质量的人脸图进行一个编码解码,之后把不同层次的特征送入到已经训练的stylegan中辅助图像生成。
(4)diffusion先验:diffusion model被证明比GAN更稳定,生成的图像更加多样化。
2、数据集
训练集:高质量和低质量图像对。高质量图像是FFHQ数据集的70K图像,分辨率为512×512;通过下方公式退化图像构造低质量数据集,分辨率也调整为512×512。
![]()
y 表示低质量图像,x 表示高质量图像,⊛ 表示卷积操作,kσ 表示高斯模糊核,↓r 表示下采样,nδ 表示高斯白噪声,JPEGq 表示 JPEG 压缩。
测试集:合成的配对数据集CelebA-Test(3K配对图像)和三个真实世界数据集:LFW-Test(1711 张低质量图像)、CelebAdult-Test(180张成人面孔)和 WIDER-Test(970 张严重退化的面部图像)。
3、验证指标
像素指标(PSNR 和 SSIM):PSNR通过像素的均方误差 (MSE) 定义;SSIM侧重于图像的结构信息(例如亮度、对比度等)。
感知指标(LPIPS、FID和MUSIQ):LPIPS从图像中提取特征,然后使用预训练的VGG网络计算特征之间的感知差异;FID计算从预训练的初始模型中提取的特征向量在训练数据集和恢复图像之间的相似性。
LMD:landmark距离,用于评估面部位置和表情的准确度。
IDS:ArcFace网络中特征的余弦相似度来评估身份信息。
CelebA-Test数据集使用像素指标和感知指标进行评估,真实世界的数据集使用FID。
1、CodeFormer: Towards Robust Blind Face Restoration with Codebook Lookup Transformer
论文:Towards Robust Blind Face Restoration with Codebook Lookup Transformer
代码:https://github.com/sczhou/codeformer
1、motivation
目前模型存在High sensitivity to degradation和Limited priorexpressiveness,在退化严重的情况下非常依赖低质量LR,一些方法将面部信息投影到连续空间,但退化严重时无法确认latent vectors的生成效果,结果不好。
这是什么原因呢?比如gfpgan在网络中有大量的跳跃连接,就是残差结构,会把一些低质量的信息传到后面解码器中,当LR退化很严重时,一些低质量的特征会直接影响HR的生成。
2、创新点
(1)将人脸重建任务转换为codebook的预测任务,在有限空间中进行离散codebook的预测,降低不确定性;
(2)引入Transformer代替最近邻插值(NN)进行预测,提出CodeFromer网络;
(3)新引入数据集WIDER-Test包含970个严重退化的人脸。
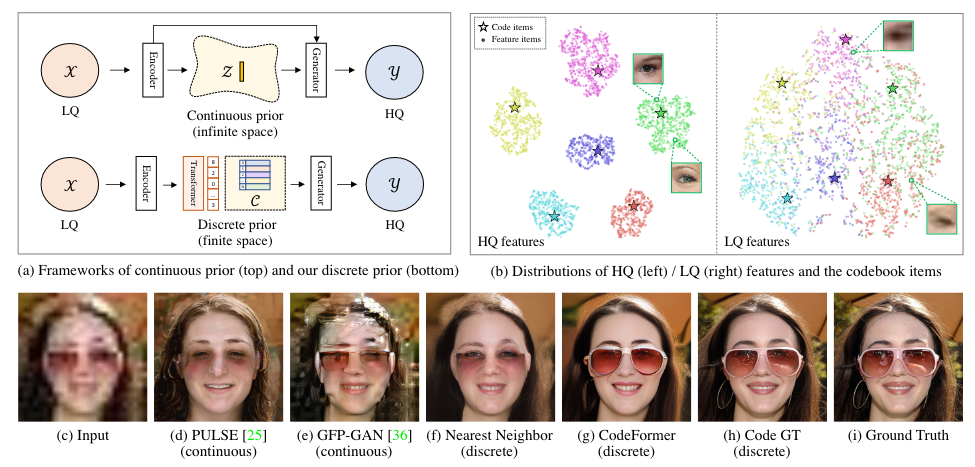
CodeFormer把人脸超分任务转化为预测一个离散的codebook,之前的方法都是预测一个连续的隐向量,通过编码器预测后作为解码器的输入。但CodeFormer不是编码到一个连续的空间,而是编码到一个离散的codebook中,例如codebook是1024维的,数量是1024,维度是256,预测到codebook中是因为把图像映射到一个连续的空间中范围太大了,codebook是一个有限的空间,将一张图像映射到一个较小的codebook中不确定性大大减少,也会减少网络对于lr的依赖,因为CodeFormer基本没有用到残差连接。
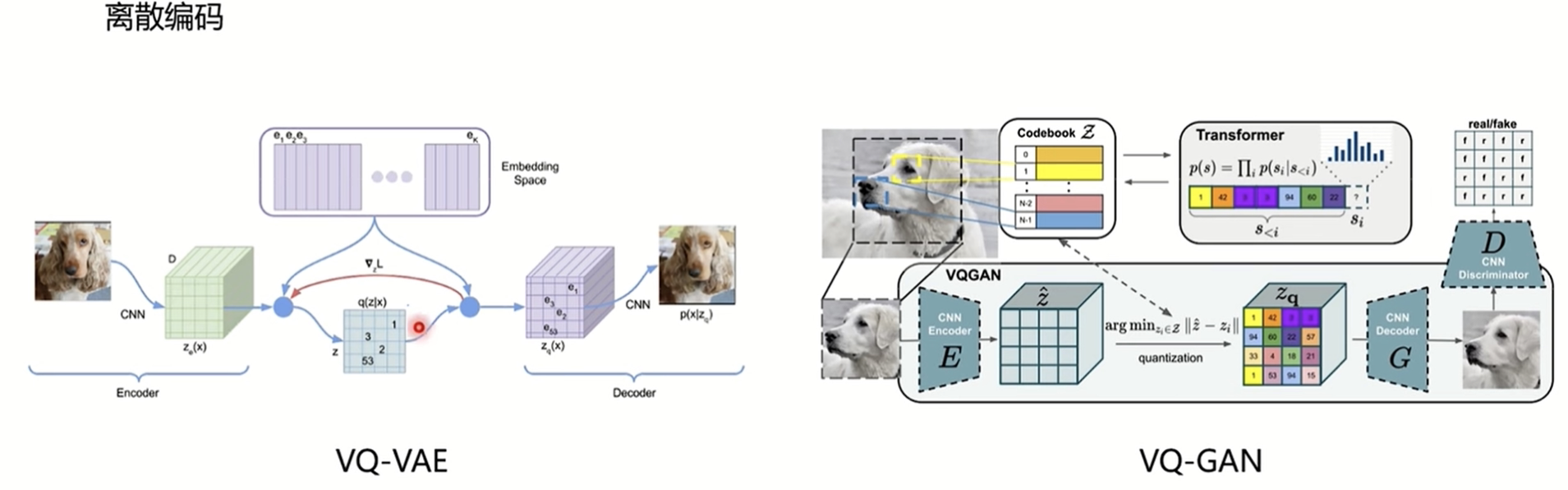
一张图片通过一个编码器编码得到m × n × d维的特征向量,VAE结构生成一个连续的向量,也就是一个分布,直接采样送入解码器中。VQ-VAE多了VQ的操作(向量量化),如图上的绿色方块,是m × n × d维,第0个方块是1 × 1 × d维,通过在离散的codebook中找一个和它最相近的,codebook维度是1024 × d,就把codebook中最近邻的向量的索引放到蓝色表中,用codebook做一个映射,用蓝色的表中的索引作为codebook中的embedding,这样就可以从蓝色表中得到解码器的输入,再利用解码器进行重建。
VQ-GAN和VQ-VAE是一致的,通过编码器得到特征之后,通过最近邻匹配,训练解码器,这个流程训练好之后,丢掉编码器,只要解码器。但做无监督生成时,就需要有一个对应的索引表,这样才能从codebook中找到对应的embedding去得到解码器的输入,那么这个索引表是通过gpt2生成的,通过自回归预测出来的,有个索引表就可以得到输入。之所以VQ-GAN,只是因为加了一些GAN的损失。
3、网络设计
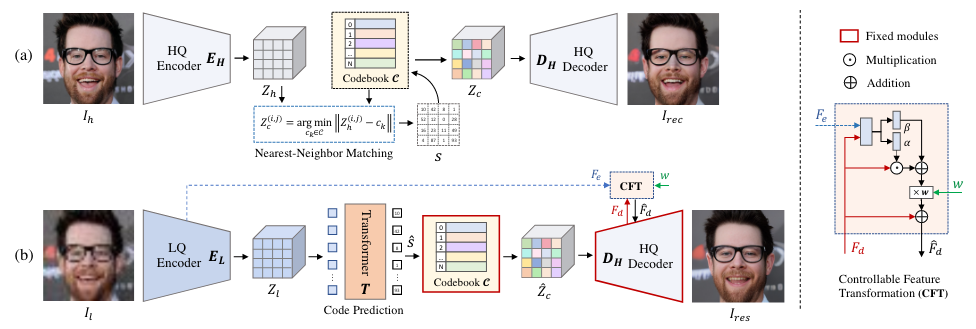
(1)Stage I: 获得一个高质量的codebook和一个Decoder
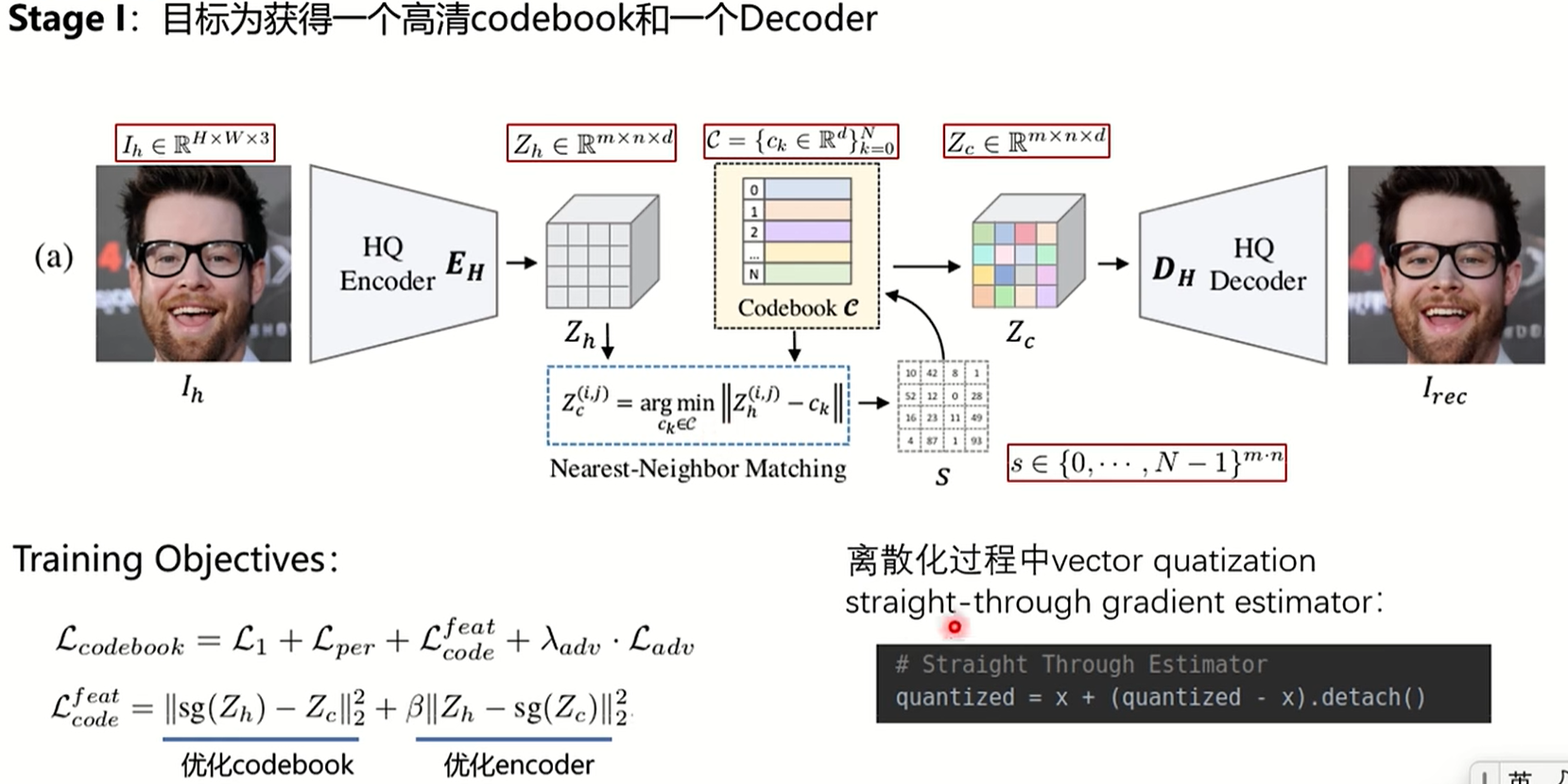
codeformer训练是分成三个部分的,第一阶段是为了获得高质量的codebook和一个训练好的decoder,输入输出均为高质量的HR图像,但这个过程不使用任何残差连接。例如输入图片维度是H × W × 3,经过编码器后的输出是m × n × d,离散编码就是对m × n位置中的每一个d都去codebook中找到最近的embedding,argmin匹配起来。encoder生成的m × n × d其实就是一组特征,从codebook中找到最相近的去代替encoder输出的特征,其实就是聚类,相当于codebook中有一些聚类中心,从上图也可以看出HR的聚类效果是很好的,从codebook中得到m × n × d维的Zc作为解码器的输入。如果直接用LR训练无法得到高质量的表示,所以使用HR进行训练,得到一个高质量的codebook。
这种方式没有任何的残差连接,HR图像是从codebook中恢复出来,在第一阶段整体的loss=L1 loss,就是编码解码的过程(AE);Lper是感知损失,比较VGG网络提取特征的相似度;由于训练过程中把Zc的梯度直接复制给Zh,所以codebook实际是未训练的,因此额外提出了Lcode损失,sg是stop gradient,锁住Zh的梯度,实际在训练Zc,Zc是codebook中的一维组合,所以这一项实际就在优化codebook,第二项同理,是在优化encoder。
(2)Stage II: 将LR图像的Feature与码本中的编码进行匹配
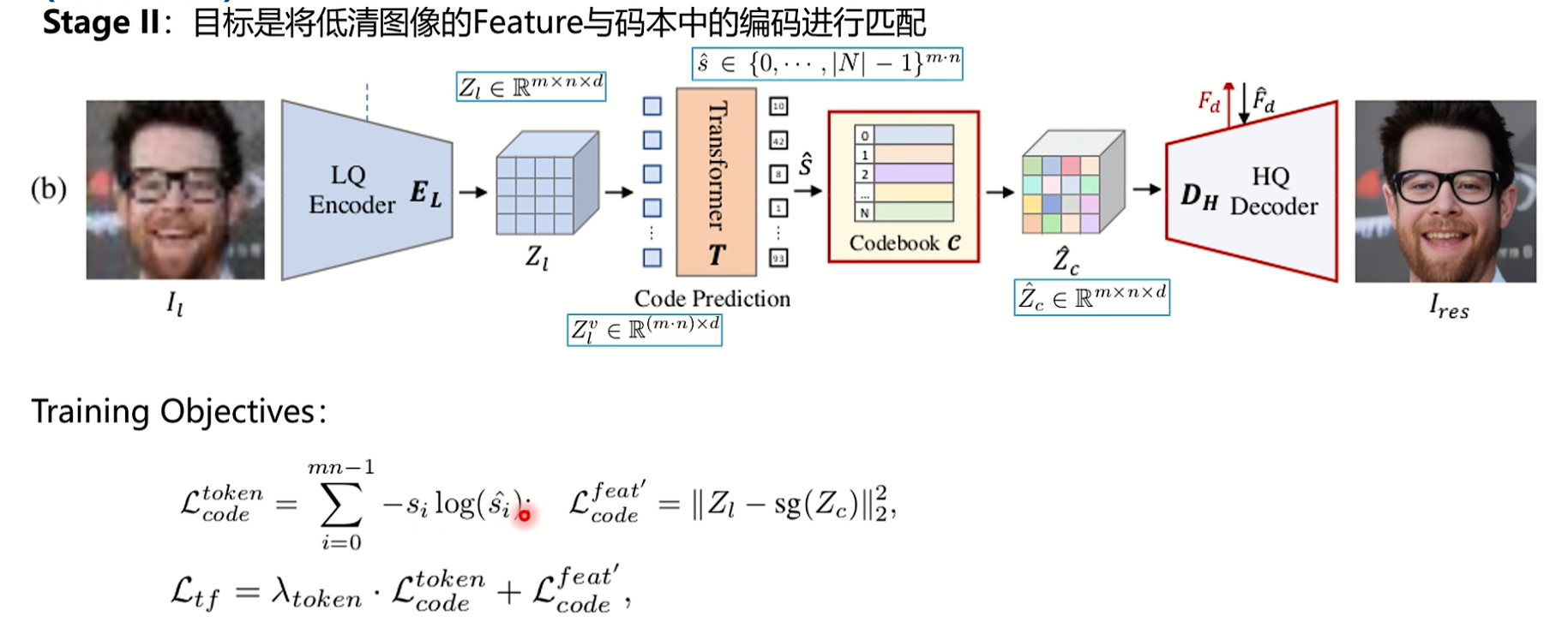
第一阶段训练得到一个高质量的codebook和一个训练好的decoder,第二阶段就是就是将LR图像的feature和codebook中的编码信息匹配起来。这个匹配过程在第一阶段使用的是最近邻匹配,之所以用最近邻,是因为在HR图像中特征本身就是很好聚类的,但在退化之后的LR图像中,特征是比较难聚类的,此时便引入了TransFormer代替最近邻插值。
第二阶段的输入是LR图像,将一张退化后LR图像经过编码器,得到m × n × d维的feature map。因为使用transformer,所以要将输入输出变成(m × n) x d维,输出s,即预测第一阶段的索引表,也是(m × n) × d的。这一阶段是对codebook的loss训练,不是图像loss,在第一阶段训练HR图像时会产生一个,此时这个
就是gt,在第一阶段证明了gt对于原图的恢复是非常有效的。TransFormer训练出来的s和
进行交叉熵损失监督,后面这部分损失和之前时一样的,此时训练的就是前面这个编码器。
(3)Stage III: 提升保真度
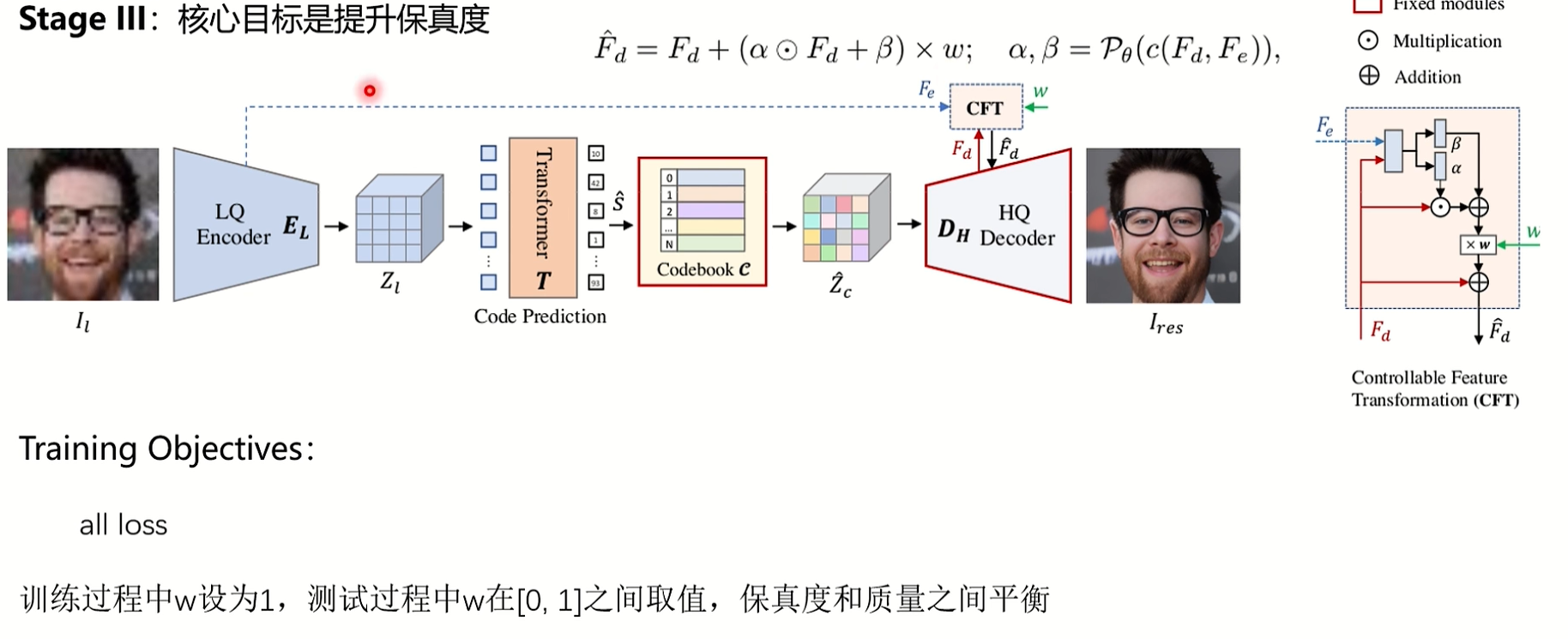
第三阶段是保真度和质量之间的平衡,保真度是因为没有残差连结,所以生成出来的图可能质量很高,但是和原图不像,所以需要添加一个约束。在训练过程中w一般取0.5,其实就是通过残差连接来控制和原图的相似度。这一阶段会把所有的损失都用上。
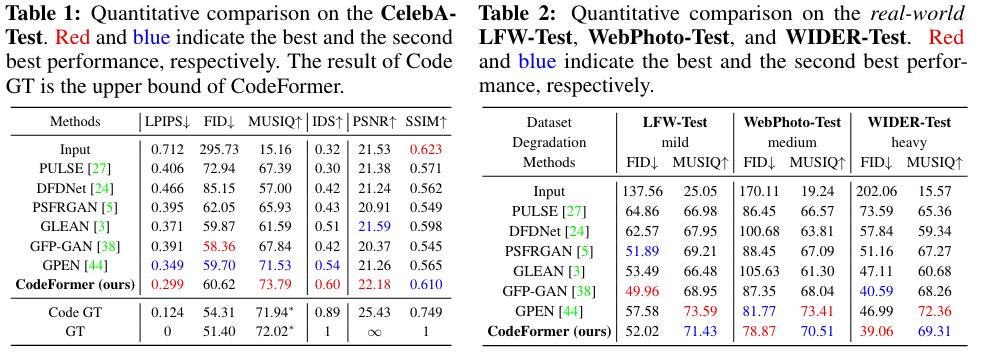
4、实验结果
(1)定量评估
(2)可视化结果

参考:
codeformer:towards robust blind face restoration with codebook lookup transformer-CSDN博客
2、BFRffusion:Towards Real-World Blind Face Restoration with Generative Diffusion Prior
论文:Towards Real-World Blind Face Restoration with Generative Diffusion Prior
代码:https://github.com/chenxx89/bfrffusion
1、创新点
(1)进一步探索了预训练的stable diffusion在盲人脸修复领域的生成能力,与GAN先验相比,stable diffusion可以提供更丰富、更多样化的先验知识,从而生成更真实逼真的面部细节。
(2)提出了一个BFRffusion盲人脸修复方法,可以有效地从低质量面部图像中提取多尺度特征并充分利用diffusion先验。
(3)提供了一个合成的人脸数据集,称为 Privacy-preserving-Faces-HQ (PFHQ),该数据集包括60K配对的面部图像,具有平衡的种族、性别和年龄,用于训练恢复网络。
2、网络设计
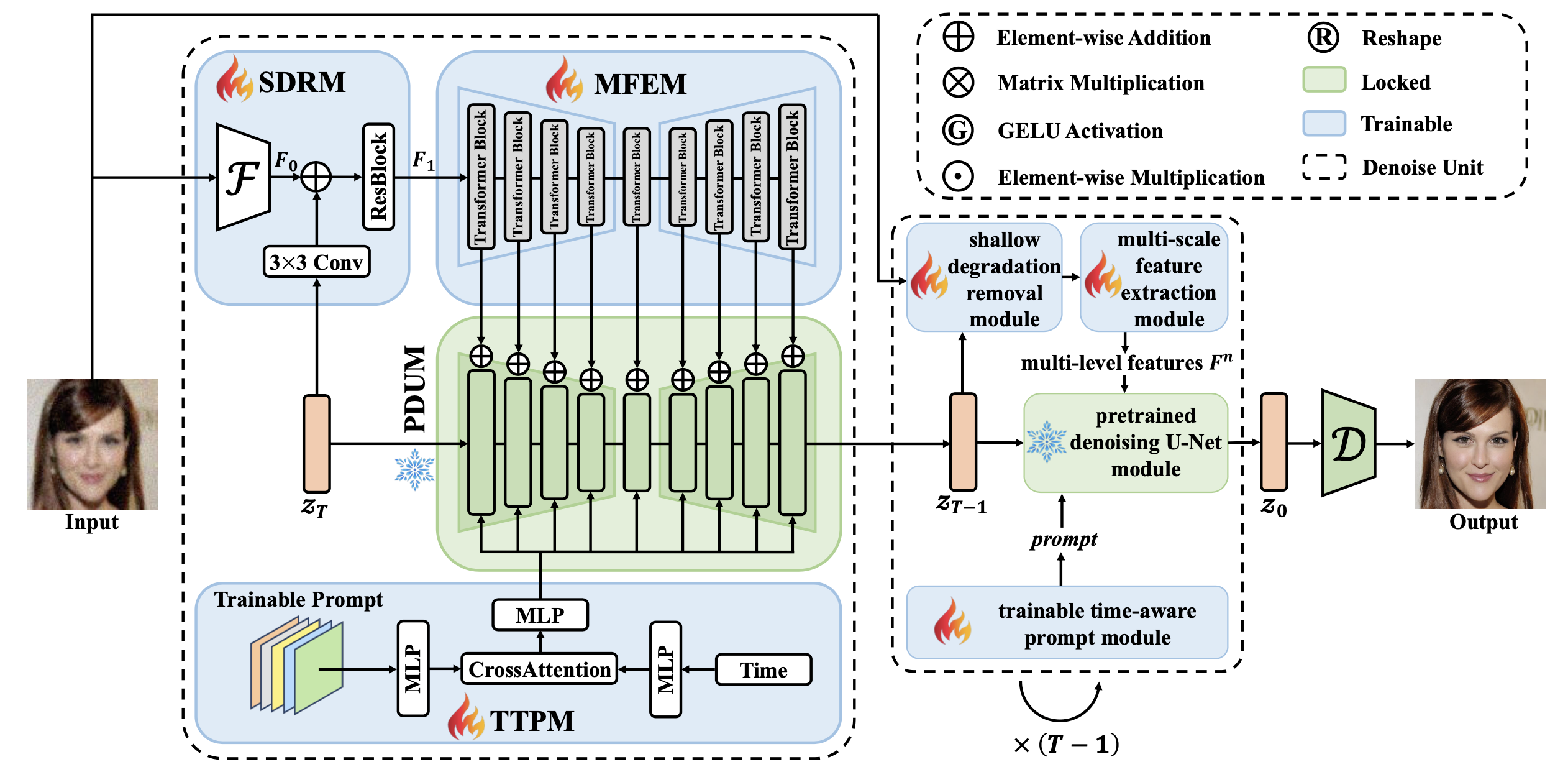
输入:一张人脸图像
(1)Shallow Degradation Removal Module(SDRM)
浅层退化去除模块,从输入的低质量图像中获得清晰的潜在特征,由多个卷积、激活函数和一个ResBlock组成,将输入图像编码为一个潜在的特征表示,并从中提取特征F1。
stable diffusion使用带有 KL损失的预训练变分自动编码器(VAE)将512×512的图像编码为64×64的潜在图像。为了匹配该分辨率,设计了一个编码网络F,包含几个卷积层,用于去除低质量图像的浅层退化并将其编码为64×64的清晰图像。
![]()
zt:随机采样的噪声(t ∈ [1,T],T是扩散步骤数),利用3×3的卷积层来调整zt的强度,加入潜在特征F0以稳定去噪过程,并使用多个MLP层对时间步长t进行编码作为time embedding。
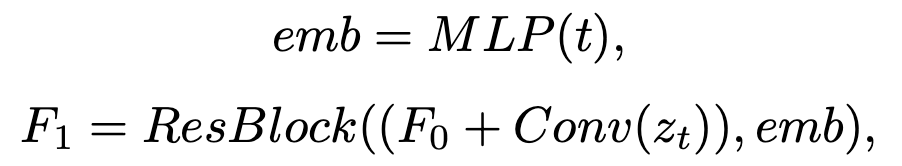
(2)Multi-scale Feature Extraction Module(MFEM)
多尺度特征提取模块,从 F1 中提取清晰的潜在特征,并提取适合stable diffusion不同分辨率的多尺度特征。MFEM 由几个transformer block组成,并结合了下采样、上采样和跳跃连接,它们同时考虑了潜在特征信息和时间条件。

首先使用多个 MLP 层从emb生成六个仿射变换参数α1、β1、γ1、α2、β2、γ2。之后应用空间特征变换 (SFT) 来调制经过 LayerNorm 层处理的输入图像特征。
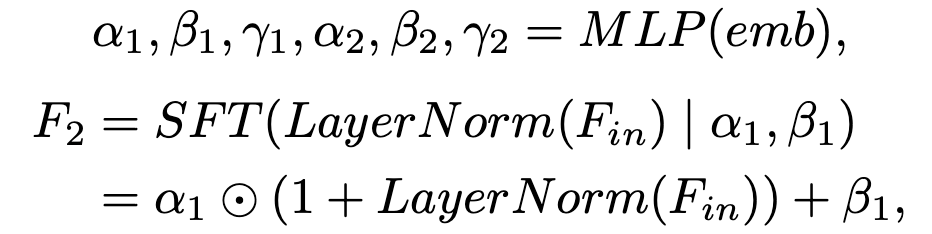
采用多头自注意力从输的入潜在特征中捕获全局和局部上下文信息:
1、首先使用pixel-wise convolutions Wp 和 depth-wise convolutions Wd 从输出特征F2生成K、Q、V。
2、使用跨通道执行self-attention以生成隐式编码全局信息的Attention Map。(α 可学习)
3、使用仿射变换参数 (γ1) 缩放Multi-Head self-Attention的输出。
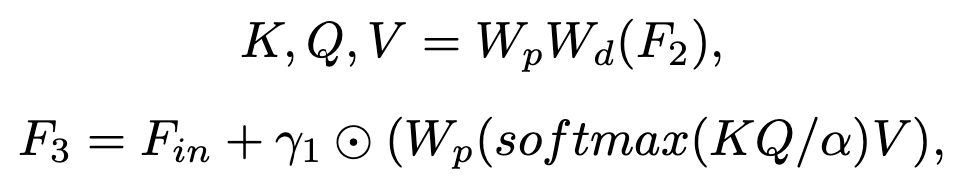
4、之后引入门控前馈网络 (GFFN) 增强网络的表达能力。GFFN 包含三个并行路径的element-wise product,由Wp、Wd和Gelu函数G组成。
5、在GFFN之后,使用仿射变换参数 (γ2) 对输出进行缩放。
![]()
为了匹配stable diffusion blocks 的不同分辨率,收集了MFEM中所有transformer blocks的输出特征,并应用高斯权重初始化的Wp 来调整不同transformer blocks之间输出特征的强度。
![]()
(3)Trainable Time-aware Prompt Module(TTPM)
可训练时间感知提示模块,由可训练参数、cross attention和多个MLP组成,生成可以在不同时间步骤中指导恢复过程的prompt,使用交叉注意力将时间编码嵌入到prompt中。
![]()
其中P是可训练的参数,与CLIP文本编码器的输出大小相匹配,Prompt是TTPM的输出,为每个时间步的恢复过程提供语义指导。
(4)Pretrained Denoising U-Net Module(PDUM)
预训练去噪 U-Net 模块。BFRffusion采用预训练的U-Net of stable diffusion作为去噪器,将来自MFEM的输出特征Fn添加到PDUM中以指导去噪过程,并通过cross attention层映射来自TTPM的prompt以提供语义指导。网络的输出是添加的噪声。
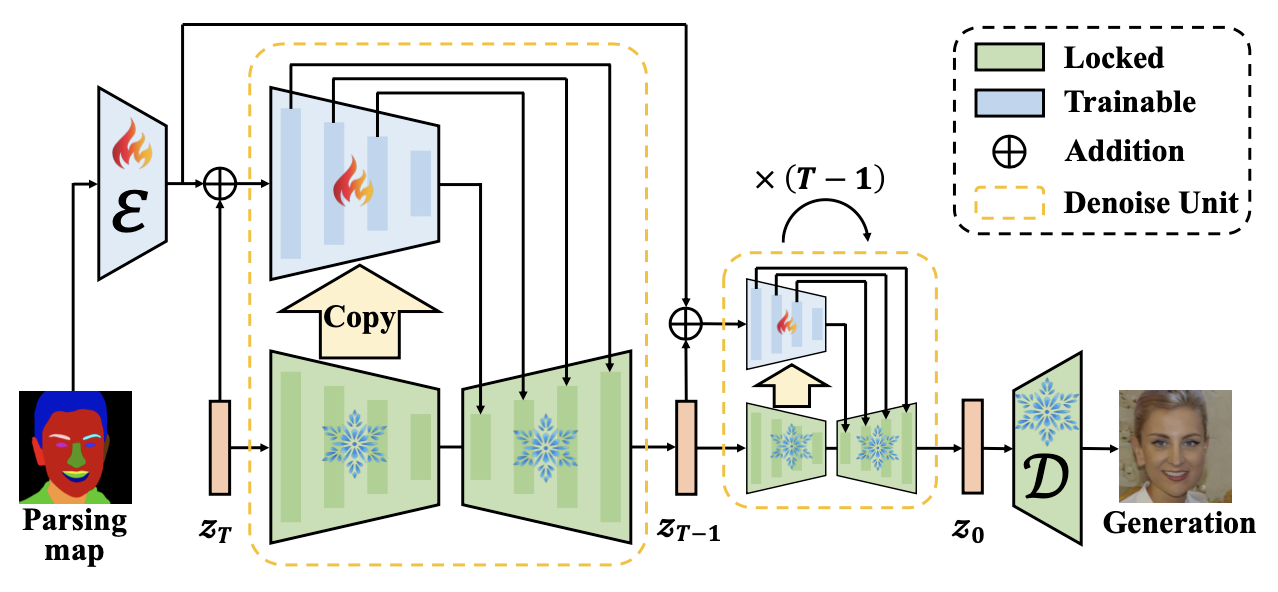
- 浅层退化去除模块 (SDRM) 和多尺度特征提取模块 (MFEM) 可以从低质量人脸图像中去除浅层退化并提取多尺度特征。
- 预训练去噪 U-Net 模块 (PDUM) 利用多尺度特征和可训练时间感知提示模块 (TTPM) 的prompt作为条件,根据输入噪声预测下一步的噪声。
- 经过多个去噪步骤后,可获得高质量潜在特征,随后由预训练解码器VAE将其转换为高质量人脸图像。
3、实验效果
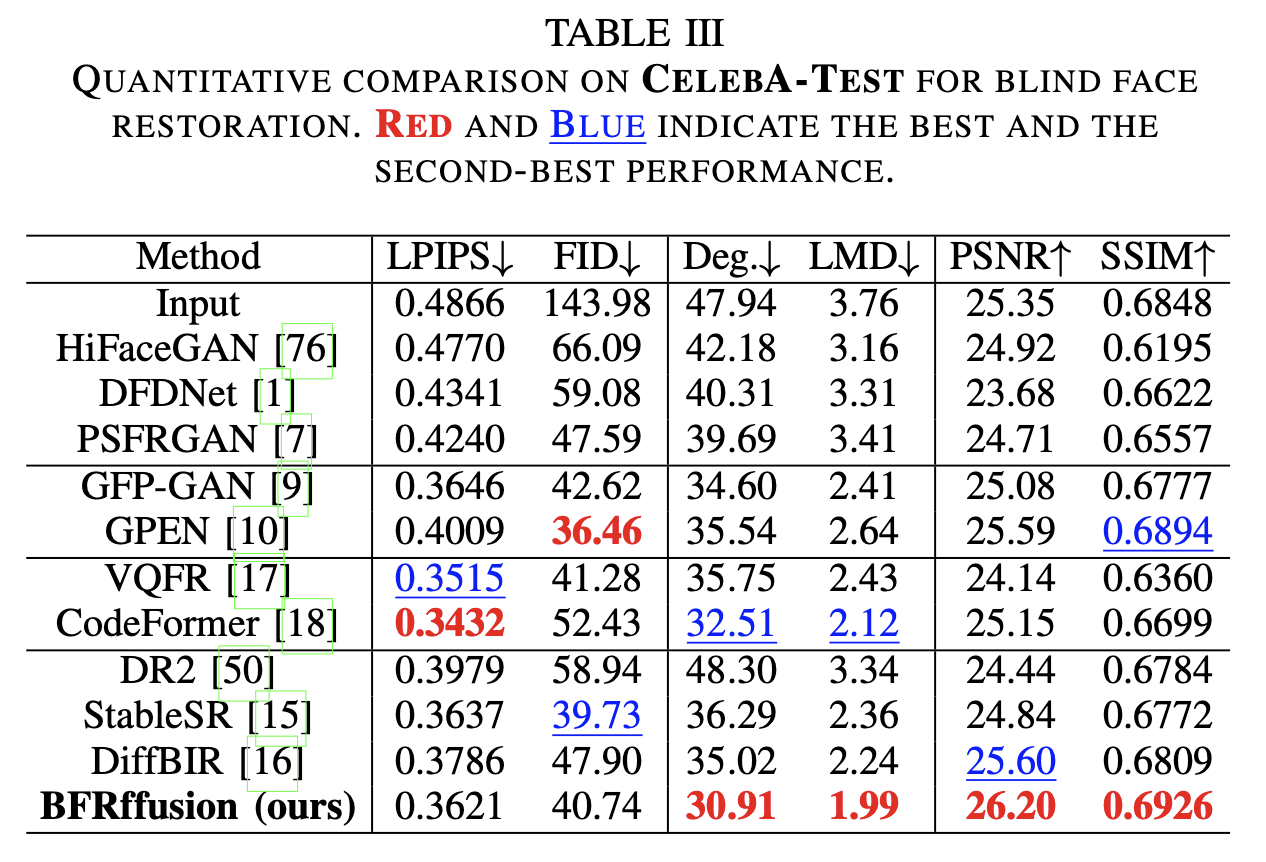
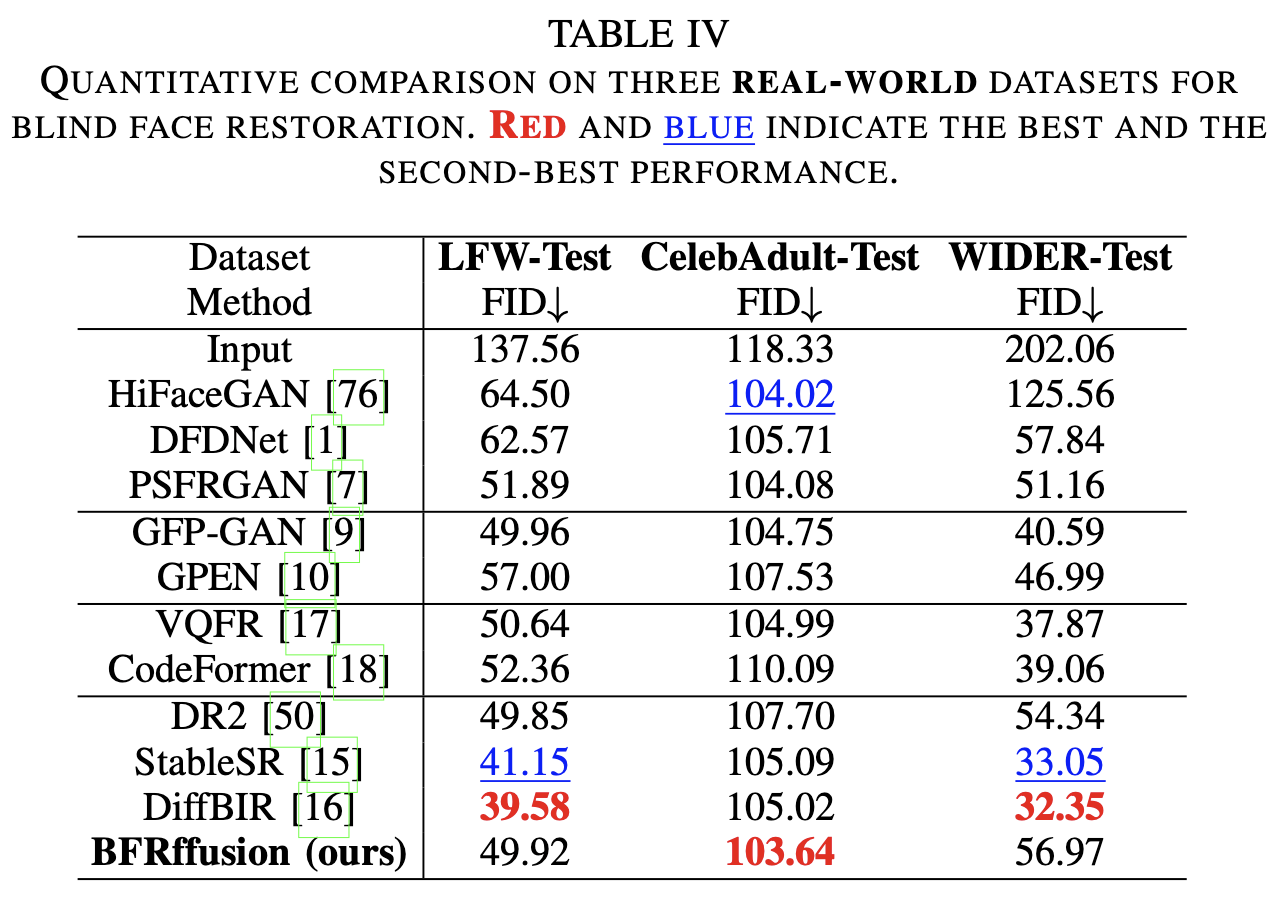
(1)定量评估
(2)定性评估




















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









