






目录
2、Latent Diffusion Models (LDMs)
7、代码解读
1、Diffusion Model概述
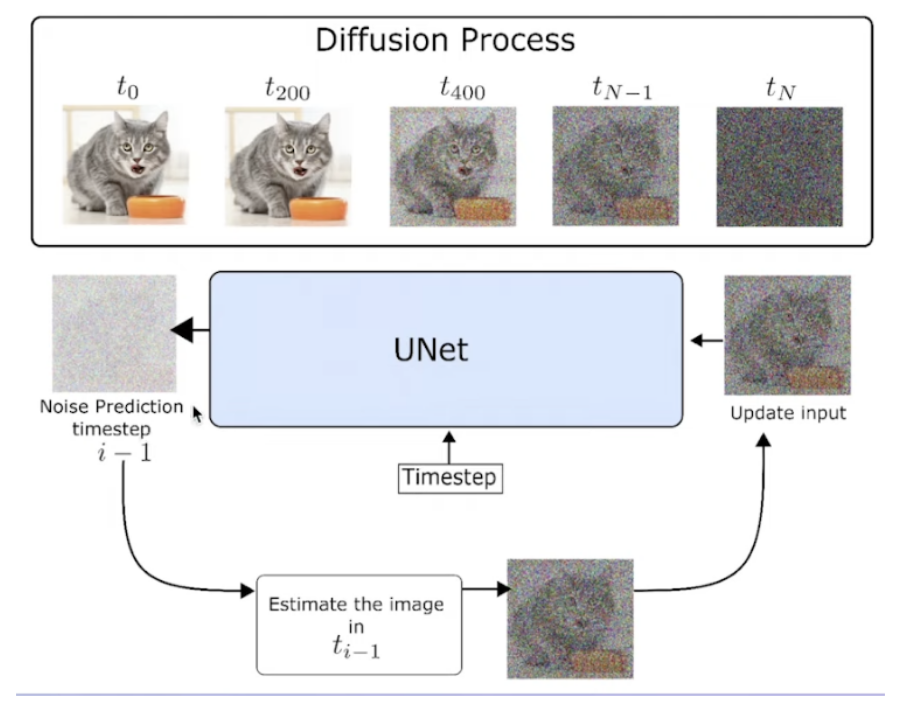
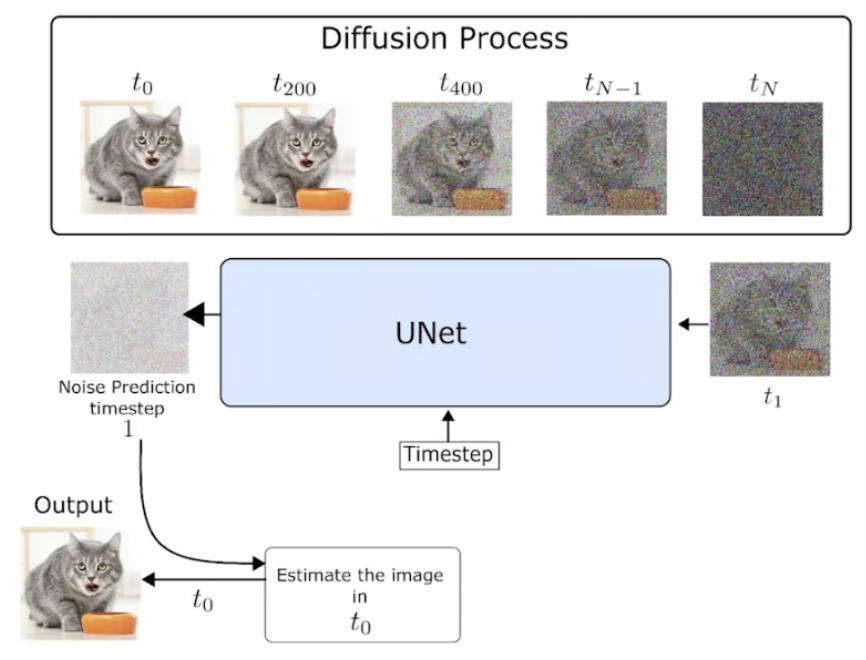
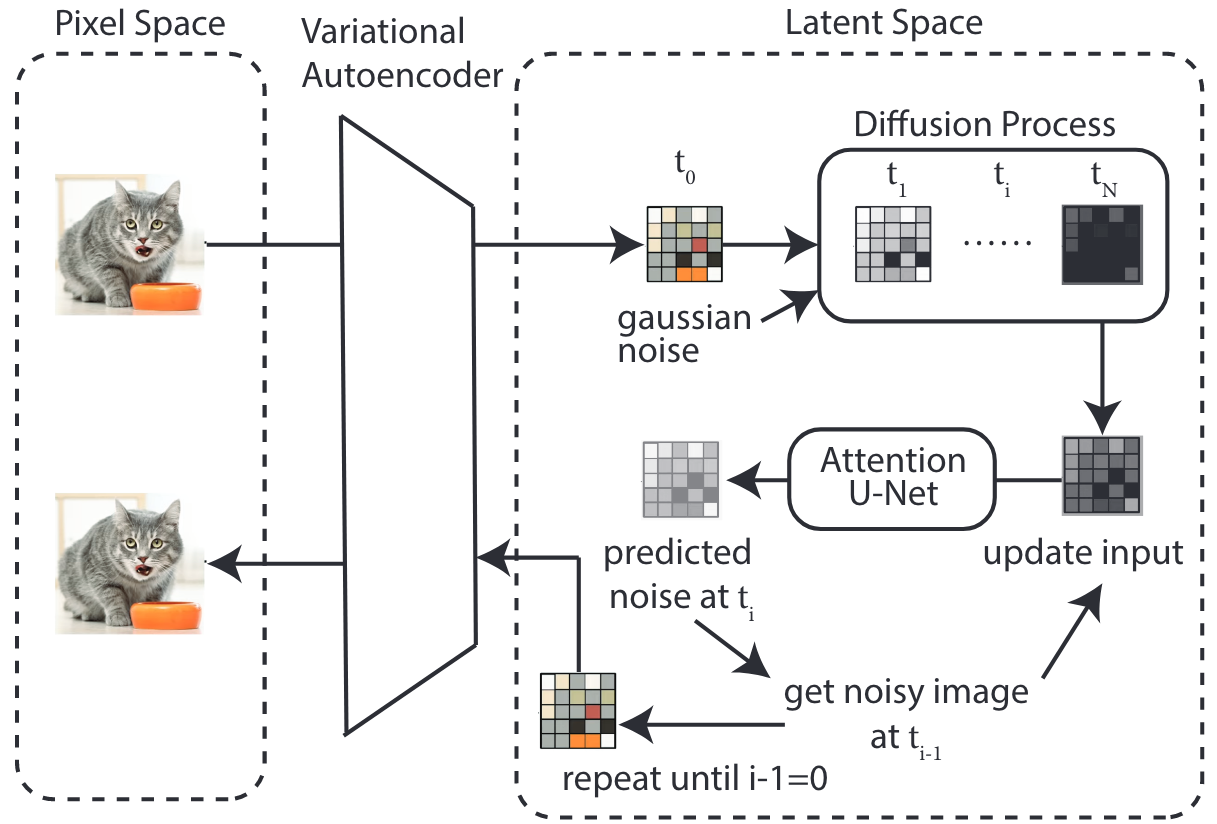
前向扩散过程:迭代地将噪声作用于图像,直至生成完全噪声图像。

后向去噪过程:输入随机噪声(图像大小),使用Unet网络预测上一步添加的噪声,输出上一步的去噪结果,最终输出符合概率分布的生成图像。

通过逐渐对正态分布变量进行去噪来学习数据分布p(x),即学习长度为T的固定马尔可夫链的逆过程:
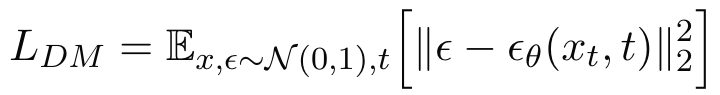
其中t是从(1,2,…,T)中均匀采样得到的,模型可以解释为去噪自动编码器的权重相等的序列(
通常以U-Net形式实现),经过训练来预测xt的去噪版本。扩散模型也能够通过使用条件去噪自动编码器
对条件分布p(x|y)进行建模。
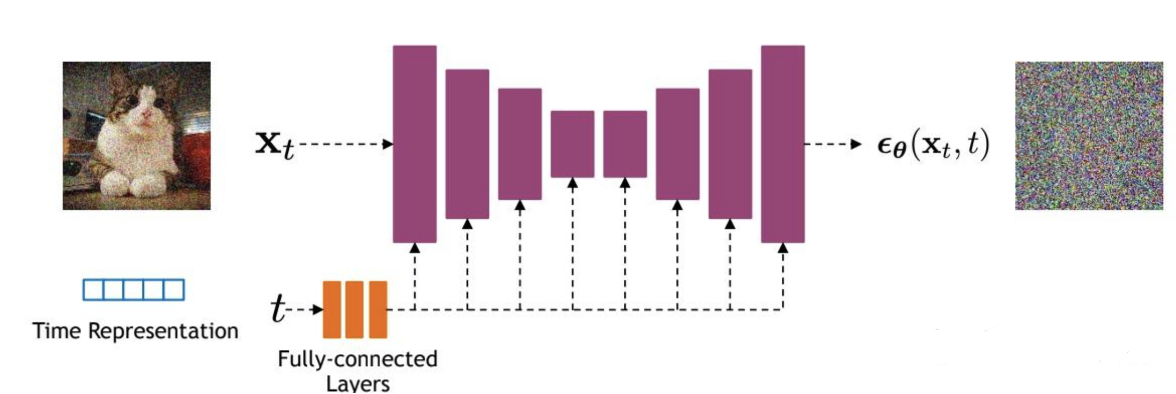
扩散模型理论上需要T个噪声预测模型,但在实际处理时,可以增加一个Time embedding(类似于transformer中的Position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net。
Limitations:
1、训练成本高昂:模型在高维像素空间中执行生成过程,UNet通常具有约800M个参数,训练该模型需要数百个GPU天来,很容易耗费过多的算力来建模难以察觉的细节;
2、推理代价高昂:推理时花费大量时间和内存,且必须按照顺序重复执行相同的架构很多次;
3、扩散模型在图像合成上击败GAN需要150-1000 V100天的训练时间,25-1000个步骤来评估。
2、Latent Diffusion Models (LDMs)
1、创新点
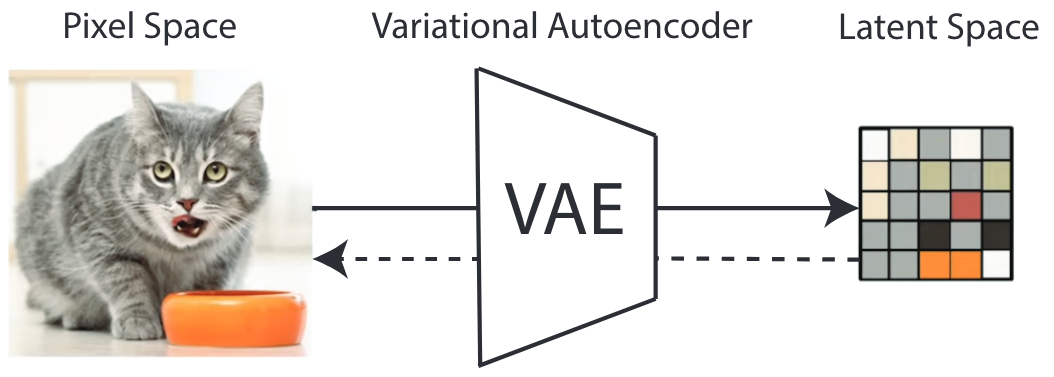
1、在强大的预训练自动编码器的低维潜在空间(感知等效空间)上运行,而不是直接在像素空间上运行(与标准扩散模型相比);
2、成本更低:快速采样、高效训练,只需要训练通用自动编码阶段一次,并且可以从潜在空间中一步解码到图像空间;
3、更灵活:更通用的条件。(对潜在空间的操作可以更容易地添加其他信号。)
2、三大组成部分
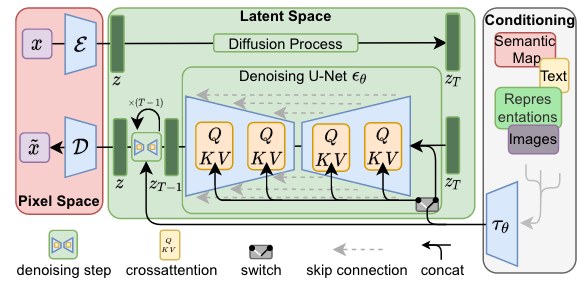
1、自动编码器:变分自动编码器 (VAE),用于处理感知图像压缩。

2、去噪器:潜在扩散模型 (Latent Diffusion Models, LDMs)

其中LDM的主干神经网络为time-conditional attention UNet。
3、条件编码器:比较灵活,可以是任意特定领域的编码器,如VIT,BERT等。
通过交叉注意力机制增强底层UNet主干网络,对于学习各种输入模态的注意力模型非常有效。使用一个特定领域的编码器,将跨模态的condition y投影到中间表示
,然后通过交叉注意力映射到UNet的中间层:
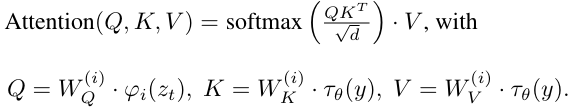
基于Image-Conditioning pairs,通过以下方式学习条件LDM:
![]()
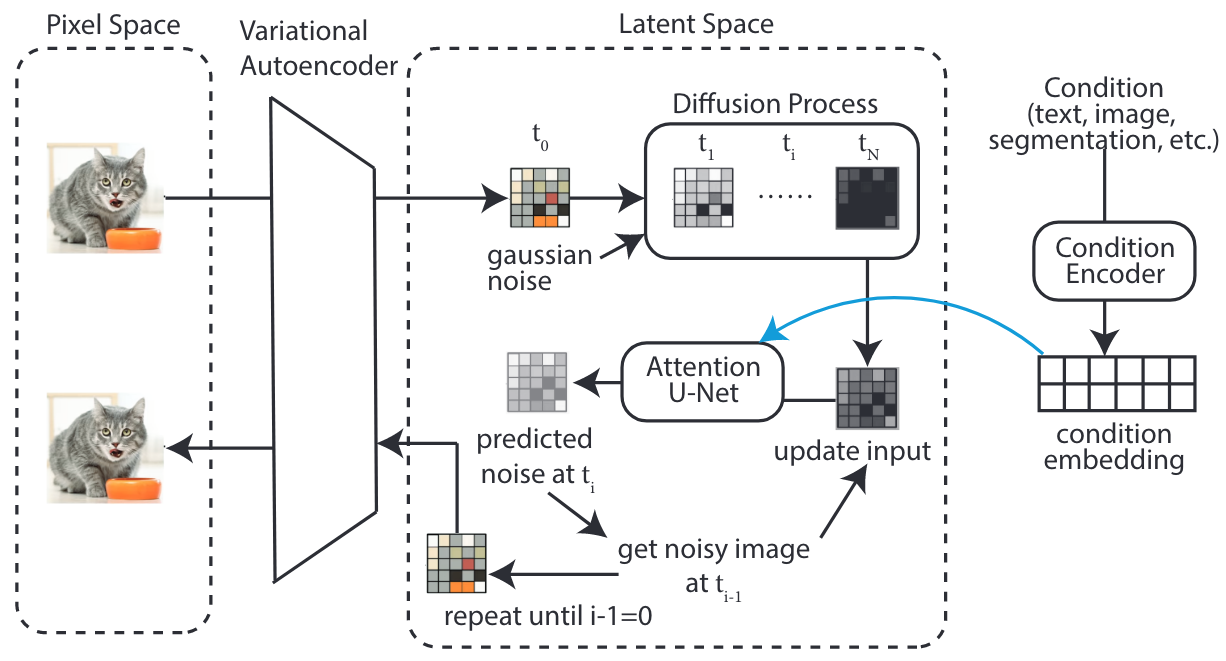
推理阶段:(New-Image Generation)
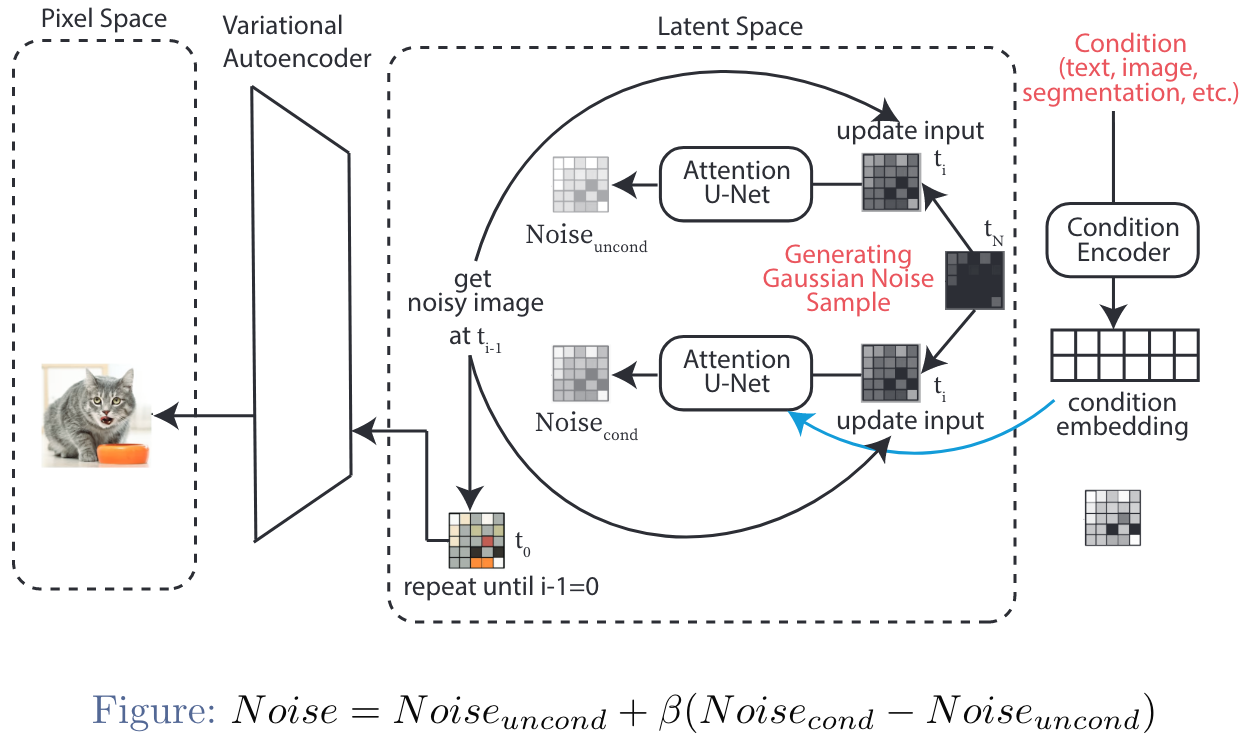
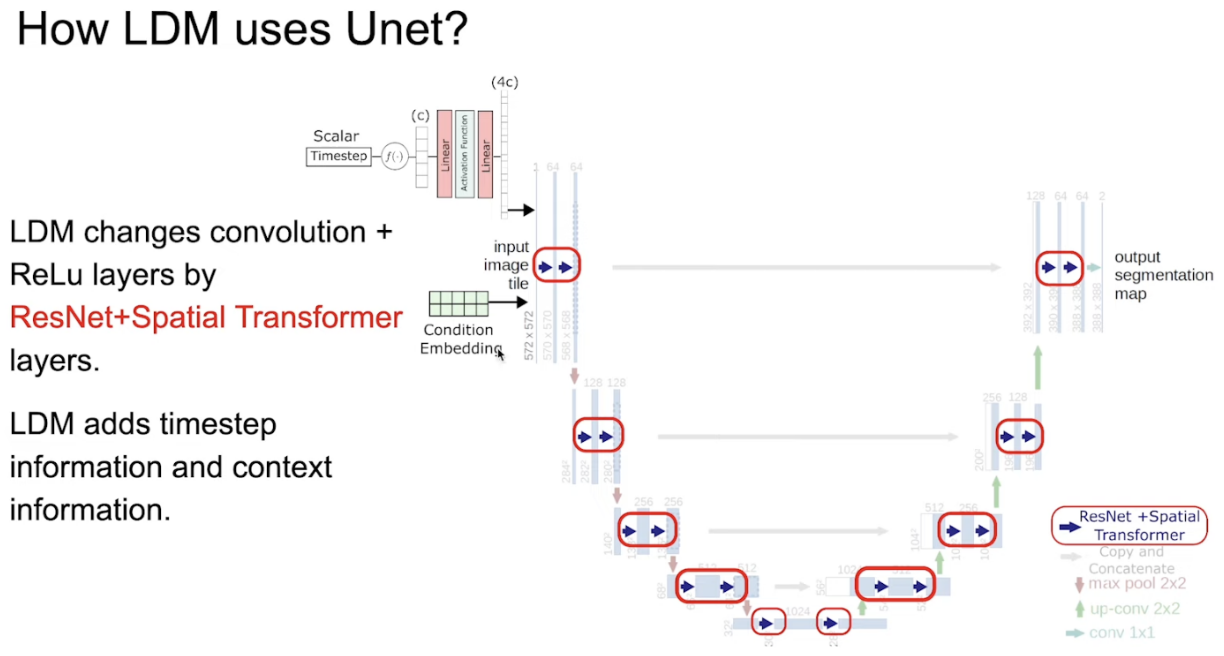
3、LDM中的UNet
CNNs → ResNet + Spatial Transformer
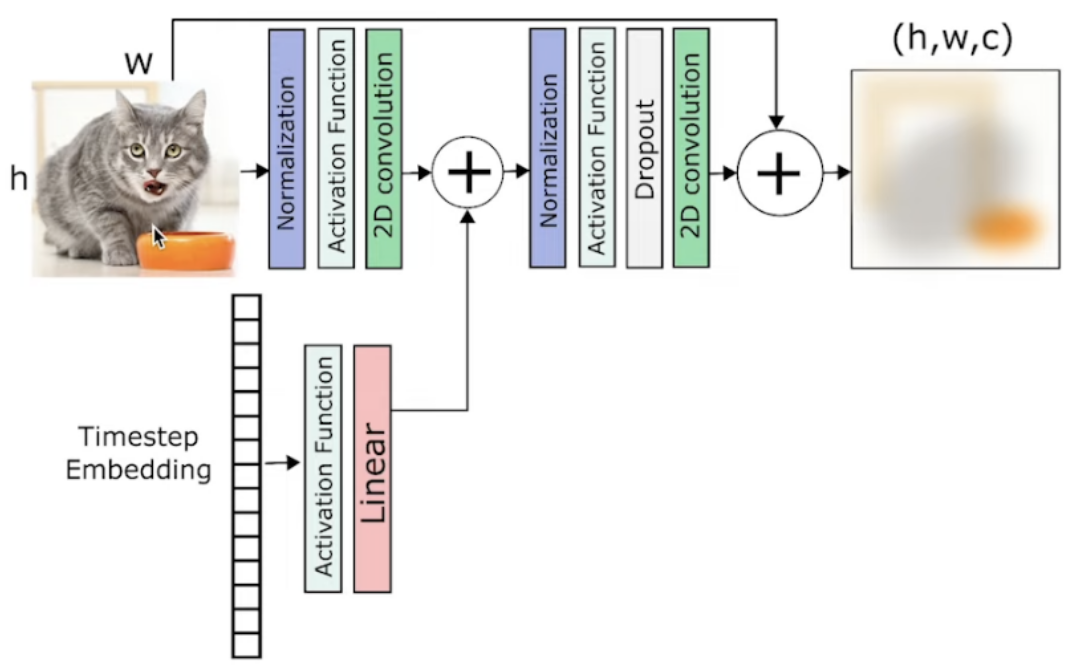
ResNet:(加入时间步embedding)
Spacial Transformer:(加入condition embedding)
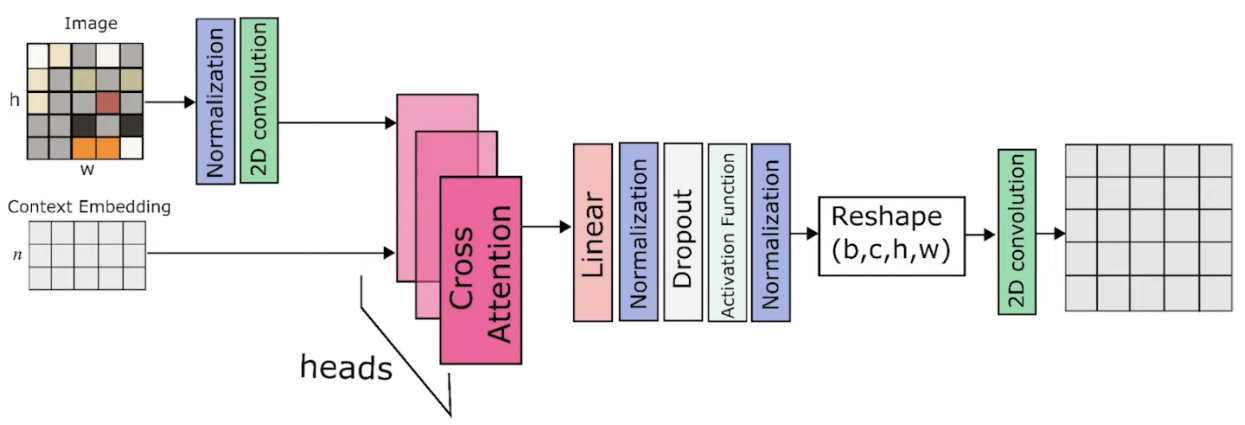
Cross Attention:
Q来自Image embedding,K和V来自condition embedding,通过Context的指导,来调节Image中各个位置的重要性。
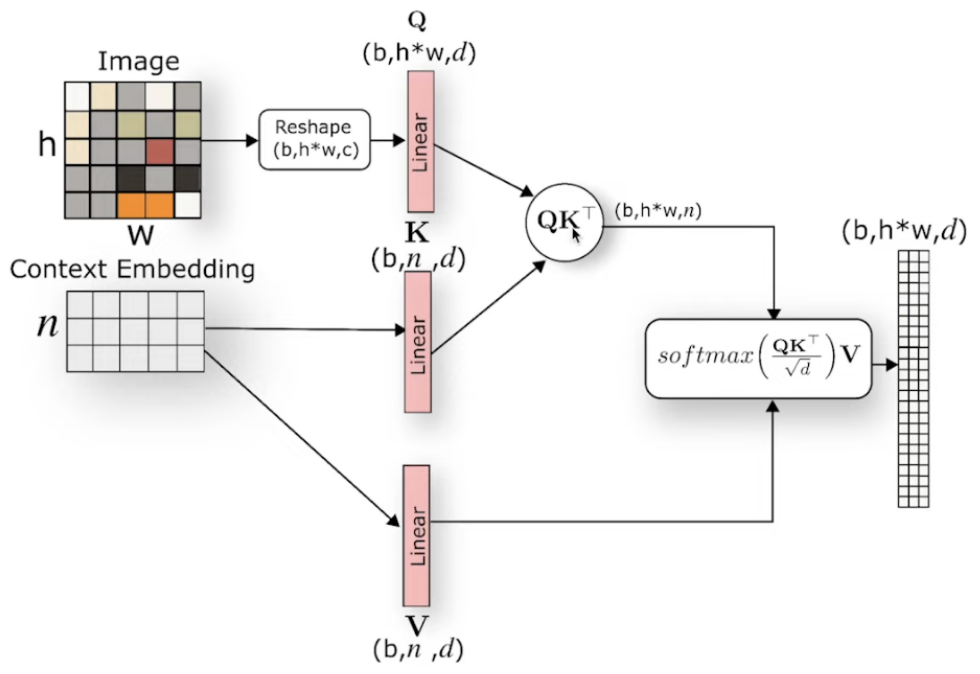
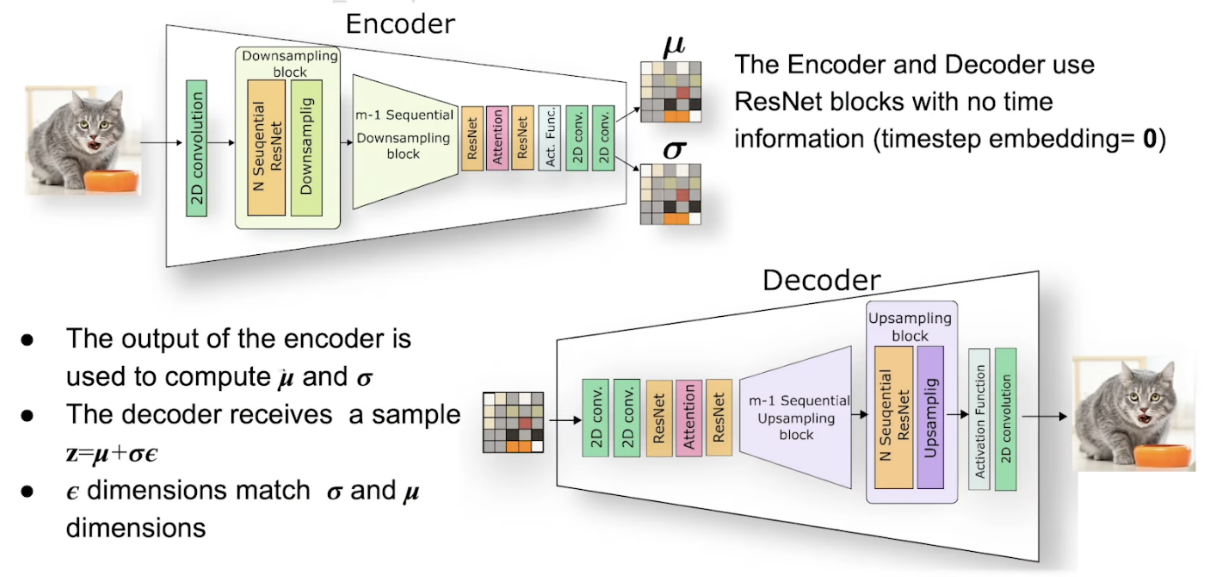
4、Encoder/Decoder
多个Resnet block:
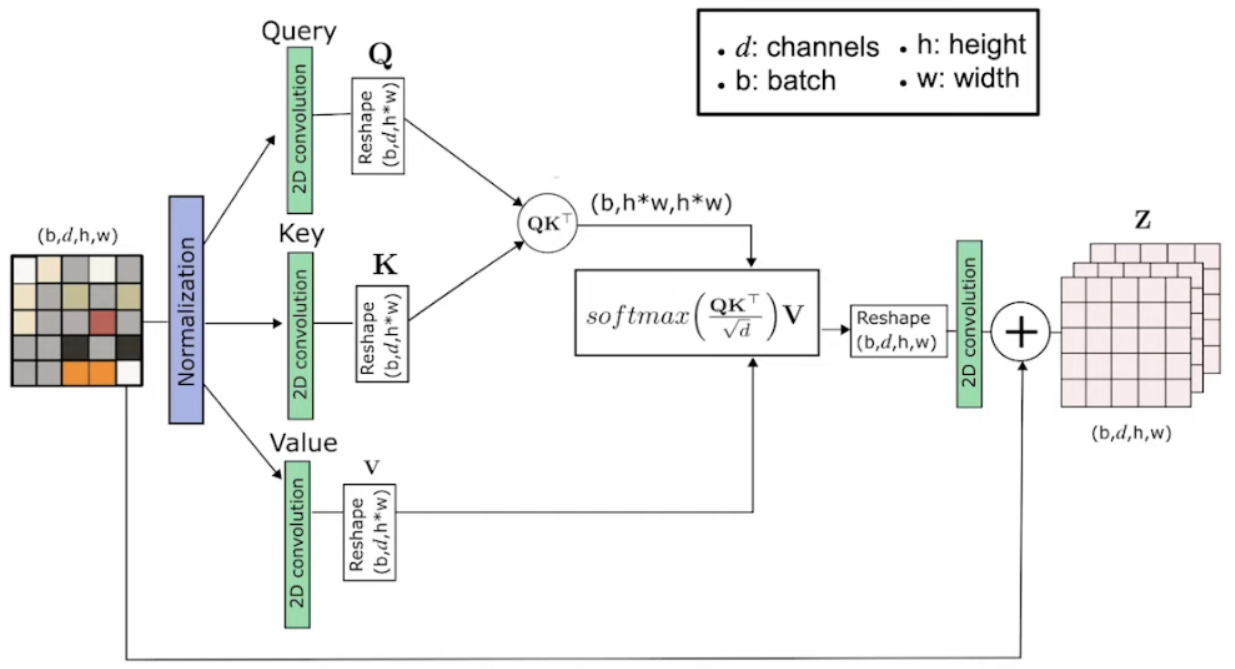
Attention in VAE:
5、Condition Encoder
理论上条件编码器可以是任意的,例如当条件是文本时可以是BERT transformer。条件可以是text或layout,因此LDM选择使用CLIP作为条件编码器。
6、训练过程
三个组件分别进行训练:1、首先训练自动编码器(VAE 和
),此时模型知道如何将图像从像素空间转换到潜在空间。 2、降噪器εθ和条件编码器τθ联合优化。
VAE训练:重参数化策略
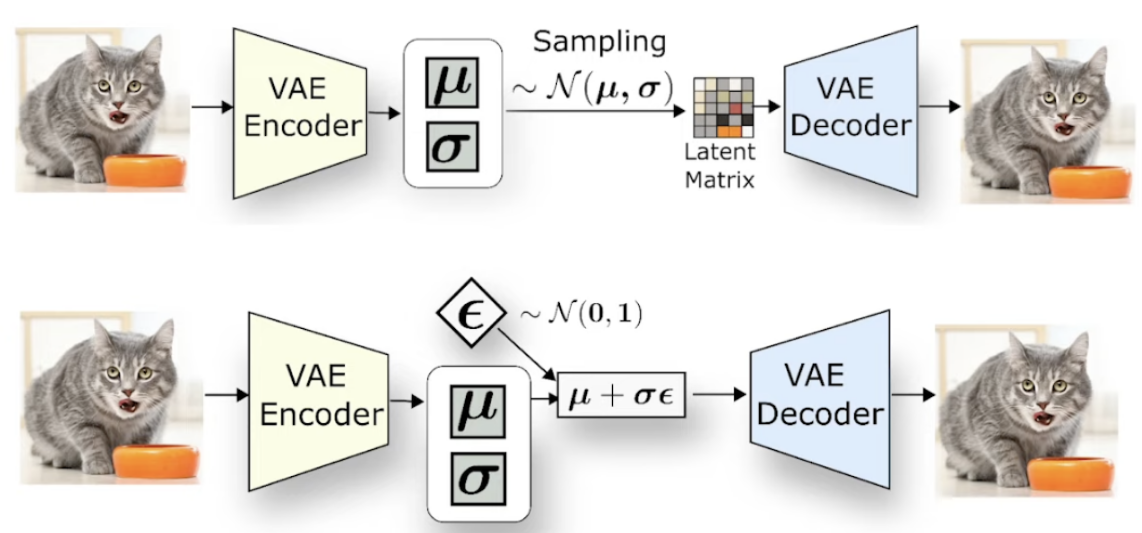
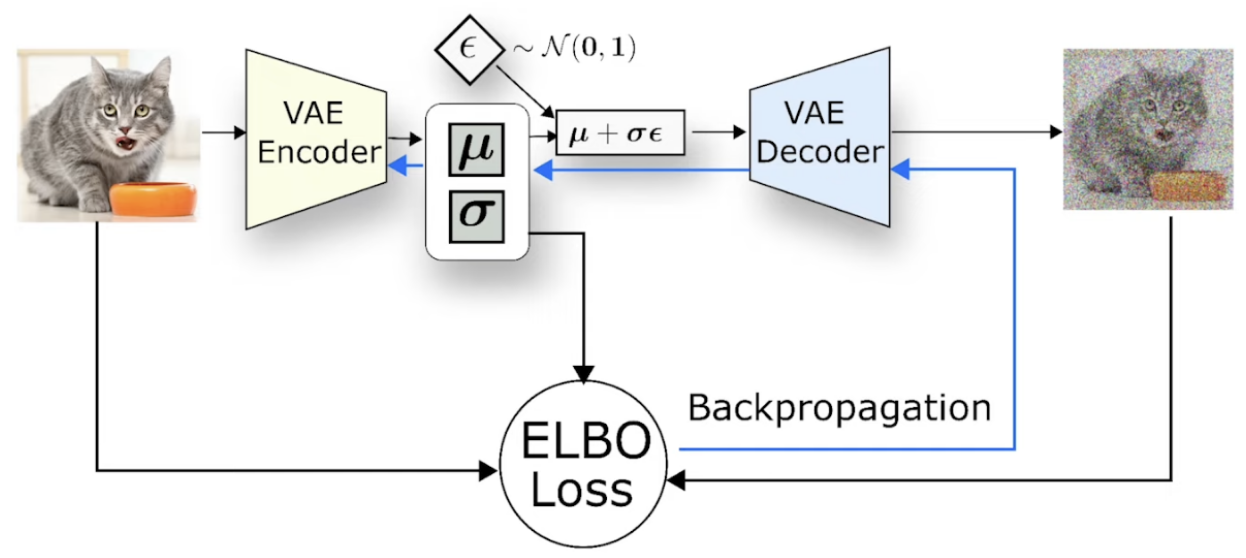
Evidence Lower Bound Objective (ELBO): likelihood(input − output) + KLD(N(μ, σ) || N (0, 1)) + GAN_Loss
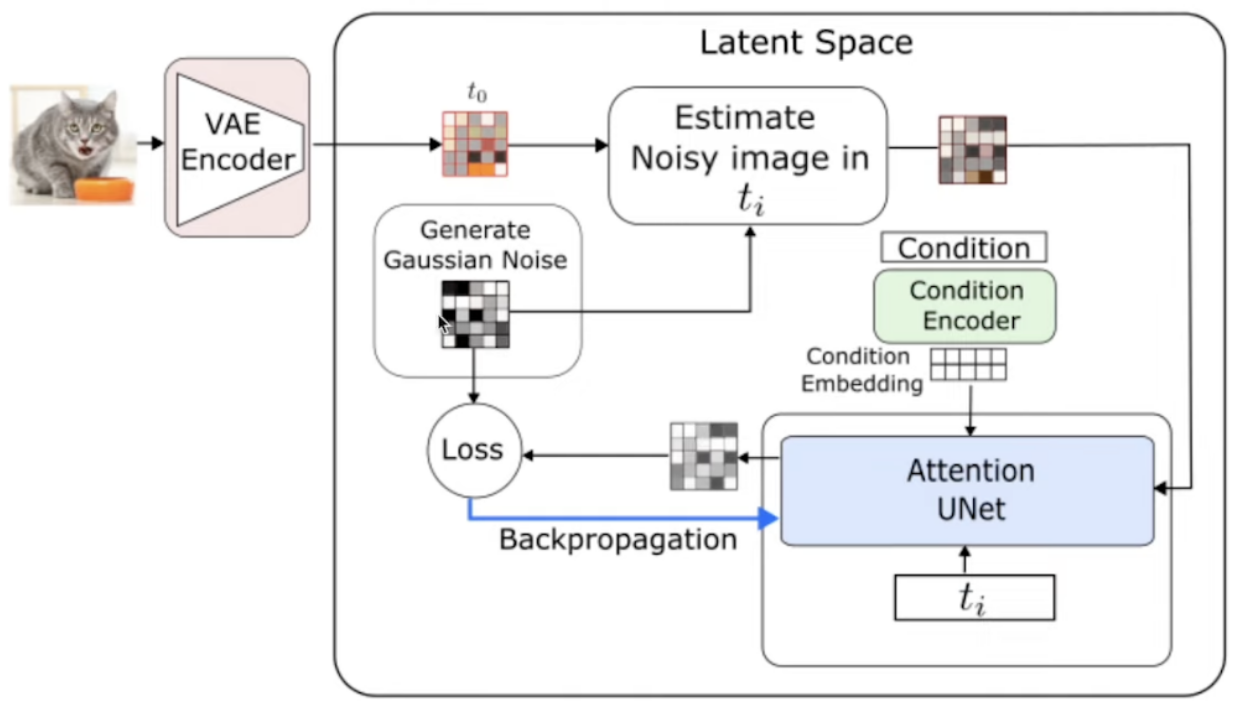
Denoiser(U-Net) Training:这里的Loss可以是任意范数。
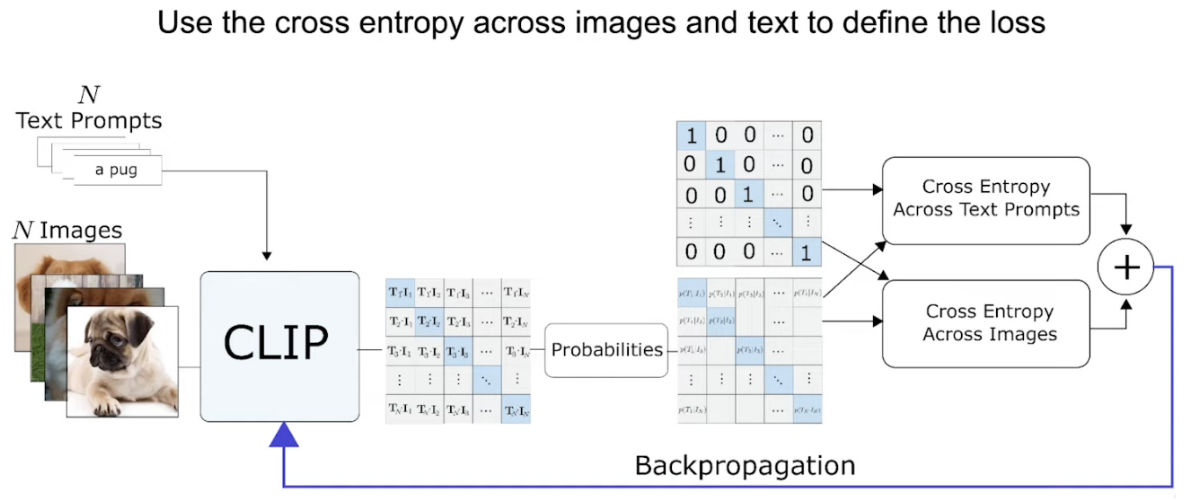
Condition Encoder (CLIP) Training:
Loss = cross_entropy(logits_per_image, labels) + cross_entropy(logits_per_text, labels)
7、代码解读
一文详解 Latent Diffusion官方源码_diagonalgaussiandistribution-CSDN博客


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









