







论文:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/OpenAI/CLIP
CLIP(Constrastive Language-Image Pre-training)
利用自然语言处理的监督信号训练一个迁移性能好的视觉模型,是一个涉及文本、图片的多模态工作。通过学习一个泛化性能好的模型,从而在各种任务和数据集上不需要训练,直接推理(Zero-Shot)就能获得一个不错的结果。
zero-shot learning(零样本学习):指的是模型在没有针对特定下游任务进行微调的情况下,能够直接应用于该任务并做出合理的预测。这种方法通常依赖于模型在预训练阶段学习到的通用知识和特征。
预训练模型:在零样本学习中,模型通常是一个已经在大规模数据集上进行预训练的模型,例如 BERT、GPT、T5 等。这些模型通过学习大量的语言数据,掌握了丰富的语言特征和知识。
下游任务:在实际应用中,某些下游任务可能没有直接的训练数据(例如,特定分类任务或问答任务)。零样本学习的目标是让模型能够使用自己在预训练阶段获得的知识,在没有针对该任务的额外训练数据的情况下,进行有效的推理和预测。
应用场景:在零样本学习中,模型可以通过自然语言描述(例如,任务提示、类别描述或问题描述)来理解和执行新的任务。例如,给定一个文本分类任务,模型可以根据类别的描述(如“体育”、“科技”等)来进行分类,而不需要专门的训练样本。
输入:配对的图像和文本
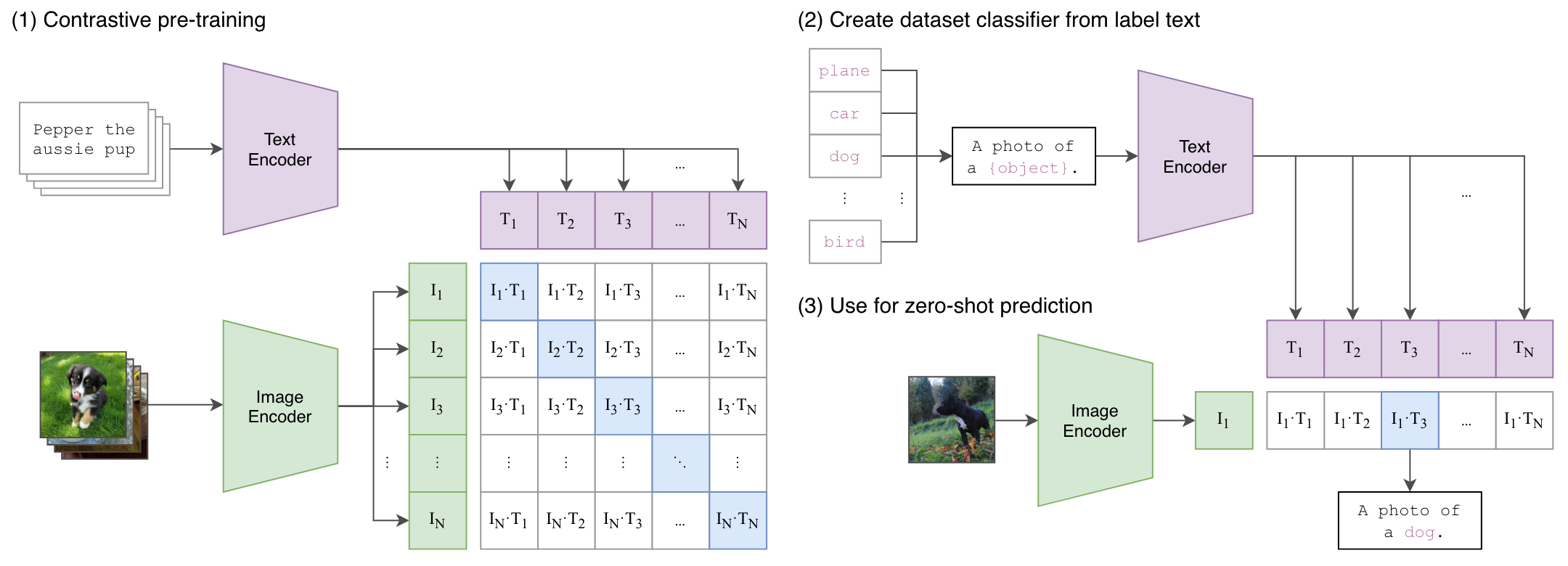
数据集:4亿高质量的图像文本配对(WIT)。
与分类模型不同,CLIP不需要预先定义的类别标签,而是从文本中获取监督信号,通过一个预训练的对比学习模型,提取到多模态的特征,从而得到任意一种类别的结果(泛化性高)。
通过将视觉特征和语义特征联系起来,可以学习到语义特征很强的信息。CLIP已经成功应用于图像生成、检测分割、视频检索等任务中。
1、预训练阶段
提取图像和文本的特征,企图获得图像对应的文本描述,但主观性强,训练困难;
为了放宽约束信号,通过对比学习判断图像和文本的特征是否相似(配对),极大地提升了训练效率。

其中文本编码器使用C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









