







朴素贝叶斯分类
原文地址:http://blog.csdn.net/hjimce/article/details/46054739
作者:hjimce
本篇博文是我学习《机器学习实战》这边书时候的学习笔记。记得之前看到这个算法名的时候,我以为很难,因为我不是很喜欢概率论的知识,其实最主要的原因是因为已经概率论的相关知识都忘光了,所以一直不想去复习,于是就觉得这个算法不好学。不过前段时间遇到了利用概率论的方法,进行图像分割与识别,最后被项目逼得走投无路了,只好去简单的复习一下概率论的一些知识。有的时候是因为懒惰,所以才一直觉得难,其实如果你决心学习一个算法,都只是一两天的事。
开始学习这个算法前我们需要复习一下一些概率论的知识。
一、基础知识复习
1、相互独立事件:假设A、B相互独立,那么有:
P(AB)=P(A)*P(B)
2、 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。贝叶斯准则告诉我们,如果已知P(A|B),要求P(B|A),那么我们可以使用如下计算公式:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。贝叶斯准则告诉我们,如果已知P(A|B),要求P(B|A),那么我们可以使用如下计算公式:

为了复习一下这个公式,我这里举个示例:假设现分别有 A,B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器 A 的概率是多少?假设已经抽出红球为事件 B,从容器 A 里抽出球为事件 A,则有:P(B) = 8 / 20,P(A) = 1 / 2,P(B | A) = 7 / 10,按照公式,则有:P(A|B)=(7 / 10)*(1 / 2)/(8/20)=0.875。
二、算法实现
1、问题描述:假设我们要用这个算法实现二分类,类别为C={C1,C2},现在有个数据X(x1,x2……xn),我们要判断X属于哪个类。
2、分类原理:我们现在用p1(X)表示X属于C1的概率,p2(X)表示X属于C2的概率。
那么我们可以根据:一下规则来判断它的类别
如果P1(X)>P2(X) 则数据点X属于类别C1;
如果P1(X)<P2(X) 则数据点X属于类别C2;
因此其实贝叶斯分类算法的主要目标就是计算待判别的数据点X属于各个类的概率,然后求取概率最大的那个类别,就是我们的分类结果。其实这个原理我们在平时生活中,无形当中经常用到。假设有个人,已知其性别为男的概率为0.3,性别为女的概率为0.6 ,为人妖的概率为0.1,那么这个时候,你肯定会把这个人的性别判别为女性,这个就是朴素贝叶斯的思想。因此我们的主要问题就是计算数据点X(x1,x2……xn)属于各个类的概率。因为我们是需要根据已知的X的数据特征x1,x2……xn进行判别的,因此其实这个是一个计算条件概率问题,就是计算在特征x1,x2……xn发生的情况下,各个类别发生的概率。
那么我们上面的问题最主要的就是要求解如下条件概率事件:
P1(C1|X)=P1(C1|x1,x2……xn),在啰嗦一遍,这个公司的含义是已知特征x1,x2……xn同时发生的情况下,C1发生的概率。OK,接着我们就要对这个公式展开计算:

同理X属于C2的概率为:
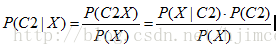
我们的目的是判断P1(C1|X)、P1(C2|X)哪个比较大,选择比较大的数,作为对应类的判别。由于上面计算公式P1(C1|X)、P1(C2|X)中分母是相同的,因此我们只需要计算分子就可以了,故我们问题转换为计算P(X|C1)*P(C1)、P(X|C2)*P(C2),并比较其大小。
在朴素贝叶斯中有一个假设,那就是各个特征x1,x2……xn之间是相互独立的,因此P(X|C1)=P(x1|C1)*P(x2|C1)*……P(xn|C1)。故
P(X|C1)*P(C1)=P(x1|C1)*P(x2|C1)*……P(xn|C1)*P(C1)
同理:
P(X|C2)*P(C2)=P(x1|C2)*P(x2|C2)*……P(xn|C2)*P(C2)
OK,这个就是我们最后需要计算的公式了,我们接着要做的事就是,就是要想怎么计算P(Ci)、P(xj|Ci)。好好思考一下这个两个是个什么鸟东西。P(Ci)表示类别Ci发生的概率,P(xj|Ci)表示在类别Ci中,xj发生的概率。现在假设给我们训练数据,我们就是要利用统计的方法,统计训练数据,计算这两个概率。
示例:看一下下面的训练数据,如何计算上面的P(Ci)、P(xj|Ci)

现在给定一个新ID用户,拥有房产、已婚两个已知特征,我们希望根据这两个特征信息,推断出这个人是否偿还债务。从上面的数据我们可以统计P(Ci),未偿还债务的概率P(C0)=7/10 ,偿还债务的概率为P(C1)=3/10。
在未偿还债务的情况下,拥有房产的概率为:P(x1|C0)=3/7。同样我们也可以计算未法偿还债务的情况下,已婚的概率为:P(x2|C0)=4/7。最后我们就可以求得:
P(X|C0)*P(C0)=P(x1|C0)*P(x2|C0)*P(C0)=0.7*(3/7)*(4/7)
同样的我们也可以求得P(X|C1)*P(C1),最后比较一下大小,得到最大的概率类,这个算法就结束了。
3、算法流程:
(1)根据训练数据,统计每个类别Ci的发生概率,P(Ci)。
(2)计算每个特征属性各个类别的条件概率,P(xj|Ci),这个需要计算的比较多,比如上面的例子不考虑年收入特征,已偿还债务的条件下,我们就需要计算 有房、没房、已婚、未婚四种概率情况。
(3)对于给定的待分类数据X,对每个类别分别计算P(X|Ci)*P(Ci)。
(4)求取概率最大的那个一类别,作为最后的X类别判别结果。
4、连续型特征
在上面的例子中,我故意避开了年收入这个特征,是因为年收入是连续型的数值,因此我们无法直接使用简单的统计。当特征值为连续值时,这个时候我们通常假设其对于某个类别服从高斯分布,即:

根据这个公式我们可以计算出给定一个年收入数值,计算其概率。当然前提是我们需要先利用已知的训练数据做一个统计,对于我上面的例子,我们就是要计算出在未偿还债务的条件下,计算出其年收入的均值与方差;同理,在已偿还债务的情况下,统计训练数据中,年收入的均值与方差。这样就可以计算得到年收入对应各个分类的条件概率了。
三、朴素贝叶斯分类实例:检测SNS社区中不真实账号
为了更好的理解这个算法,这里我引用一篇博客的例子,本示例引用自作者张洋,博文链接为:算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification) - T2噬菌体 - 博客园 ,因为这个例子简单易懂,所以跟大家分享下,帮助大家理解应用这个算法。
有这样的一个问题,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2},a1:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a=0(不是),a=1(是)}。
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:

4、计算每个类别条件下各个特征属性划分的频率

5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。

可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
四、代码实战-简单文本分类
1、朴素贝叶斯代码实现
from numpy import *
#创建词典 也就是创建包含文档中所有盖含的单词,用于后面的向量化
def Createvocalist(docall):
cv=set([])
for everydoc in docall:
cv=cv|set(everydoc)
return list(cv)
#文档向量化
def Word2vec(doc,dic):
docvec=[0]*len(dic)
for everyword in doc:
if everyword in dic:
docvec[dic.index(everyword)]+=1
else:
print 'the word:%s is not in dictionary' % everyword
return docvec
#贝爷斯分类数据训练,计算每个特征(单词)出现的概率,计算每个类的概率
def Bayestrain(docall,cla,dic):
docallvec=[]
for i in range(len(docall)):#先把训练文档向量化
docallvec.append(Word2vec(docall[i],dic));
#因为p(c1)*p(x1|c1)*p(x2|c1)*p(x3|c1)*……中如果有一个为0,整个也为0,这样缺少稳定性,
#因此把每个特征的初始设置为1,增加稳定性
pc1x=ones(len(dic))
numword1=float(len(dic))#把总单词数的初始值设为dic的长度
pc2x=ones(len(dic))
numword2=float(len(dic))
for i in range(len(docallvec)):
if cla[i]==1:#类别为1的文档,相关特征频率统计(词频统计)
pc1x+=array(docallvec[i])
numword1+=sum(array(docallvec[i])) ;
else:#类别为0的文档,相关特征频率统计(词频统计)
pc2x+=array(docallvec[i])
numword2+=sum(array(docallvec[i])) ;
#计算各个类别出现的概率
pc1=sum(cla)/float(len(cla));
#取对数 因为pc1x、pc2x大部分都是非常小的数,累乘估计会变为0
#因此概率log(p(c1)*p(x1|c1)*p(x2|c1)*p(x3|c1)*……)=log(p(c1))+log(p(x1|c1))+log(p(x2|c1))……
return log(pc1),log(pc1x/numword1),log(1-pc1),log(pc2x/numword2)
#输入文档分类决策
def Classify(doc2vec,pc1,pc1x,pc2,pc2x):
p1=sum(array(doc2vec)*pc1x)+pc1;
p2=sum(array(doc2vec)*pc2x)+pc2;
if p1>p2:
return 1
else :
return 02、简单测试:
#训练数据 人为创建
def loadDataSet():
#训练文档,训练数据创建
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],#文档1
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],#文档2
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #训练文档的标签
return postingList,classVec
#数据训练
docall,cla=loadDataSet()
dic=Createvocalist(docall);
pc1,pc1x,pc2,pc2x=Bayestrain(docall,cla,dic)
#贝叶斯决策测试
testdoc=['love','my','dalmation']
testdoc=['stupid','garbage']
test2vec=Word2vec(testdoc,dic)#向量化
print Classify(test2vec,pc1,pc1x,pc2,pc2x)****************作者:hjimce 联系qq:1393852684 更多资源请关注我的博客:hjimce_深度学习,深度学习,基础知识-CSDN博客 原创文章,转载请保留本行信息。******************
参考文献:
1、http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
2、《机器学习实战》















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









