









作者:Ross Girshick
ICCV 2015
概要
FastRCNN是RCNN和SPPnet的改进版。Fast RCNN在训练的时候比RCNN快9倍,比SPPnet快3倍;测试的时候比RCNN快213倍,比SPPnet快10倍。最后在PASCAL VOC 2012上达到66%的mAP。
RCNN与SPPnet存在的缺点
1. 训练是多阶段的。先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bounding-box regression。
2. 训练非常耗费时间和空间(存储)。在训练SVM和bbox regression的时候,需要先将之前提取出来的特征写入磁盘中,这些特征需要花费的空间很大;这个过程也非常耗费时间。
3. 物体检测非常慢。测试的时候,特征需要从每个图片中的每个proposal提取,使用VGG16网络大概每张图片耗费47s(在一个GPU上)。
Fast RCNN的优点
1. 比RCNN,SPPnet有更高的准确率(mAP)。
2. 训练是单阶段的,使用多任务的loss。
3. 训练可以更新所有的网络层(SPPnet只能更新fc层)。
4. 特征缓存的时候不需要硬盘存储。
Fast RCNN结构与训练

第一步,将这个完整的图片经过若干卷积层与max pooling层,得到一个feature map。
第二步,用selective search算法从这完整的图片中提取出object proposals,即RoI。
第三步,根据映射关系,可以得到每个object proposal对应的feature map。
第四步,将第三步得到的feature map经过RoI pooling layer得到固定大小的feature map(变小了)。
第五步,经过2层全连接层(fc),得到固定大小的RoI特征向量。
第六步,特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax,第二个是每一类的bounding box回归。
简要流程图如下:

说明:在训练的时候,分类与回归是一起训练的,总的loss是分类的loss加上回归的loss。计算公式如下:
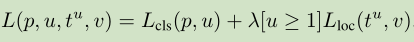
在本文中λ取1,详细情况可以查看论文。
关于RoI pooling layer
这是SPP pooling层的一个简化版,只有一级“金字塔”,输入是N个特征映射和一组R个RoI,R>>N。N个特征映射来自于最后一个卷积层,每个特征映射都是Hx W x C的大小。每个RoI是一个元组(n, r, c, h, w),n是特征映射的索引,n∈{0, ... ,N-1},(r, c)是RoI左上角的坐标,(h, w)是高与宽。输出是max-pool过的特征映射,H' * W' * C的大小,H'≤H,W'≤W。对于RoI,bin-size = h/H' * w/W',这样就有H'*W'个输出bin,bin的大小是自适应的,取决于RoI的大小。
下图中,H'=W'=3

参考文章:















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









