







 Fast R-CNN是Ross Girshick提出的针对R-CNN的改进算法,提高了目标检测的速度和精度。它采用多任务损失函数进行一站式训练,包括分类和边界框回归,并引入ROI pooling层。实验表明,Fast R-CNN相比R-CNN在速度和mAP上有显著提升。
Fast R-CNN是Ross Girshick提出的针对R-CNN的改进算法,提高了目标检测的速度和精度。它采用多任务损失函数进行一站式训练,包括分类和边界框回归,并引入ROI pooling层。实验表明,Fast R-CNN相比R-CNN在速度和mAP上有显著提升。
目标检测 Fast R-CNN 论文笔记
摘要
- 此篇文章是 Ross Girshick 大牛在微软研究所单撸出来的一篇文章。基于14年 R-CNN 的大获成功,作者提出了其改进算法 Fast R-CNN 。Fast R-CNN 在VGG16 network下训练速度比R-CNN快了9倍,测试时间更是缩短了213倍,不仅如此,mAP也达到了最高水平。作者也在github上传了源码,可以点此下载。
简介
- 对R-CNN尚不了解的同学可以看看这里。简而言之,R-CNN实现的分成这么四步:
- 利用 selective research 在一张图像中选出2000个候选框(即可能存在目标的区域);
- 将每个候选框 warp 成固定大小的图像(例如227*227),送入CNN提取4096维的 feature map;
- 对于这2000个 feature map ,利用SVM分类器进行分类,判断它是属于某个特定类还是背景;
- 使用回归器进一步调整边界框的位置。
- 作者认为目标检测的高复杂度源于两个问题:一是无数的候选框都要被运行一次,以判定其类别;二是这些候选框只提供了一个大致位置,后期还需要细调。
- 传统的R-CNN已经做得很好了,但还是存在几个问题:
- 训练是一个多阶段过程。R-CNN的训练分成三步(和实现不一样!),先训练CNN网络,再训练SVM,再训练边界框回归。这样实在有点复杂;
- 训练耗时又耗空间。 在诸如VGG16的深度网络下,程序可能要花几天来训练,生成的特征图也多达几百G;
- 目标检测速度慢。如果使用VGG16,在GPU下一张图需要47秒来检测。
- 之后有人提出 SPPnet 来改进R-CNN的速度。一张图片通过CNN**只生成一个公用的feature map**,而不是每个候选框都生成一个。然而,SPPnet的缺点还是很明显。
- 基于R-CNN和SPPnet的缺点,作者再次提出了Fast R-CNN,它具有如下优点:
- 更高的mAP;
- 训练只有一个阶段,且使用multi-task loss;
- 训练可以更新所有的网络层;
- 不需要硬盘来缓存特征图。
网络结构和训练策略
- 论文中给出的网络结构图如下图。首先,网络的输入有两个:原始图像和候选区域(region of interest, ROI)。首先,卷积网络对整张图像提取出提取出feature map;接着,每个ROI都通过生成的这feature map提取出一段特征向量,且通过ROI pllling层框定尺寸;最后,每个特征向量通过全连接层(FC)输出两个内容:softmax分类和边界框。

ROI pooling
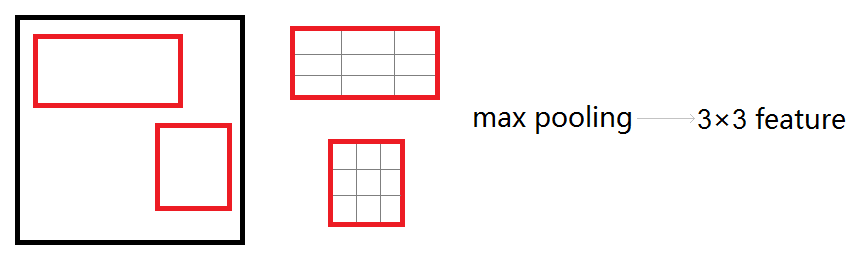
- ROI pooling是本文章中的一个重点,它实现的功能是将任意大小的矩形区域通过池化转变为统一的尺寸。在此借用 shenxiaolu1984大神博客 的示意图。可以看见,假如输出固定尺寸是H * W,则上一层的任何一个矩形框ROI都被平均分割为H * W个小块,每个小块进行一次max pooling操作,选出小块中的最大值。
多任务损失
- 由网络结构可知,输出有softmax分类和边界框两个。作者设定了一个multi-task损失来衡量两个输出和真实值的差异。损失函数如下表式:
L(p,u,tu,v)=Lcls(p,u)+λLloc(tu,v) - 其中,p是输出的预测分类,u是真实分类;
tu
是一个长度为4的数组,代表预测的边界框位置,v是真实的边界框位置,
λ
是正则项,一般设为1。
- 第一个类别损失就是我们熟知的softmax回归器: Lcls(p,u)=−log(pu)
- 第二个边界框损失的定义为:
Lloc(tu,v)=∑i∈x,y,w,hsmoothL1(tui−vi)
其中
- 由于背景的特殊性,当u为背景时, λ 被设为0,否则为1。
batch 采样策略
- 既然采用了随机梯度下降算法(SGD),每次迭代都需要生成一定数量的batch。作者的方法是先随机选择两张图,每张图里采样64个ROI。由于同一张图里的ROI正反向传播参数相同,因此可以节省时间,同时也不会出现人们担忧的收敛过慢的问题。
- 另外,在这么多ROI里,前景的比例为25%,背景的比例为75%。前景的定义是IOU达到0.5以上。这样做也考虑到了实际图中前景和背景的比例。
尺度不变策略
- 这一块看的不是很明白,作者探索了两种尺度不变的方法:“brute force” learning 和 图像金字塔。
Fast R-CNN 检测
- 文章中这一块看的也不太清楚,但这应该只是提速的方法。不看的话对整体理解并无大碍,所以先放在这里了。
实验结果和结论
- 实验结果就不多说了,肯定是比之前其他方法更快、更高、更强。下面只说一说作者通过实验得出的一些结论:
- 多任务训练与单独训练分类相比,可以将mAP提高0.8-1.1左右;
- 使用多尺度的图像金字塔,对提高mAP基本没有帮助;
- 增加训练数据,可以将mAP提高2%-3%左右;
- 在FAST R-CNN中,使用softmax效果略好于SVM;
- 更多的候选框不但没有帮助,甚至会降低准确率;















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









