







转载请注明出处:
http://blog.csdn.net/Hk_john/article/details/78455889
给出完整代码:(请需要的自行下载,有问题请留言)
http://download.csdn.net/download/hk_john/10105643
pudn下载连接:
http://www.pudn.com/Download/item/id/3304126.html
有时间会写一下百度图片和谷歌图片的python爬虫博客,先占行
google图片爬虫连接:
http://blog.csdn.net/Hk_john/article/details/78581748
百度图片爬虫连接:
这段时间在实习,在做一些各大网站图片爬取的工作,基本告一段落,现在分别对百度图片,google图片,并应(Bing)图片三个网站的图片搜索结果进行爬取和下载。
首先通过爬虫过程中遇到的问题,总结如下:
1、一次页面加载的图片数量各个网站是不定的,每翻一页就会刷新一次,对于数据量大的爬虫几乎都需要用到翻页功能,有如下两种方式:
1)通过网站上的网址进行刷新,例如必应图片:
url = 'http://cn.bing.com/images/async?q={0}&first={1}&count=35&relp=35&lostate=r
&mmasync=1&dgState=x*175_y*848_h*199_c*1_i*106_r*0'2)通过selenium来实现模拟鼠标操作来进行翻页,这一点会在Google图片爬取的时候进行讲解。
2、每个网站应用的图片加载技术都不一样,对于静态加载的网站爬取图片非常容易,因为每张图片的url都直接显示在网页源码中,找到每张图片对应的url即可使用urlretrieve()进行下载。然而对于动态加载的网站就比较复杂,需要具体问题具体分析,例如google图片每次就会加载35张图片(只能得到35张图片的url),当滚动一次后网页并不刷新但是会再次加载一批图片,与前面加载完成的都一起显示在网页源码中。对于动态加载的网站我推荐使用selenium库来爬取。
对于爬取图片的流程基本如下(对于可以通过网址实现翻页或者无需翻页的网站):
1. 找到你需要爬取图片的网站。(以必应为例)
2. 使用google元素检查(其他的没用过不做介绍)来查看网页源码。
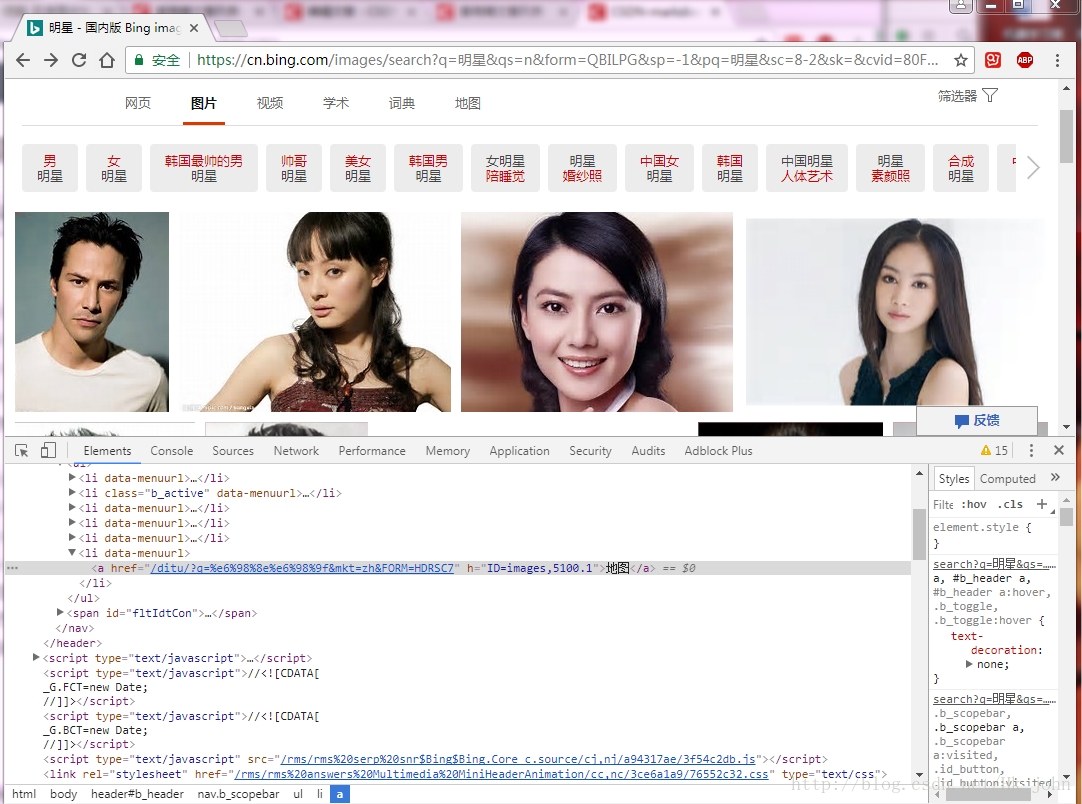
3. 使用左上角的元素检查来找到对应图片的代码。
4. 通过观察找到翻页的规律(有些网站的动态加载是完全看不出来的,这种方法不推荐)
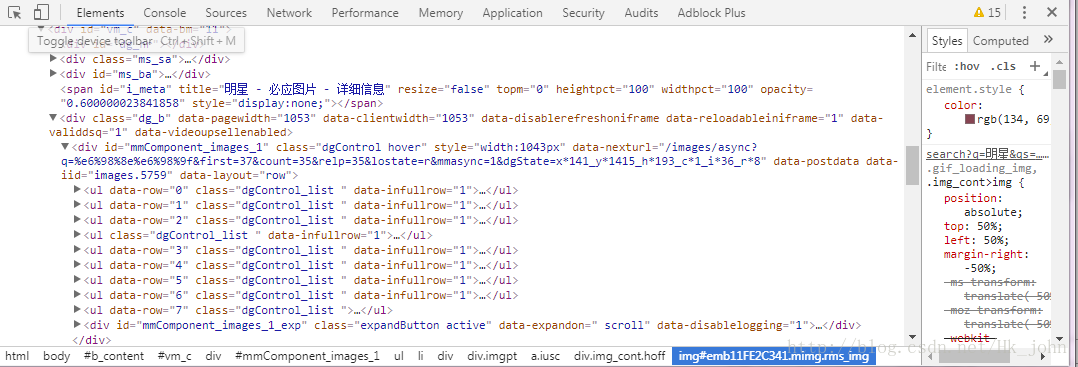
从图中可以看到标签div,class=’dgControl hover’中的data-nexturl的内容随着我们滚动页面翻页first会一直改变,q=二进制码即我们关键字的二进制表示形式。加上前缀之后由此我们才得到了我们要用的url。
5. 我们将网页的源码放进BeautifulSoup中,代码如下:
url = 'http://cn.bing.com/images/async?q={0}&first={1}&count=35&relp=35&lostate=r&mmasync=1&dgState=x*175_y*848_h*199_c*1_i*106_r*0'
agent = {'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.165063 Safari/537.36 AppEngine-Google."}
page1 = urllib.request.Request(url.format(InputData, i*35+1), headers=agent)
page = urllib.request.urlopen(page1)
soup = BeautifulSoup(page.read(), 'html.parser')我们得到的soup是一个class ‘bs4.BeautifulSoup’对象,可以直接对其进行操作,具体内容自行查找。
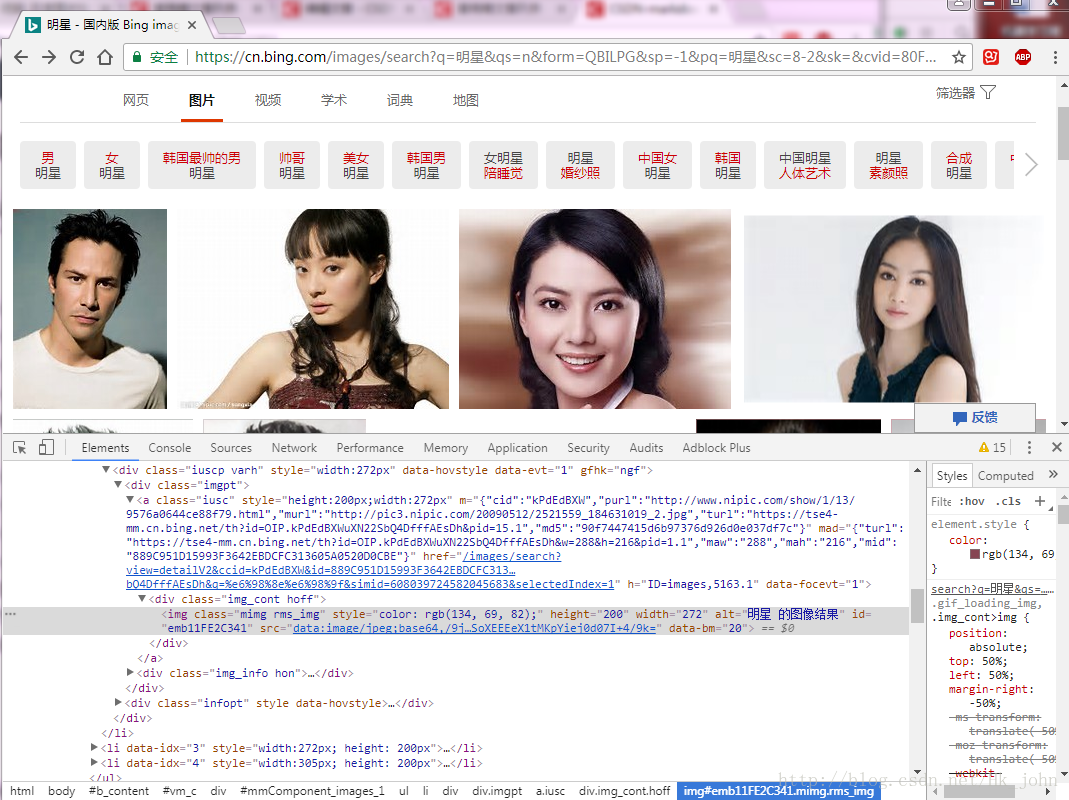
首先选取我们需要的url所在的class,如下图:
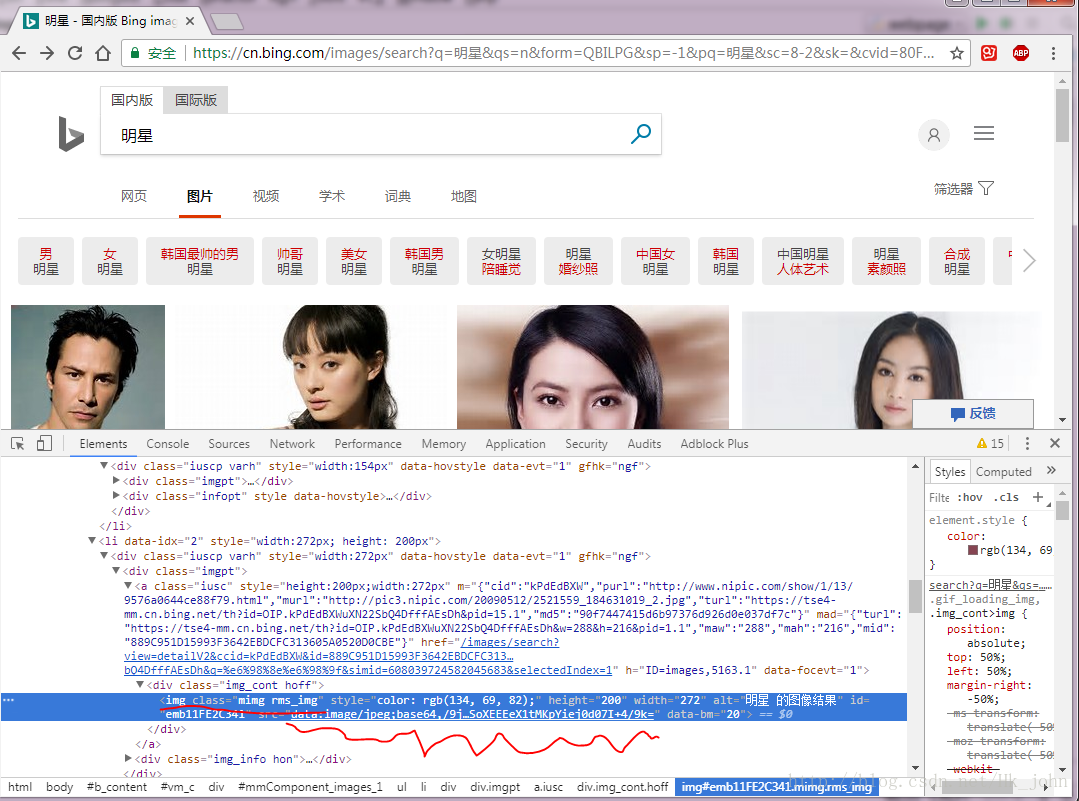
波浪线是我们需要的url。
我们由下面的代码得到我们需要的url:
if not os.path.exists("./" + word):#创建文件夹
os.mkdir('./' + word)
for StepOne in soup.select('.mimg'):
link=StepOne.attrs['src']#将得到的<class 'bs4.element.Tag'>转化为字典形式并取src对应的value。
count = len(os.listdir('./' + word)) + 1
SaveImage(link,word,count)#调用函数保存得到的图片。最后调用urlretrieve()函数下载我们得到的图片url,代码如下:
try:
time.sleep(0.2)
urllib.request.urlretrieve(link,'./'+InputData+'/'+str(count)+'.jpg')
except urllib.error.HTTPError as urllib_err:
print(urllib_err)
except Exception as err:
time.sleep(1)
print(err)
print("产生未知错误,放弃保存")
else:
print("图+1,已有" + str(count) + "张图")这里需要强调是像前面的打开网址和现在的下载图片都需要使用try except进行错误测试,否则出错时程序很容易崩溃,大大浪费了数据采集的时间。
以上就是对单个页面进行数据采集的流程,紧接着改变url中{1}进行翻页操作继续采集下一页。
数据采集结果如下:
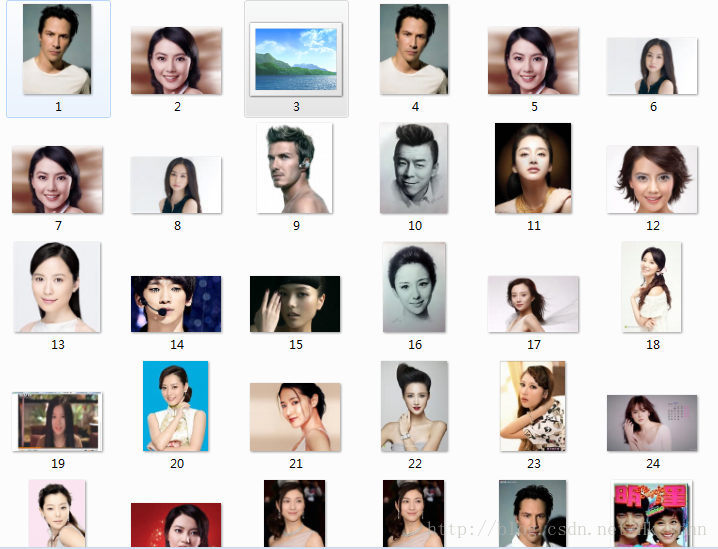
有问题请留言。
转载请注明出处:
http://blog.csdn.net/Hk_john/article/details/78455889
数据采集的速度和成功率非常依赖网络,请选择网络良好的时候进行采集,同时限制自己的采集速度,避免给被爬网站造成网络负担(建议夜间进行),遵守网络规章。















 4948
4948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









