







概述:
第二节我们已经构建了一个包括输入层、隐藏层以及输出层的三层神经网络,分别是一层自学习层和一层softmax学习层。虽然该网络对于MNIST手写数字数据库非常有效,但是它还是一个非常“浅”的网络。这里的“浅”指的是特征(隐藏层的激活值  只使用一层计算单元(隐藏层)来得到的。
只使用一层计算单元(隐藏层)来得到的。
在本节中,我们开始讨论深度神经网络,即含有多个隐藏层的神经网络。通过引入深度网络,我们可以计算更多复杂的输入特征。因为每一个隐藏层可以对上一层的输出进行非线性变换,因此深度神经网络拥有比“浅层”网络更加优异的表达能力(例如可以学习到更加复杂的函数关系)。
值得注意的是当训练深度网络的时候,每一层隐层应该使用非线性的激活函数  。这是因为多层的线性函数组合在一起本质上也只有线性函数的表达能力(例如,将多个线性方程组合在一起仅仅产生另一个线性方程)。因此,在激活函数是线性的情况下,相比于单隐藏层神经网络,包含多隐藏层的深度网络并没有增加表达能力。
。这是因为多层的线性函数组合在一起本质上也只有线性函数的表达能力(例如,将多个线性方程组合在一起仅仅产生另一个线性方程)。因此,在激活函数是线性的情况下,相比于单隐藏层神经网络,包含多隐藏层的深度网络并没有增加表达能力。
深度网络的优势:
为什么我们要使用深度网络呢?使用深度网络最主要的优势在于,它能以更加紧凑简洁的方式来表达比浅层网络大得多的函数集合。正式点说,我们可以找到一些函数,这些函数可以用  层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有
层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有  层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
举一个简单的例子,比如我们打算构建一个布尔网络来计算  个输入比特的奇偶校验码(或者进行异或运算)。假设网络中的每一个节点都可以进行逻辑“或”运算(或者“与非”运算),亦或者逻辑“与”运算。如果我们拥有一个仅仅由一个输入层、一个隐层以及一个输出层构成的网络,那么该奇偶校验函数所需要的节点数目与输入层的规模 呈指数关系。但是,如果我们构建一个更深点的网络,那么这个网络的规模就可做到仅仅是 的多项式函数。
个输入比特的奇偶校验码(或者进行异或运算)。假设网络中的每一个节点都可以进行逻辑“或”运算(或者“与非”运算),亦或者逻辑“与”运算。如果我们拥有一个仅仅由一个输入层、一个隐层以及一个输出层构成的网络,那么该奇偶校验函数所需要的节点数目与输入层的规模 呈指数关系。但是,如果我们构建一个更深点的网络,那么这个网络的规模就可做到仅仅是 的多项式函数。
当处理对象是图像时,我们能够使用深度网络学习到“部分-整体”的分解关系。例如,第一层可以学习如何将图像中的像素组合在一起来检测边缘(正如我们在前面的练习中做的那样)。第二层可以将边缘组合起来检测更长的轮廓或者简单的“目标的部件”。在更深的层次上,可以将这些轮廓进一步组合起来以检测更为复杂的特征。
最后要提的一点是,大脑皮层同样是分多层进行计算的。例如视觉图像在人脑中是分多个阶段进行处理的,首先是进入大脑皮层的“V1”区,然后紧跟着进入大脑皮层“V2”区,以此类推。
训练深度网络的困难:
I.数据获取困难
使用上面提到的方法,我们需要依赖于有标签的数据才能进行训练。然而有标签的数据通常是稀缺的,因此对于许多问题,我们很难获得足够多的样本来拟合一个复杂模型的参数。例如,考虑到深度网络具有强大的表达能力,在不充足的数据上进行训练将会导致过拟合。II.局部极值问题
使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。特别的,使用监督学习方法训练神经网络时,通常会涉及到求解一个高度非凸的优化问题(例如最小化训练误差  ,其中参数
,其中参数  是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
III.梯度弥散问题
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”。与梯度弥散问题紧密相关的问题是:当神经网络中的最后几层含有足够数量神经元的时候,可能单独这几层就足以对有标签数据进行建模,而不用最初几层的帮助。因此,对所有层都使用随机初始化的方法训练得到的整个网络的性能将会与训练得到的浅层网络(仅由深度网络的最后几层组成的浅层网络)的性能相似。
逐层贪婪训练方法:
I.数据获取
虽然获取有标签数据的代价是昂贵的,但获取大量的无标签数据是容易的。自学习方法(self-taughtlearning)的潜力在于它能通过使用大量的无标签数据来学习到更好的模型。具体而言,该方法使用无标签数据来学习得到所有层(不包括用于预测标签的最终分类层) 的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
II.更好的局部极值
一种比较好的获取栈式自编码神经网络参数的方法是采用逐层贪婪训练法进行训练。即先利用原始输入来训练网络的第一层,得到其参数 ;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数
;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数  ;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练。对于上述训练方式,在训练每一层参数的时候,会固定其它各层参数保持不变。所以,如果想得到更好的结果,在上述预训练过程完成之后,可以通过反向传播算法同时调整所有层的参数以改善结果,这个过程一般被称作“微调(fine-tuning)”将会在下一节讲述。实际上,使用逐层贪婪训练方法将参数训练到快要收敛时,应该使用微调。反之,如果直接在随机化的初始权重上使用微调,那么会得到不好的结果,因为参数会收敛到局部最优。如果你只对以分类为目的的微调感兴趣,那么惯用的做法是丢掉栈式自编码网络的“解码”层,直接把最后一个隐藏层的
;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练。对于上述训练方式,在训练每一层参数的时候,会固定其它各层参数保持不变。所以,如果想得到更好的结果,在上述预训练过程完成之后,可以通过反向传播算法同时调整所有层的参数以改善结果,这个过程一般被称作“微调(fine-tuning)”将会在下一节讲述。实际上,使用逐层贪婪训练方法将参数训练到快要收敛时,应该使用微调。反之,如果直接在随机化的初始权重上使用微调,那么会得到不好的结果,因为参数会收敛到局部最优。如果你只对以分类为目的的微调感兴趣,那么惯用的做法是丢掉栈式自编码网络的“解码”层,直接把最后一个隐藏层的  作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层了。
作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层了。
假设你想要训练一个包含两个隐含层的栈式自编码网络,用来进行MNIST手写数字分类(这将会是你的下一个练习)。 首先,你需要用原始输入  训练第一个自编码器,它能够学习得到原始输入的一阶特征表示
训练第一个自编码器,它能够学习得到原始输入的一阶特征表示 ,如下图所示。
,如下图所示。

接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入,都可以得到它对应的一阶特征表示。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征  。,如图所示。
。,如图所示。

最后去掉连上softmax分类器就形成了四层网络的分类器,如下图所示

下面是我实验结果
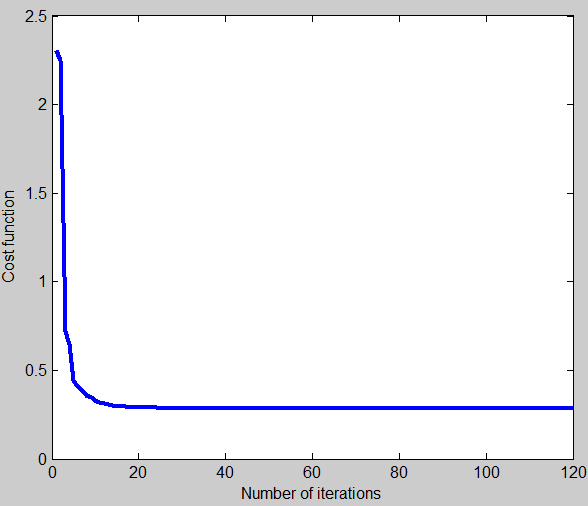
图一 分类器的损失函数随着迭代次数变化的函数

图2 第一层网络的权值

图3 二层网络的权值

图4 softmax分类器的权值
最后得到的识别率为95.28%,为什么识别率这么低呢,请看下一节微调。
下面写出主函数。
Multi_network.m
inputSize = 28 * 28;
numLabels = 10;
hiddenSize = 200;
hiddenSize1=100;
sparsityParam = 0.1; % desired average activation of the hidden units.
% (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
% in the lecture notes).
lambda = 3e-3; % weight decay parameter
beta = 3; % weight of sparsity penalty term
numClasses = 10; % Number of classes (MNIST images fall into 10 classes)
lambda = 1e-4; % Weight decay parameter
itera_num=120;
Learningrate=0.6;
a=1;roi=0.5;c=0.6;m=10;
%% ======================================================================
% STEP 1: Load data from the MNIST database
%
% This loads our training and test data from the MNIST database files.
% We have sorted the data for you in this so that you will not have to
% change it.
% Load MNIST database files
images=loadMNISTImages('train-images.idx3-ubyte');
labels=loadMNISTLabels('train-labels.idx1-ubyte');
testData = loadMNISTImages('t10k-images.idx3-ubyte');
labels1 = loadMNISTLabels('t10k-labels.idx1-ubyte');
labels(labels==0) = 10;
labels1(labels1==0) = 10;
%% ======================================================================
% STEP 2: Train the sparse autoencoder
% This trains the sparse autoencoder on the unlabeled training
% images.
% Randomly initialize the parameters
theta = initializeParameters(hiddenSize, inputSize);
%-------------------------------------------------------------------
opttheta = theta;
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 450;
options.display = 'on';
[opttheta, loss] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, images), ...
theta, options);
trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
images);
testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
testData);
theta = initializeParameters(hiddenSize, inputSize);
%-------------------------------------------------------------------
theta1 = initializeParameters(hiddenSize1, hiddenSize);
%----------------------------------
opttheta1 = theta1;
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 450;
options.display = 'on';
[opttheta1, loss] = minFunc( @(p) sparseAutoencoderCost(p, ...
hiddenSize, hiddenSize1, ...
lambda, sparsityParam, ...
beta, trainFeatures), ...
theta1, options);
trainFeatures1 = feedForwardAutoencoder(opttheta1, hiddenSize1, hiddenSize, ...
trainFeatures);
testFeatures1 = feedForwardAutoencoder(opttheta1, hiddenSize1, hiddenSize, ...
testFeatures);
%================================================
%STEP 3: 训练Softmax分类器
theta = 0.005 * randn(numClasses * hiddenSize1, 1);%输入的是一个列向量
% Randomly initialise theta
theta = reshape(theta, numClasses, hiddenSize1);%将输入的参数列向量变成一个矩阵
inputData = trainFeatures1;
numCases = size(inputData, 2);%输入样本的个数
groundTruth = full(sparse(labels, 1:numCases, 1));%这里sparse是生成一个稀疏矩阵,该矩阵中的值都是第三个值1
%稀疏矩阵的小标由labels和1:numCases对应值构成
thetagrad = zeros(numClasses, hiddenSize1);
p = weight(theta,inputData);
Jcost(1) = -1/numCases * groundTruth(:)' * log(p(:)) + lambda/2 * sum(theta(:) .^ 2);
thetagrad = -1/numCases * (groundTruth - p) * inputData' + lambda * theta;
B=eye(numClasses);
H=-inv(B);
d1=H*thetagrad;
theta_new=theta+a*d1;
theta_old=theta;
fprintf('%10s %10s %15s %15s %15s','Iteration','cost','Accuracy');
fprintf('\n');
%% Training
for i=2:itera_num %计算出某个学习速率alpha下迭代itera_num次数后的参数
a=1;
theta_new=reshape(theta_new, numClasses,hiddenSize1);
theta_old=reshape(theta_old,numClasses,hiddenSize1);
p=weight(theta_new,inputData);
Mp=weight(theta_old,inputData);
Jcost(i)=-1/numCases * groundTruth(:)' * log(p(:)) + lambda/2 * sum(theta_new(:) .^ 2);
thetagrad_new = -1/numCases * (groundTruth - p) * inputData' + lambda * theta_new;
thetagrad_old = -1/numCases * (groundTruth - Mp) * inputData' + lambda * theta_old;
thetagrad_new=reshape(thetagrad_new,numClasses*hiddenSize1,1);
thetagrad_old=reshape(thetagrad_old,numClasses*hiddenSize1,1);
theta_new=reshape(theta_new,numClasses*hiddenSize1,1);
theta_old=reshape(theta_old,numClasses*hiddenSize1,1);
M(:,i-1)=thetagrad_new-thetagrad_old;
BB(:,i-1)=theta_new-theta_old;
roiJ(i-1)=1/(M(:,i-1)'*BB(:,i-1));
gamma=(BB(:,i-1)'*M(:,i-1))/(M(:,i-1)'*M(:,i-1));
HK=gamma*eye(hiddenSize1*numClasses);
r=lbfgsloop(i,m,HK,BB,M,roiJ,thetagrad_new);
d=-r;
d=reshape(d,numClasses,hiddenSize1);
theta_new=reshape(theta_new,numClasses,hiddenSize1);
theta_old=theta_new;
theta_new = theta_new + a*d;
%% test the accuracy
fprintf('%5d %13.4e \n',i,Jcost(i));
end
plot(0:119, Jcost(1:120),'r-o','LineWidth', 2);
inputDatatest = testFeatures1;
pred = zeros(1, size(inputDatatest, 2));
[nop,pred]=max(theta_new*inputDatatest);
acc = mean(labels1(:) == pred(:));
acc=acc * 100
第四节:深度学习网络的微调
================================================================================================
















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









