







为什么要搭建ES集群?
1:在我们es中,如果只用一台es服务的话,那么当我们同时点击量很高时会造成单点问题。
2:在我们数据量太多时, 一台es执行起来效率会变低,所以es也就设置了我们但是用from和size进行分页时,from+size<=10000 这是硬性规定
总结上边:
解决的问题是:当我们数据量太多放到一个库中就会造成es查找性能的下降和点击量太多时造成单点问题
海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点(node-集群下的一台服务器)
单点故障问题:将分片数据在不同节点备份(replica )
ES集群的相关概念
集群(cluster):是一组拥有共同的cluster name的节点
节点(node):集群中的单个Elasticearch实例,也就是集群中的单个Elasticearch服务器就是一个节点
分片(shard): 也就是将一个索引分为不同的部分,就是分片。而分片又可以储存到不同的节点
解决的问题就是当我们的数据量太大时一个ES服务器存储量有限问题,所以需要拆分N片让不同的节点存储
主分片和副本分片
主分片(Primary shard):相对于副本分片的定义。
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份
解决问题:当我们不备份时,我们每个节点拥有一个分片,当某一个如果不能用了那么我们那个节点报错的数据也将不能用了,这样设计是肯定不合理的,下边就是解决办法
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
-
首先对数据分片,存储到不同节点
-
然后对每个分片进行备份,放到对方节点,完成互相备份
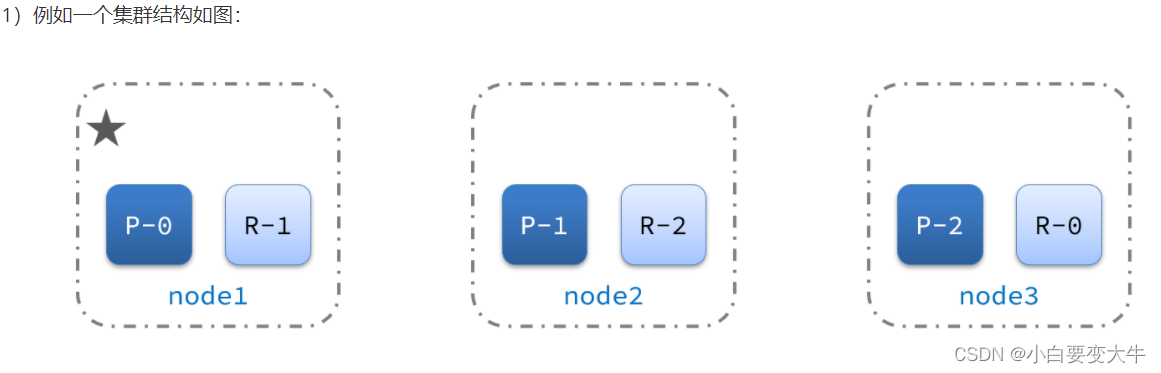
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:

在上图中我们保证了这三个节点每个拥有一个分片,而且又对每个节点两两交换备份,这样就保证了一个节点死掉了那么数据还是完整的,例如:node-0死了,那么分片0就没有了,但是node-1备份了node-0的分片这时候就可以使用node-1的分片0. 在开发中规定布不能两个一起挂掉
node0:保存了分片0和1
node1:保存了分片0和2
node2:保存了分片1和2
搭建ES集群在day09文件夹中
搭建好的集群+脑裂

上图是一个搭建好的集群,然后使用的是cerebro进行可视化页面,我们搭建了三个集群,其中那个五角星为纯白的就是主节点,并且也创建了一个索引,这里可以看到我们的hotel被分为了三片交给不同的节点管理。
故障伸缩(缩:减少节点,伸:增加节点)+故障转移(讲宕机的那个节点上的数据转移到健康节点上)
当我们的其中一个节点死亡以后那么我们这个分片就会交给这两个的另外一个节点,这时候这两个活着的节点中其中一个节点管理了两个分片。当我们那个死点的节点又活过来时,并且这个节点经常这样就死掉了,我们es集群就会认为他不靠谱,所以就会给一些简单的工作,例如只备份分片但是不会让他储存分片
脑裂问题:我们的节点都有机会当上主节点的,他们内部会进行算法托票,我们图中是投的es01作为主节点,当es01这个主节点死掉了,那么还有两个节点他们会再进行投票选出来一个主节点,但是这时候如果我们的es01又活了,因为他之前就是一个主节点,但是现在我们已经又选出来一个主节点了,这时候就存在了两个主节点,导致我们其他节点不知道应该听他们两个谁的,这时候就有一个办法可以解决:
解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题 例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。



Java代码实现给集群添加索引
/**
* 使用Java代码操作es集群添加mapping
*/
@SpringBootTest
public class HotelCluster {
private RestHighLevelClient client = null;
@BeforeEach
public void connection() {
client = new RestHighLevelClient(
RestClient.builder(
//因为我们的是集群所以创建链接对象是需要链接所有的节点
new HttpHost("192.168.200.129", 9200, "http"),
new HttpHost("192.168.200.129", 9201, "http"),
new HttpHost("192.168.200.129", 9202, "http")));
}
@Test
public void testSearchMatch_All() throws IOException {
//创建请求语义对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
request.settings(Settings.builder().put("index.number_of_shards", 3)
.put("index.number_of_replicas", 1)
);
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
System.out.println("acknowledged = " + acknowledged);
}
@AfterEach
public void close() throws IOException {
if (client != null) {
client.close();
}
}
集群职责划分
elasticsearch中集群节点有不同的职责划分:
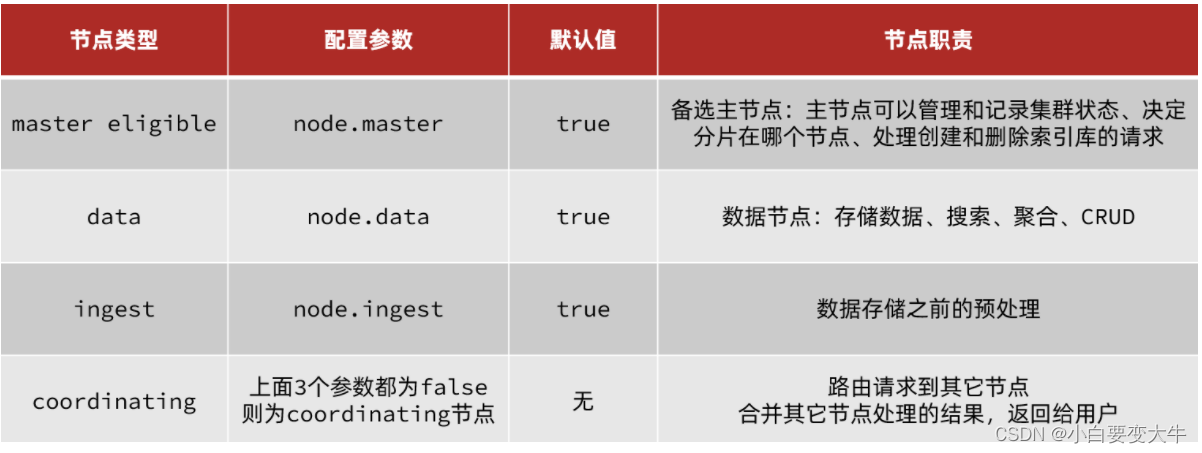
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
master节点:对CPU要求高,但是内存要求低
data节点:对CPU和内存要求都高
coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰
master eligible节点的作用是什么?
参与集群选主
主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
数据的CRUD
coordinator节点的作用是什么?
路由请求到其它节点
合并查询到的结果,返回给用户
es集群职责划分图

当用户是查询: 当我们访问es数据时,通过lb负载均衡到coordinating协调节点会分配到每一个date中,将数据查出来以后合并然后返回给用户
当用户是创建索引库:请求过来协调节点会路由到master主节点,然后主节点根据我们需要的片数决定让下边的节点存储什么分片。
分片储存原理
es是根据hash算法进行计算hash值来计算应该存储到什么分片中
 默认是使用文档中的id
默认是使用文档中的id
说明:
_routing默认是文档的id
算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增流程:
解读:
1)新增一个id=1的文档
2)对id做hash运算,假如得到的是2,则应该存储到shard-2
3)shard-2的主分片在node3节点,将数据路由到node3
4)保存文档
5)同步给shard-2的副本replica-2,在node2节点
6)返回结果给coordinating-node节点
集群分布式查询
elasticsearch的查询分成两个阶段:
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户

集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
现在,node1是主节点,其它两个节点是从节点。
突然,node1发生了故障:
宕机后的第一件事,需要重新选主,例如选中了node2:

node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3:所以就会分配那个节点存储node1的数据,这时候node1已经死掉了,那么我们就不能取node1的分片数据,但是我们node2和node3都有备份node1的分片数据,这时候比如主节点node2决定node3存储 R-1 分片 这时候正好node2备份了R-1分片,所以node2直接将他的R-1分片给node3,而node2存储node1中的P-0,正好node3中备份了所以直接拉过来

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









