









隐藏层各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
【隐藏层的激活值的分布】
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
input_data=np.random.randn(1000, 100) # 1000个数据
node_num=100 # 各隐藏层的节点(神经元)数
hidden_layer_size=5 # 隐藏层有5层
activations={} # 激活值的结果保存在这里
x=input_data
for i in range(hidden_layer_size):
if i!=0:
x=activations[i-1]
# 改变初始值进行实验!
# w=np.random.randn(node_num, node_num)*1
# w=np.random.randn(node_num, node_num)*0.01
w=np.random.randn(node_num, node_num)*np.sqrt(1.0/node_num)
# w=np.random.randn(node_num, node_num)*np.sqrt(2.0/node_num)
a=np.dot(x, w)
# 改变激活函数的种类进行实验!
z=sigmoid(a)
# z=ReLU(a)
# z=tanh(a)
activations[i]=z
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1)+"-layer")
if i!=0: plt.yticks([], [])
# plt.xlim(0.1, 1)
# plt.ylim(0, 7000)
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()当 w=np.random.randn(node_num, node_num)*1,激活函数为 sigmoid 函数时,输出下图:
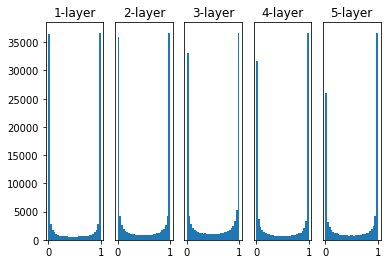
当 w=np.random.randn(node_num, node_num)*0.01,激活函数为 sigmoid 函数时,输出下图:
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









