







原文地址: Extended System Coherency - Part 2 - Implementation, big.LITTLE, GPU Compute and Enterprise
原作者:neilparris
本文是关于硬件一致性系列博文中的第二篇。 在第一篇博文中,我介绍了缓存一致性的基本信息:缓存一致性基本信息
此部分探讨硬件缓存一致性的实施和用例。
另有一个详述 CoreLink CCI-500 的第 3 部分:性能提升和 CoreLink CCI-500 简介
实施硬件一致性
ARM 对 AMBA® 4 ACE 的首批实施包括 ARM® CoreLink™ CCI-400 缓存一致性互联、ARM Cortex®-A15 和 Cortex-A7 处理器。 这些产品于 2011 年首次向我们的芯片合作伙伴发布,我们也在 2013 年将 big.LITTLE™ 产品推向市场。
目前已有超过 24 家合作伙伴获得了 CoreLink CCI-400 授权许可,用于移动应用以及联网和微型服务器等企业级应用。CoreLink CCI-400 支持最多两个 AMBA 4 ACE 处理器群集,允许最多 8 个处理器核心看到相同的内存视图并运行 SMP OS。
移动应用: big.LITTLE 处理
CoreLink CCI-400 支持所有 big.LITTLE 组合,如 Cortex-A15 + Cortex-A7、Cortex-A17 + Cortex-A7 和 Cortex-A57 + Cortex-53 等,完整支持包括 64 位在内的 ARMv8-A。big.LITTLE 处理是 ARM 开发的功率优化技术,通过软件将高性能‘big’核心和效率优化的‘LITTLE’处理器相组合,使应用程序在正确的时间动态转移到正确的处理器上。

硬件一致性是 big.LITTLE 处理技术的基础,因为它允许 big 和 LITTLE 处理器群集看到相同的内存视图并运行同一操作系统。全局任务调度 (GTS) 等 big.LITTLE 软件在给定的时间将任务放入适当的核心。 对于适中的工作负载,所有处理均可在 LITTLE 核心上运行,big 核心则处于关闭状态。 如果某一工作负载需要较高的性能,则开启 big 核心并将该任务迁移其上,其他适中的工作负载继续在 LITTLE 核心上运行。big.LITTLE GTS 允许 SoC 中的所有核心同时运行;例如,一个具有四个 big 核心和四个 LITTLE 核心的设备可以向操作系统表现为一个八核处理器。
big.LITTLE 软件模型有多种,Brian Jeff 在他的 TechCon 演示文稿中进行了介绍: big.LITTLE 技术向完全异构全局任务调度迈进 - Techcon 演示文稿
移动应用: GPU 计算
GPU 计算利用 OpenCL™1.1 Full Profile 和 Google RenderScript 计算等 API,释放 CPU 和GPU 两者组合时的处理力量。
ARM Mali™-T600 系列和 Mali-T760 GPU 支持 AMBA 4 ACE-Lite,实现 CPU 的 IO 一致性。这意味着 GPU 可以直接从 CPU 缓存读取任何共享的数据,而写入共享内存则自动使 CPU 缓存中的相关缓存线失效。 硬件一致性降低了 CPU 和 GPU 之间共享数据的成本,可以实现更加紧密的耦合。
GPU 计算应用包括: 计算摄影、计算机视觉、以 HEVC 和 VP9 等超高清分辨率为目标的现代多媒体编解码器、复杂图像处理,以及手势识别等。
ARM 是异构系统架构 (HSA) 基金会的创始成员之一。 此基金会的宗旨是提供免版税规范,使 SOC 中对异构 CPU、GPU 和 DSP 硬件的利用更加轻松简单。其中包括共享虚拟内存,以及完全一致 GPU 的路线图。 这些技术将进一步降低处理引擎之间共享数据的成本。
更多信息请见 HSA 网站:
http://hsafoundation.com/hot-chips-2013-hsa-foundation-presented-deeper-detail-hsa-hsail/
企业级应用: 联网和服务器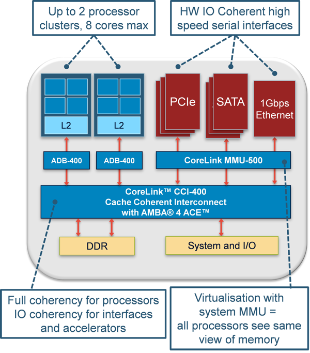
联网和服务器等企业级应用具有高性能串行接口,如 PCI Express、Serial ATA 和以太网等。 在大多数应用中,所有这些数据将标记为共享数据,因为在许多情形中CPU 需要从这些串行接口访问数据。 右图显示了一个简化版示例系统(单击图片可放大显示)。
示例: 网络接口
- 以太网接口上入站数据包存储到 DRAM
- 共享写入将自动使 CPU 缓存中任何陈旧数据失效
- CPU 处理数据包标头
- 以太网接口转发数据包
- 共享读取将在 CPU 缓存和 DRAM 中查找最新的数据
联网应用中有一种趋势,那就是将功能移到软件以允许 SoC 支持多种应用。 这意味着 SoC 需要更多处理节点。
CCI-400 缓存一致性互联正是为各种较小规模企业级应用而设计,例如住宅网关、安全专用设备、WLAN 企业级接入点、工业通信和微型服务器等。 这些应用根据性能要求的不同使用从 Cortex-A7 到 Cortex-A57 等各种 ARM 处理器,最多包含 8 个核心且无 L3 缓存。
ARM 拥有一系列互联产品,扩展各种核心数量的产品的性能:
- CoreLink CCI-400 缓存一致性互联
- 最多 2 个群集,8 个核心
- CoreLink CCN-504 缓存一致性网络
- 最多 4 个群集,16 个核心
- 集成 L3 缓存,2 通道 72 位 DDR
- CoreLink CCN-508 缓存一致性网络
- 最多 8 个群集,32 个核心
- 集成 L3 缓存,4 通道 72 位 DDR
Ian Forsyth 在以下博文中深入探讨了 CoreLink CCN 产品:一致性互联技术助力指数级数据流增长
CoreLink CCI-400 缓存一致性互联
下表详细介绍了 CoreLink CCI-400 的关键特点:
| 特点 | 说明 |
| 从接口 | 2 个 ACE 完全一致性接口,最多 8 个处理器核心(Cortex-A7、Cortex-A15、Cortex-A17、Cortex-A53 或 Cortex-A57) 3 个 ACE-Lite IO 一致性接口,面向 GPU、加速器和接口 |
| 主接口 | 2 个 ACE-Lite 面向内存,具有可配置的交错内存条带选项 1 个 ACE-Lite 面向系统 |
| 服务质量 | 集成式带宽和延迟性调节器,QoS 虚拟网络 |
| 地址空间 | 44 位虚拟、40 位物理 (1TB),支持 ARMv7-A 和 ARMv8-A |
| 性能 | 大约 25GB/s 持续带宽 (533MHz),双通道内存 |
| 面积 | 可以根据性能和频率目标针对应用优化面积 |
两大最常见问题为: 它有多大,运行有多快? CoreLink CCI-400 具有许多配置选项,如寄存器级数和事务跟踪器大小等,允许互联面积和性能根据具体的应用进行优化。 在低端产品上,门数可以降低到 100k 门。 在时钟速度上,我们的基准实施试验以 CMOS 32LP 工艺上 533MHz 为起步,但也看到了不少合作伙伴在更小的硅片几何上以更高的速度进行实施,并且利用更加快速的实施技术。
下图展示了一个示例移动应用处理器,它包含 Cortex-A50 系列处理器、CoreLink MMU-500 系统 MMU 和一组CoreLink 400 系统 IP(单击图片可放大显示)。
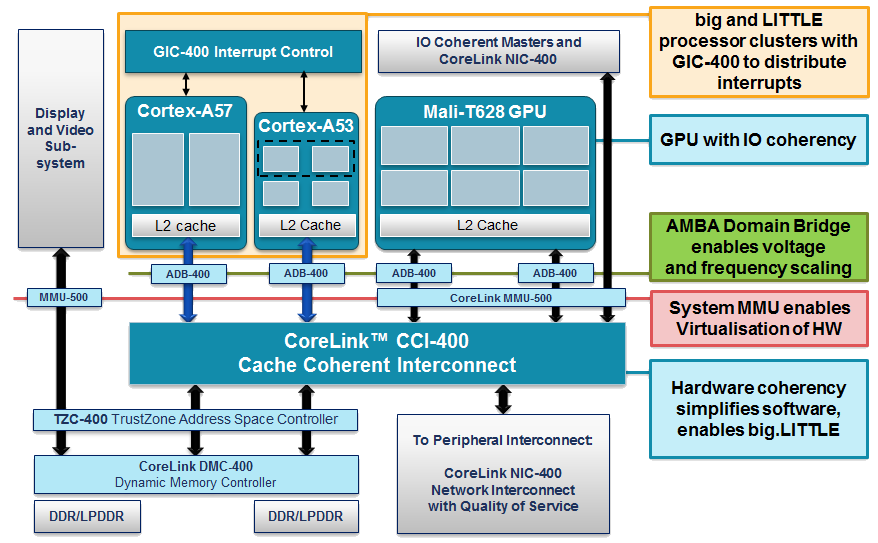
在这一系统中,Cortex-A57 和 Cortex-A53 提供 big.LITTLE 处理器组合,通过 AMBA 4 ACE 与 CCI-400 连接,提供完全的硬件一致性。 Mali-T628 和 IO 一致性主控器通过 AMBA 4 ACE-Lite 接口与 CCI-400 连接。 正如第一篇博文中所述,这种 IO 一致性允许 IO 一致性代理从处理器缓存读取数据。
系统中的其他组件包括:
- MMU-500 系统 MMU - 提供 1 级和/或 2 级地址转换,支持面向系统组件的内存虚拟化。
- TZC-400 TrustZone 地址空间控制器 - 对以内存或外设为目标的事务执行安全检查,允许内存区域被标记为安全或已受保护。
- DMC-400 动态内存控制器 - 提供动态内存调度以及与外部 DDR2/3 或 LPDDR2 内存的接口。
- NIC-400 网络互联 - 为 AMBA 4 AXI4、AMBA 3 AXI3、AHB-Lite 和 APB 组件提供完全可配置、可分层的低延迟连接。
通过 ARM DS-5 Streamline Performance Analyzer进行性能分析
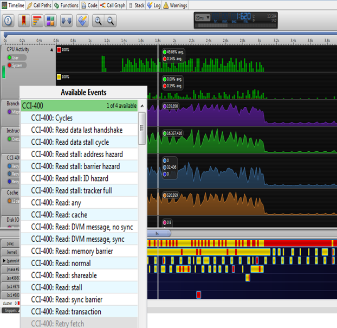
那么,如何通过优化以获得与 CCI-400 相关的最佳性能和功效呢? 一种办法是使用 Streamline Performance Analyzer,它是 ARM DS-5 Development Studio 的一个组件。 它将系统性能指标、软件追踪、统计分析和功耗测量汇总到一起,组成一个系统仪表板以帮助您优化系统。
CCI-400 包含一个性能监控单元 (PMU),它可以统计事件数目来衡量带宽、事务停滞和缓存命中率等项目。 这些计数器可以通过 Streamline Performance Analyzer 进行视觉化呈现,如上方屏幕截图所示。 此数据可以与 SoC 功耗和处理器活动一同显示出来,帮助您了解系统层面上的情况。
小结
在第一篇博文中,我介绍了 AMBA 4 ACE 总线接口如何使硬件缓存一致性超越处理器群集范围,扩展到系统层面。 在本文中,我们探讨了硬件一致性的实施,以及 big.LITTLE 处理等移动应用和企业级应用。 所有这些应用的核心是 CoreLink CCI-400 等缓存一致性互联。ARM 作为一家 IP 提供商身处独一无二的地位,能够提供包含 Cortex 处理器、Mali 图形处理器和 CoreLink 缓存一致性互联的完整解决方案,以及各种工具和物理 IP。 我个人十分期待 2014 年有充分利用缓存一致性和 AMBA 4 ACE 的更多产品推向市场,也会关注大家对于如何受益于这一技术有些怎样的计划或观点!

















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









