









在上一篇博客中,我总结了基于中心(centroid-based)的方法和基于图(graph-based)方法。这两类方法的重心都集中在给文本单元打分上,也就是判断文本单元对原始文档的覆盖度(coverage)或者说文本单元与文档主题的相关度(relevance),进而得到文本单元的重要性权重。这只考虑了自动文摘的第一个要素,没有考虑文本单元之间的相似度可能带来的冗余。一般来说,生成一份高质量的自动文摘应该遵循如下技术框架:
内容表示
→
权重计算
→
内容选择
→
内容组织
\textbf{内容表示}\rightarrow\textbf{权重计算}\rightarrow\textbf{内容选择}\rightarrow\textbf{内容组织}
内容表示→权重计算→内容选择→内容组织
直接将文本单元的权重排序作为内容选择的依据是一种常用策略,但该策略过于简单朴素,在内容选择上考虑不够充分,可能造成摘要质量不高。特别是在多文档摘要中,同一主题的不同文档在内容上往往存在很大的重叠,简单的根据权重选取文本单元将带来很大的冗余。因此,在内容选择上需要联合考虑文本单元的重要性权重和文本单元之间的相关度。本篇博客将介绍基于最优化的(optimization-based)方法进行内容选择。
MMR(Maximal Marginal Relevance)
最大边界相关法(Maximal Marginal relevance,MMR)是最早提出同时考虑内容相关性和内容新颖性(novelty)的方法,由Carbonell和Goldstein于1998年提出。
Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval. 1998:335-336.
MMR用于提高搜索引擎返回结果的多样性,传统的IR搜索引擎返回检索文档序通过降序排列文档与用户检索的相关度。相反的,作者提出需要以“relevant novelty”作为潜在更高阶标准。度量relevant novelty的最简单方法是分别度量相关度和新颖度,然后线性结合,作者将这种线性结合称为“marginal relevance”。我们的目标是最大化边界相关,因此最大边界相关法可以数学表达如下:
M
M
R
=
d
e
f
A
r
g
max
D
i
∈
R
\
S
[
λ
(
S
i
m
1
(
D
i
,
Q
)
)
−
(
1
−
λ
)
(
max
D
j
∈
S
S
i
m
2
(
D
i
,
D
j
)
)
]
MMR\overset{def}{=}Arg\max_{D_i\in R\backslash S}[\lambda (Sim_1(D_i,Q))-(1-\lambda)(\max_{D_j\in S}Sim_2(D_i,D_j))]
MMR=defArgDi∈R\Smax[λ(Sim1(Di,Q))−(1−λ)(Dj∈SmaxSim2(Di,Dj))]
其中,
R
R
R是文档集,
S
S
S是已经选取的文档集,
Q
Q
Q是用户查询。
S
i
m
1
Sim_1
Sim1用来度量文档
D
i
D_i
Di与查询
Q
Q
Q之间的相关度,
S
i
m
2
Sim_2
Sim2用来度量文档
D
i
D_i
Di与
S
S
S中文档
D
j
D_j
Dj的相似度,即代表了冗余度。度量指标
S
i
m
1
Sim_1
Sim1和
S
i
m
2
Sim_2
Sim2可以相同也可以不同。
λ
\lambda
λ用来调节相关度和冗余度的权重。该方法可以很自然的应用到自动文摘中,
R
R
R是句子集合,
S
S
S是已经抽取为摘要的句子集合,
Q
Q
Q是句子集合的中心(Centroid)。
上述数学表达式的求解是一个标准的最优化问题,可以采用贪心算法进行求解,即在每次选取过程中,贪婪的选择内容最相关同时和已选择内容重叠性最小的文档或句子。
Global Inference Algorithms
2009年,McDonald定义了一个多文档摘要的标准范式,企图最优化三方面的属性:①相关性;②冗余性;③长度。同时最优化以上三个属性是一个典型的全局推理问题。作者首先定义了一个通用框架,并证明其是NP-hard。随后,作者分析了三种最优化算法;最后实验评估了三种算法的性能。
Mcdonald R. A Study of Global Inference Algorithms in Multi-document Summarization[M]// Advances in Information Retrieval. DBLP, 2007:557-564.
1、通用框架
定义文档集
D
=
{
D
1
,
…
,
D
k
}
\textbf{D}=\{D_1,\dots,D_k\}
D={D1,…,Dk},每一篇文档
D
D
D是一个文本单元集合
D
=
{
t
1
,
…
,
t
m
}
D=\{t_1,\dots,t_m\}
D={t1,…,tm},
t
i
t_i
ti可以是单词,句子,段落等。为了简便,直接将文档集
D
\textbf{D}
D表示成文档集中所有文档包含的文档单元的集合
D
=
{
t
1
,
…
,
t
n
}
\textbf{D}=\{t_1,\dots,t_n\}
D={t1,…,tn}。
S
⊆
D
S\subseteq\textbf{D}
S⊆D表示一个摘要。形式上,我们可以将多文档摘要的推理问题定义如下:
(1)
S
=
a
r
g
max
S
⊆
D
s
(
S
)
=
a
r
g
max
S
⊆
D
∑
t
i
∈
S
R
e
l
(
i
)
−
∑
t
i
,
t
j
∈
S
,
i
<
j
R
e
d
(
i
,
j
)
s
.
t
.
∑
t
i
∈
S
l
(
i
)
≤
K
\begin{aligned} S =& arg \max_{S\subseteq\textbf{D}}s(S) \\ =& arg \max_{S\subseteq\textbf{D}}\sum_{t_i\in S}Rel(i)-\sum_{t_i,t_j\in S,i<j}Red(i,j)\\ s.t. & \sum_{t_i\in S}l(i)\leq K \end{aligned} \tag 1
S==s.t.argS⊆Dmaxs(S)argS⊆Dmaxti∈S∑Rel(i)−ti,tj∈S,i<j∑Red(i,j)ti∈S∑l(i)≤K(1)
其中, s ( S ) s(S) s(S)是摘要打分函数, R e l ( i ) Rel(i) Rel(i)是相关度度量函数, R e d ( i , j ) Red(i,j) Red(i,j)是冗余度度量函数, l ( i ) l(i) l(i)用于计算 t i t_i ti的长度, K K K是摘要长度限制。
2、贪心算法
最优化表达式(1)最简单的方法是:从选取相关度最高的文本单元开始,迭代地添加能使目标最大的新的文本单元。伪代码如下:

该算法是MMR算法的一个变种,贪心算法最大的优势是计算简单高效,最坏情况下的时间复杂度是 O ( n log n + K n ) O(n\log n+Kn) O(nlogn+Kn),因为排序的时间复杂度是 O ( n log n ) O(n\log n) O(nlogn),每次迭代会花费 O ( n ) O(n) O(n),最多会迭代 K K K次。另一方面,贪婪算法并不保证一定能够找到最优解。在伪代码第二行中,选择相关度最高的句子就会造成误差传播。如果一个相关度很高的句子同时也特别的长,这个句子可能包含很多相关信息,但同时也有可能博阿寒很多噪声,将其选入摘要中,虽然能够最大化相关度但同时也占用了大量的句子长度空间,从而限制了后续句子的加入。这种情况在新闻摘要中特别的常见,因为新闻句子一般都比较的长。理想情况下,包含相似信息的两个句子,我们更倾向于短而紧凑的句子。
3、动态规划算法
为了缓解上述问题,作者又提出了动态规划算法。再重申下,问题的输入是一组文本单元集合
D
=
{
t
1
,
…
,
t
n
}
\textbf{D}=\{t_1,\dots,t_n\}
D={t1,…,tn},和一个整数
K
K
K。令
S
[
i
]
[
k
]
S[i][k]
S[i][k]是摘要长度限制为
k
k
k的情况下,从
{
t
1
,
…
,
t
i
}
\{t_1,\dots,t_i\}
{t1,…,ti}中得到的摘要的最高得分,
i
≤
n
i\leq n
i≤n,
k
≤
K
k\leq K
k≤K。
S
[
i
]
[
k
]
S[i][k]
S[i][k]构成一个表格,可以采用动态规划算法对表格进行填值,伪代码如下:

这个算法基于0-1背包问题,如果忽略表达式(1)中的冗余限制,摘要问题将等价于背包问题,当然了在摘要中我们不能忽略冗余度度量。上述伪代码的关键是4-10行,为了填充表格当前位置
S
[
i
]
[
k
]
S[i][k]
S[i][k],我们需要考虑两种可能的摘要:①
S
[
i
−
1
]
[
k
]
S[i-1][k]
S[i−1][k],其是在
{
t
1
,
⋯
 
,
t
i
−
1
}
\{t_1,\cdots,t_{i-1}\}
{t1,⋯,ti−1}内,长度为
k
k
k的最佳摘要;②
S
[
i
−
1
]
[
k
−
l
(
i
)
]
∪
t
i
S[i-1][k-l(i)]\cup{t_i}
S[i−1][k−l(i)]∪ti,表示在
{
t
1
,
⋯
 
,
t
i
−
1
}
\{t_1,\cdots,t_{i-1}\}
{t1,⋯,ti−1}内,长度为
k
−
l
(
i
)
k-l(i)
k−l(i)的最佳摘要并上当前文本单元
t
i
t_i
ti。
S
[
i
]
[
k
]
S[i][k]
S[i][k]被设置为两者中较大者。背包问题的结构保证了最优子结构原则是成立的,即对于
i
′
<
i
i^{'}<i
i′<i,
k
′
<
k
k^{'}<k
k′<k,如果
S
[
i
′
]
[
k
′
]
S[i^{'}][k^{'}]
S[i′][k′]存储了最优解,那么
S
[
i
]
[
k
]
S[i][k]
S[i][k]也将存储最优解。但是摘要问题中额外考虑的冗余因素打破了这个原则,使得这个最优解只是近似接近我们的目标。算法最后一行仅仅是查询长度限制范围内的最高得分摘要。
使用背包类算法的好处是其剔除了因为贪婪算法选择长句而限制后续求解过程带来的误差。考虑一个包含
A
,
B
,
C
A,B,C
A,B,C三项的简单例子:
R
e
l
(
A
)
=
3
Rel(A)=3
Rel(A)=3,
R
e
l
(
B
)
=
2
Rel(B)=2
Rel(B)=2,
R
e
l
(
C
)
=
2
Rel(C)=2
Rel(C)=2,
l
(
A
)
=
4
l(A)=4
l(A)=4,
l
(
B
)
=
3
l(B)=3
l(B)=3,
l
(
C
)
=
2
l(C)=2
l(C)=2,
K
=
5
K=5
K=5,所有的冗余因子都是0。采用贪婪算法只会包含
A
A
A,但是背包算法将返回最优解
B
B
B和
C
C
C。动态规划算法的时间复杂度也是
O
(
n
log
n
+
K
n
O(n\log n+Kn
O(nlogn+Kn,注意
K
K
K不是最坏情况,而是一个固定的运行时间下界。
3、整数线性规划(ILP)
一个可取的想法是将上述两种算法的解与精确解进行对比以确定因为近似而带来的准确率丢失。采用整数线性规划(Integer Linear Programming,ILP)可以求出精确解。ILP是一个带约束的最优化问题,其中损失函数和约束都是线性的,并且在一组整数中取值。任何的ILP问题都是NP-hard,但采用高效的分支界定算法能够快速发现最优解。GNU Linear Progrmming kit是一个免费的最优化求解工具包。
多文档摘要问题可以表达为ILP问题如下:
(2)
max
∑
i
α
i
R
e
l
(
i
)
−
∑
i
<
j
α
i
j
R
e
d
(
i
,
j
)
s
.
t
.
∀
i
,
j
:
(
1
)
α
i
,
α
i
,
j
∈
{
0
,
1
}
(
4
)
α
i
,
j
−
α
j
≤
0
(
2
)
∑
i
α
i
l
(
i
)
≤
K
(
5
)
α
i
+
α
j
−
α
i
,
j
≤
1
(
3
)
α
i
,
j
−
α
i
≤
0
\begin{aligned} \max\quad\quad&\sum\nolimits_i\alpha_iRel(i)-\sum\nolimits_{i<j}\alpha_{ij}Red(i,j)\\ \\ s.t.\forall i,j:\quad(1)&\alpha_i,\alpha_{i,j}\in\{0,1\}\quad(4)\alpha_{i,j}-\alpha_j\leq0\\ (2)&\sum\nolimits_i\alpha_il(i)\leq K\quad(5)\alpha_i+\alpha_j-\alpha_{i,j}\leq1\\ (3)&\alpha_{i,j}-\alpha_i\leq0 \end{aligned} \tag 2
maxs.t.∀i,j:(1)(2)(3)∑iαiRel(i)−∑i<jαijRed(i,j)αi,αi,j∈{0,1}(4)αi,j−αj≤0∑iαil(i)≤K(5)αi+αj−αi,j≤1αi,j−αi≤0(2)
公式中 α i \alpha_i αi, α i , j \alpha_{i,j} αi,j称为指示器(indicator)只能取值0或1,当 α i = 1 \alpha_i=1 αi=1时表示文本单元 t i t_i ti在摘要中, α i , j = 1 \alpha_{i,j}=1 αi,j=1表示文本单元对 t i t_i ti和 t j t_j tj在摘要中,反之则不在。ILP的目标就是设置这些指示器的值以最大化回报同时满足约束条件保证解是有效的。上式中约束(1)指明了指示器取值只能是0或1,约束(2)是摘要的长度约束。此外,约束(3)到(5)保证了解是有效的,(3)和(4)保证了如果摘要中包含 t i t_i ti和 t j t_j tj文本单元对,那么 t i t_i ti和 t j t_j tj也应该被单独包含,(5)刚好与之相反。
4、性能对比
作者分别从ROUGE值和可扩展性两方面对三个算法进行了对比。在ROUGE值方面,实验采用DUC2002数据集,设置了通用摘要(generic summarization)和基于查询的摘要(query-based summarization)两组实验,采用ROUGE-1和ROUGE-2进行评价,结果如下:
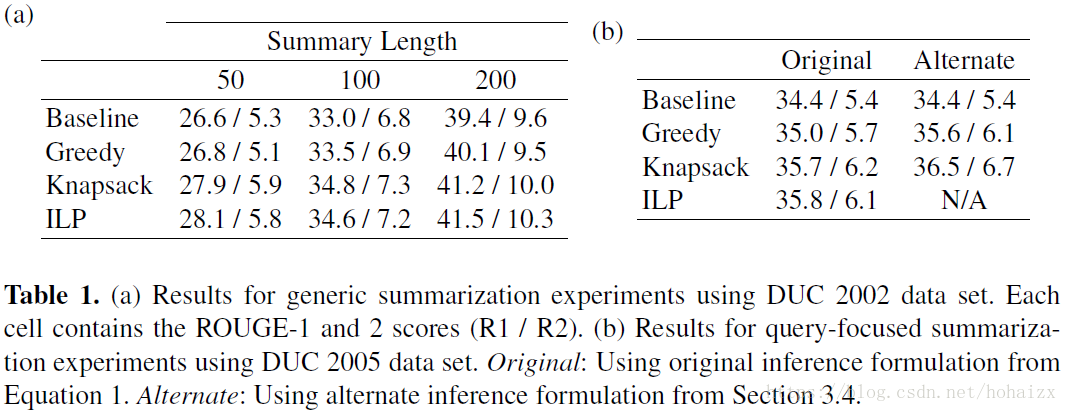
算法应该能够胜任大规模数据以便于应用于现实世界中的问题,为了测试算法的可扩展性,作者将摘要的文本单元数分别限制为20,50,100和500,然后记录每个算法的CPU时间,结果如下:
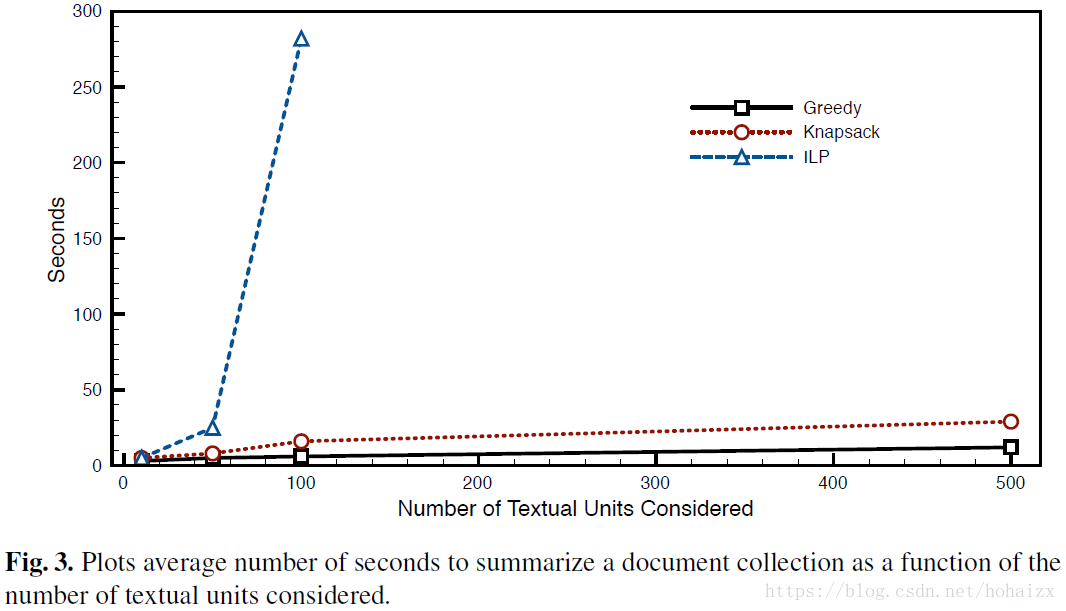
综合考虑ROUGE值和可扩展性,基于背包问题的动态规划算法既提供了较高的准确率也保证了可扩展性,相较于贪婪算法和整数线性规划算法。
scalable global model
将自动文摘问题形式化为基于0-1二值变量的整数线性规划问题能够得到全局最优解,但是为了解决冗余问题,往往需要文本单元数目平方的指示变量,算法的可扩展性较差。2009年Gillick和Favre提出了一个基于ILP的可扩展全局模型。
Dan G, Favre B. A Scalable Global Model for Summarization[J]. 2009.
在该论文中,作者在子句(sub-sentence)或概念级(concept-level)考虑信息和冗余,将摘要问题函数表达为概念覆盖问题,不再显式的考虑冗余项,而是隐式的认为摘要中每个概念只出现一次将不会带来冗余。因此目标函数可以写作:
∑
i
w
i
c
i
\sum_iw_ic_i
i∑wici
其中,
c
i
c_i
ci是指示器,用于指示概念
i
i
i是否出现在摘要中,
w
i
w_i
wi是概念
i
i
i的权重。通过选择一组句子最大化上面目标函数而生成摘要。概念之间被认为是独立的,概念可以是单词、命名实体、语法子树、语义关系等。为了将上述目标函数表达成ILP,作者额外加入了指示器
O
c
c
i
j
Occ_{ij}
Occij用于指示概念
i
i
i是否在句子
j
j
j中出现。
M
a
x
i
m
i
z
e
:
∑
i
w
i
c
i
S
u
b
j
e
c
t
t
o
:
(
1
)
∑
j
l
j
s
j
≤
L
(
2
)
s
j
O
c
c
i
j
≤
c
i
,
∀
i
,
j
(
3
)
∑
j
s
j
O
c
c
i
j
≥
c
i
,
∀
i
(
4
)
c
i
∈
0
,
1
∀
i
(
5
)
s
j
∈
0
,
1
∀
j
\begin{aligned} Maximize:&\quad\sum_iw_ic_i\\ Subject\ to:&\quad (1)\sum_jl_js_j\leq L\\ &\quad (2)s_jOcc_{ij}\leq c_i,\quad\forall i,j \\ &\quad (3)\sum_js_jOcc_{ij}\geq c_i,\quad\forall i \\ &\quad (4)c_i\in{0,1}\quad\forall i\\ &\quad (5)s_j\in{0,1}\quad\forall j \end{aligned}
Maximize:Subject to:i∑wici(1)j∑ljsj≤L(2)sjOccij≤ci,∀i,j(3)j∑sjOccij≥ci,∀i(4)ci∈0,1∀i(5)sj∈0,1∀j
约束(2)和(3)用于保证解的逻辑一致性:选择了一个句子就要选择其包含的概念;反过来,如果一个概念被选中了,那么其至少出现在一个句子中。约束(3)同时也阻止了选择概念少的句子。
可扩展性方面,基于概念的方法只有
O
(
n
+
m
)
O(n+m)
O(n+m)个变量,但是McDonald的方法包含
O
(
n
2
)
O(n^2)
O(n2)个变量。实践中,可扩展性很大程度上取决于冗余矩阵
R
e
d
Red
Red和句子概念矩阵
O
c
c
Occ
Occ的稀疏性,因此高效的求解过程要求恰当的冗余度量公式和概念选取方式。对于McDonald的方法而言,减少复杂度涉及的剪枝包括移除低相关度的句子或忽略冗余度较低的值;对于基于概念的方法而言,减少复杂度涉及的剪枝主要是剔除权重较低的概念。值得注意的是,剪枝概念是更可取的:剪枝过的句子是不可恢复的,但是剪枝过的概念可能会同时出现在其他选定的句子中。
总结
基于最优化的方法将摘要问题形式化为一个带约束的数学问题,研究者们由此提出了各种各样的推理算法,以求找出近似解或者精确解,同时,研究者们也从不同粒度对摘要问题进行了研究。
参考文献
[1] Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval. 1998:335-336.
[2] Mcdonald R. A Study of Global Inference Algorithms in Multi-document Summarization[M]// Advances in Information Retrieval. DBLP, 2007:557-564.
[3] Dan G, Favre B. A Scalable Global Model for Summarization[J]. 2009.

















 5391
5391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









