






这不是第三集啊 只是版本号
BEIT-3 使用掩码数据建模的方式,借助 Transformer 这一方便处理图片和文本的模型架构,统一进行训练,在多个纯视觉任务和视觉-文本任务中都取得了 SOTA 性能。
BEIT-3 这个工作的关键词就是:大一统,即:用一个模型架构和一个训练任务,打造出多模态领域的集大成者。这里也贴出来原作者之一董力老师的评价:
如何评价微软提出的BEIT-3:通过多路Transformer实现多模态统一建模?
https://www.zhihu.com/question/549621097
这个工作的主要观点和思路就是 Abstract 的第一句话:A big convergence of language, vision, and multimodal pretraining is emerging,即视觉的表征,语言的表征和多模态的表征都在大一统。BEIT-3 就是对这种思想的集大成者,用出这种思想 (使用 Transformer 模型统一处理视觉和文本信息,使用 Mask Data Modeling 的训练策略统一建模视觉和文本信息)。
具体而言,作者从三个方面实现了大一统:模型架构 (VLMo[1] 中使用的 Mixture-of-Modality-Experts, MoME,即 Multiway Transformer)、预训练任务 (Mask Data Modeling) 和模型缩放 (把模型放大)。
Mask Data Modeling 又根据输入是图片和文本的不同分为:文本 English,图像 Imaglish,和图文对 Parallel Sentences。
BEIT-3 使用掩码数据建模的方式,借助 Transformer 这一方便处理图片和文本的模型架构,统一进行训练,在多个纯视觉任务和视觉-文本任务中都取得了 SOTA 性能。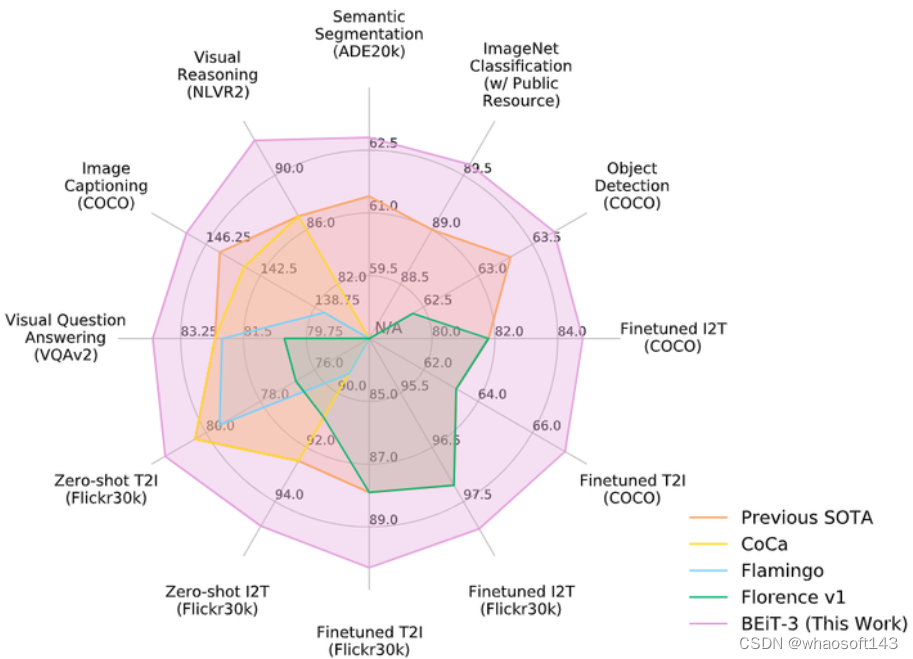 图1:与其他定制或基础模型相比,BEIT-3 在广泛的任务上实现了最先进的性能。I2T/T2I 是图像到文本/文本到图像检索的缩写
图1:与其他定制或基础模型相比,BEIT-3 在广泛的任务上实现了最先进的性能。I2T/T2I 是图像到文本/文本到图像检索的缩写
BEIT-3:一个模型架构和一个训练任务,多模态领域的集大成者
论文名称:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks (CVPR 2023)
论文地址:
http://arxiv.org/pdf/2208.10442.pdf
代码地址:
http://github.com/microsoft/unilm/tree/master/beit3
BEIT-3 的背景来自于 Transformer 这个架构和 Masked Data Modeling 的这个训练策略已经在视觉 (代表作 BEIT[2], BEIT v2[3]),文本 (代表作 GPT[4], BERT[5]),多模态 (代表作 VLMo[6], CLIP[7], CoCa[8]) 领域取得了成功,通过对海量数据进行大规模预训练,可以很容易地将这些得到的预训练模型转移到各种下游任务中。如果能训练一个能够直接处理多种数据类型的通用基础模型,将会是一件很有吸引力的事情。
BEIT-3 从三个方面实现了大一统:
-
模型架构
-
预训练任务
-
预训练架构放大
模型架构
在以往多模态的一些工作里,Transformer 模型在应用的时候有多种方法,比如双塔架构[9] (dual-encoder architecture) 用于高效检索,用于生成任务的编码器-解码器网络[10] (encoder-decoder networks) 和用于图像-文本编码的融合编码器架构[11] (fusion-encoder architecture)。但是,参数通常不能有效地跨模式共享。
BEIT-3 里采用的是 VLMo[1] 中使用的 Mixture-of-Modality-Experts, MoME,这里改了个名字叫 Multiway Transformer,这个架构的特点如下图2所示。
主流多模态模型分为两种,一种是双塔结构 (Dual Encoder),主要用来做多模态检索任务;一种是单塔结构 (Fusion Encoder),主要用来做多模态分类任务。VLMo 相当于是一个混合专家 Transformer 模型,预训练完成后,使用时既可以是双塔结构实现高效的图像文本检索,又可以是单塔结构成为分类任务的多模态编码器。换句话讲,VLMo 这个工作的一个很重要的贡献是对多模态领域的单塔,双塔结构进行了统一,用一个混合专家模型既可以实现视觉特征和文本特征的融合,又可以实现分别对两种模态的特征进行高效的编码,来做检索任务。VLMo 这个架构里面:FFN 分为3块,分别是 Vision FFN,Language FFN 和 Vision-Language FFN (作者把每个 FFN 命名为 Expert)。Self-Attention 部分三种模态共享参数。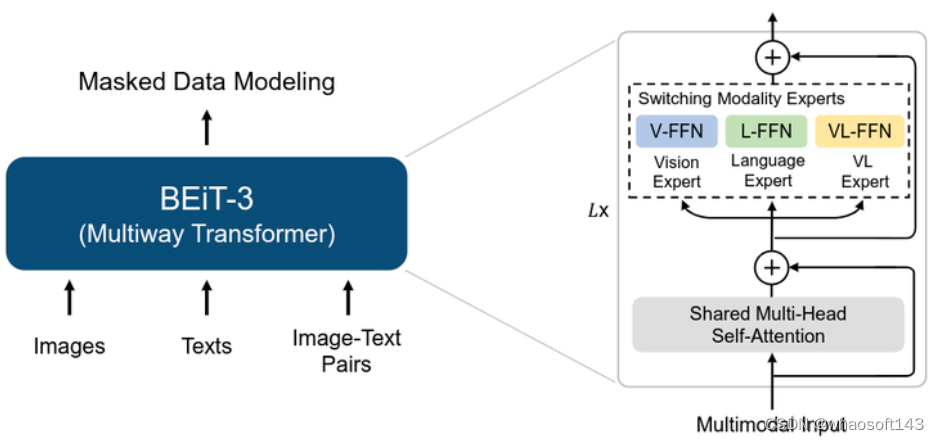 图2:BEIT-3 架构 Multiway Transformer
图2:BEIT-3 架构 Multiway Transformer
如下图3所示,输入的数据根据其模态的不同选择不同的 Expert,比如图片数据就使用 Vision FFN,文本数据就使用 Language FFN。模型前面的一些层是只有 Vision FFN 和 Language FFN,到了最后3层会再有 Vision-Language FFN,为了特征融合。下
图 3(a) 所示是 BEIT-3 模型转换为视觉编码器,适配任务:图像分类,目标检测,语义分割 (ImageNet-1K, COCO, ADE20K)
图 3(b) 所示是 BEIT-3 模型转换为文本编码器。
图 3(c) 所示是单塔结构,联合编码图像-文本对以进行深度交互的融合编码器,适配任务:多模态理解任务 (VQA, NLVR2)。
图 3(d) 所示是双塔结构,对每个模态进行单独编码以求高效的图文检索,适配任务:图文检索任务 (Flickr30k, COCO)。
图 3(e) 所示是单塔结构,用于图像到文本生成任务,适配任务:多模态生成任务 (COCO)。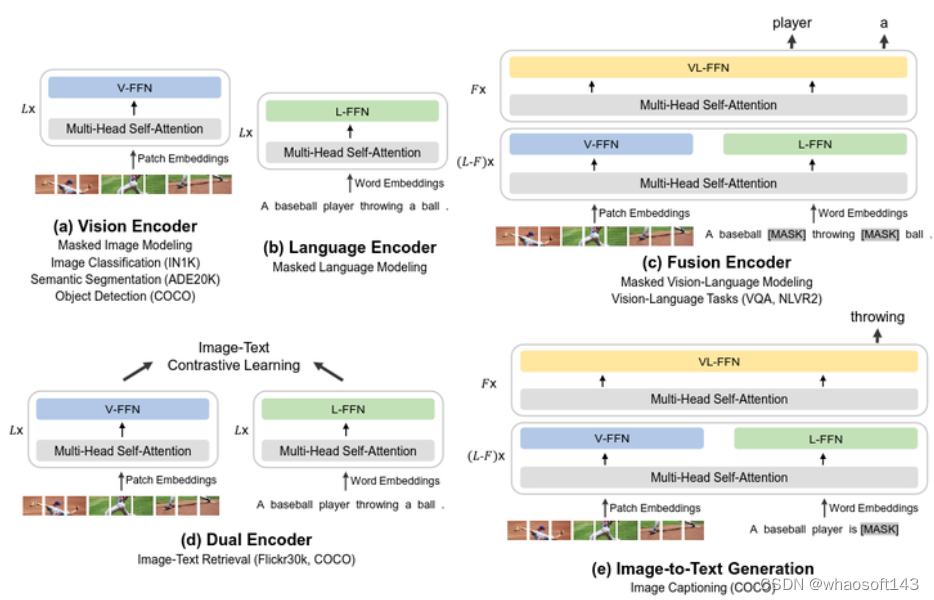 图3:BEIT-3 可以转移到各种视觉和语言下游任务
图3:BEIT-3 可以转移到各种视觉和语言下游任务
预训练任务
Mask Data Modeling 这个预训练的范式已经在文本 (以 BERT 为代表的 Mask Language Modeling) 和视觉 (以 BEIT 为代表的 Mask Image Modeling) 这两个领域都取得了成功。
BEIT-3 这个工作将 Mask Data Modeling 的训练范式扩展到了多模态领域,将图片 Image 视为一种外语 Imglish,和文本 English 一起采用 Mask Data Modeling 的做法进行训练。
当前的多模态模型的预训练方法还有使用图像-文本匹配 (Image-Text Matching Loss) 图像-文本对比学习 (Image-Text Contrastive Loss) 等等,但是相比之下还要平衡各个损失函数之间的权重,很麻烦。而 BEIT-3 就仅仅采用了 Mask Data Modeling 这一个目标函数。这个简单而有效的方法学习了强大的可转移表征,在视觉和语言任务上都实现了最先进的性能。
这种大一统的 mask-then-predict 任务不仅学习表征,而且学习不同模态之间的对齐。具体而言,文本数据是由 SentencePiece tokenizer 进行标记。图像数据由 BEIT v2 的 tokenizer 进行标记,以获得离散视觉标记作为重建的目标。作者从单模态文本中随机 mask 掉 15% 的文本,从图片-文本对中随机 mask 掉 50% 的文本。在 mask 图像时采用 BEIT 的做法 mask 掉 40%。
预训练架构放大
扩大模型大小和数据大小普遍提高了基础模型的泛化质量,这样我们就可以将它们转移到各种下游任务中。BEIT-3 也采用了类似的做法。在预训练期间,作者随机屏蔽了一定比例的 text token 或者 image token。自监督学习目标是在给定损坏的输入的情况下恢复原始 token,因此 BEIT-3 模型的 Masked Data Modeling 方法是通用的,不局限于输入是 text 还是 image。
BEIT-3 的模型放到了多大?
BEIT-3 的模型尺寸量级达到了 ViT-giant[12]的级别,模型由一个 40 层 Multiway Transformer 组成,Embedded dimension 为 1408,注意力头数量为 16。所有层都包含 Vision Expert 和 Language Expert,最后3个 Transformer 层也有 Vision-Language Expert。
如下图4所示,Self-Attention 模块在不同的模态之间共享。BEIT-3 总共包含 1.9B 参数,包括 Vision Expert 的 692M 参数、Language Expert 的 692M 参数、Vision-Language Expert 的 52M 参数和共享注意力模块的 317M 参数。值得注意的是,当模型用作视觉编码器时,只有与视觉相关的参数 (与 ViT-giant 相当的大小,大约 1B) 被激活。 图4:BEIT-3 的参数量
图4:BEIT-3 的参数量
BEIT-3 的预训练数据有多少?
BEIT-3 的预训练数据全部都是公开数据集,如下图5所示。
对于多模态数据,从五个公共数据集收集了大约 15M 图像和 21M 图像-文本对:Conceptual 12M (CC12M) 、Conceptual Captions (CC3M)、SBU Captions (SBU)、COCO 和 Visual Genome (VG)。
对于单模态图像数据,BEIT-3 使用 ImageNet-21K,大约 14M 图片。
对于单模态文本数据,BEIT-3 使用来自 English Wikipedia、BookCorpus、OpenWebText3、CC-News 和 Stories。 图5:BEIT-3 的预训练数据,都是公开数据集
图5:BEIT-3 的预训练数据,都是公开数据集
BEIT-3 的预训练过程是什么? 多模态视觉-文本任务实验结果
多模态视觉-文本任务实验结果
如下图6所示是 BEIT-3 的主要实验结果,可以看到不论是在单模态的视觉任务还是多模态的视觉-文本任务上面 BEIT-3 都取得了 SOTA 的性能,而且有的任务甚至高出当时的 SOTA 很多。这里的 SOTA 是指也是在公开数据集上训练的模型的 SOTA。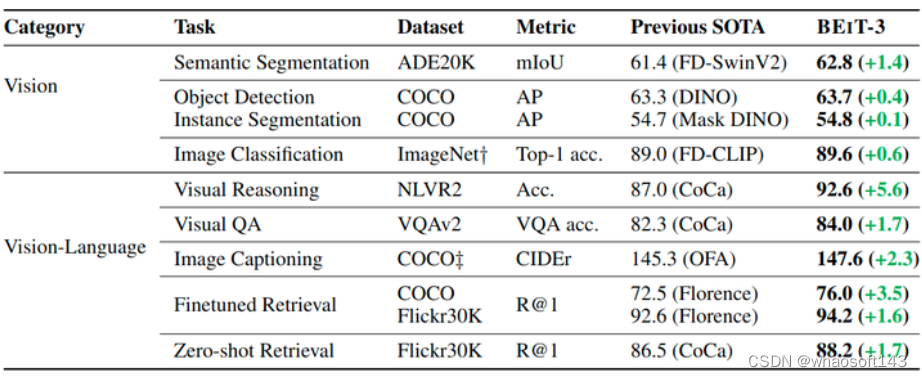 图6:BEIT-3 主要实验结果
图6:BEIT-3 主要实验结果
视觉问答任务 (Visual Question Answering, VQA) 实验结果
VQA 任务要求模型回答有关输入图像的自然语言问题。继之前的工作 ViLT[13] 等之后,作者在 VQA v2.0 数据集 上进行了微调实验,并将任务制定为分类问题。模型在训练过程中被要求预测训练集中 3129 个最常见的候选问题的答案。
在做 VQA 的过程中,BEIT-3 微调时以 fusion encoder 的方式来呈现,用于对 VQA 任务的图像和问题进行建模。作者将给定问题和图像的嵌入表征 Concat 起来,一起送入 Multiway Transformer 中,以联合编码图像-问题对。最终的池化层的输出被送入分类器以预测答案。实验结果如下图7所示,BEIT-3 大大优于所有先前的模型,达到了 84.03 的精度。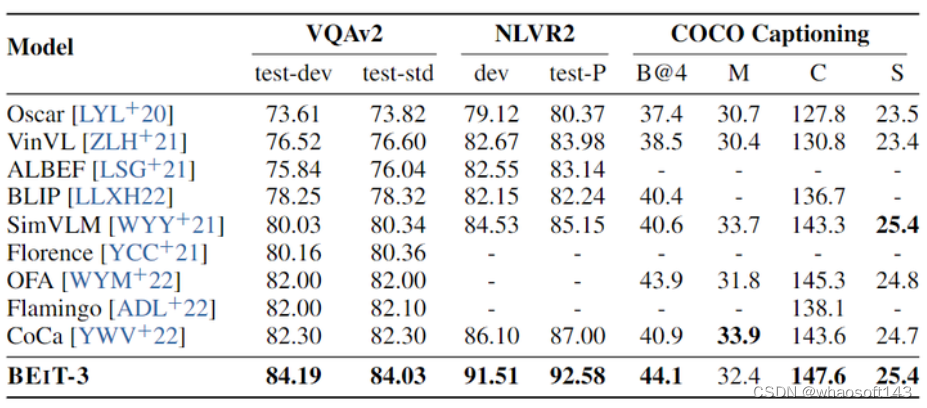 图7:视觉问答,视觉推理和图像字幕结果。VQAv2 报的是 VQAv2 test-dev 和 test-standard splits 的 vqa 分数,NLVR2 报的是 NLVR2 development set 和 public test set (test-P) 的分数,COCO Captioning 报的是 Karpathy test split 的 BLEU@4 (B@4), METEOR (M), CIDEr (C), 和 SPICE (S) 的分数
图7:视觉问答,视觉推理和图像字幕结果。VQAv2 报的是 VQAv2 test-dev 和 test-standard splits 的 vqa 分数,NLVR2 报的是 NLVR2 development set 和 public test set (test-P) 的分数,COCO Captioning 报的是 Karpathy test split 的 BLEU@4 (B@4), METEOR (M), CIDEr (C), 和 SPICE (S) 的分数
视觉推理任务 (Visual Reasoning) 实验结果
视觉推理任务需要模型对图像和自然语言描述进行联合推理。作者在流行的 NLVR2 benchmark 上评估模型,即确定文本描述是否对一对图像为真。继之前的工作 ViLT[13] 等之后,作者基于三元组输入构建了两个图像-文本对。
在做 NLVR 的过程中,BEIT-3 微调时以 fusion encoder 的方式来呈现,以联合编码图像-文本对。两个图像-文本对的最终池化输出被 Concat 起来,送入分类器中以预测标签。实验结果如图7所示,BEIT-3 比 CoCa 高出约 5.6 个百分点。NLVR2 的性能首次达到 90% 以上。
图像字幕任务 (Image Captioning) 实验结果
图像字幕任务旨在为给定图像生成自然语言标题。作者使用 COCO benchmark,COCO Captioning 报的是 Karpathy test split 的 BLEU@4 (B@4), METEOR (M), CIDEr (C), 和 SPICE (S) 的分数。遵循 UNILM[14]和 s2s-ft[15]的做法,BEIT-3 微调时以 image-to-text generation 的方式来呈现。Image token 只能在图像的序列内部双向关注,Caption 的 token 可以关注到 Image token,它们左侧的 token 和它们自己。BEIT-3 模型经过训练以根据图像及其 Caption 的上下文的线索来恢复这些 Caption。为了简单起见,BEIT-3 使用简单的交叉熵损失进行训练,而不使用 CIDEr 优化。在推理的过程中,BEIT-3 以自回归 (Autoregressive) 的方式逐一生成 Caption。
图7展示了 COCO 字幕的结果。BEIT-3 优于所有以前使用交叉熵损失训练的模型,得到了最先进的图像字幕结果。结果表明 BEIT-3 在视觉语言生成方面的优越性。
图文检索任务 (Image-Text Retrieval) 实验结果
图文检索任务是测量图像和文本之间的相似性,根据检索目标的模态可以分为图像到文本检索和文本到图像检索。使用两个流行的 benchmark:COCO 和 Flickr30K 来评估 BEIT-3 模型。继之前的工作 ViLT[13] 等之后,作者评估时对这两个 benchmark 使用 Karpathy split。BEIT-3 微调时以 dual encoder 的方式来呈现,以实现高效的图像文本检索。双编码器模型分别对图像和文本进行编码以获得它们的表示。然后我们计算这些表示的余弦相似度分数。双编码器模型比融合编码器模型更有效。因为它们不必联合编码所有可能的图像-文本对。作者在 COCO 和 Flickr30K 上直接微调 BEIT-3。
值得一提的是 BEIT-3 虽然没有使用图像-文本对比损失进行预训练,但优于以前的最先进模型。结果表明,BEIT-3 通过掩码数据建模有效地学习图像和文本之间的对齐。为了提升性能,作者在预训练图文对上使用 image-text contrastive 目标函数进行中间微调,然后使用该模型来评估 zero-shot 和 finetuned image-text retrieval。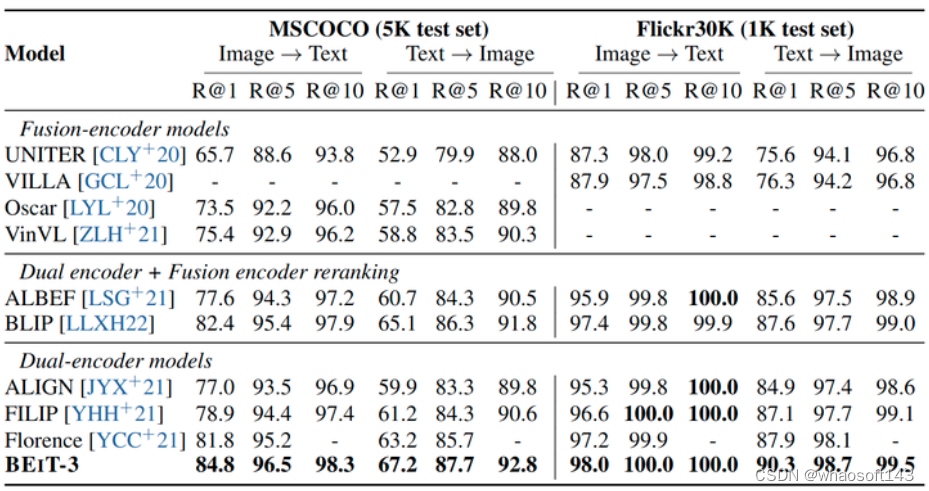 图8:COCO 和 Flickr30K 的图文检索和文图检索的 Fine-Tuned 结果。值得注意的是,双编码器模型比基于融合编码器的检索任务模型更有效
图8:COCO 和 Flickr30K 的图文检索和文图检索的 Fine-Tuned 结果。值得注意的是,双编码器模型比基于融合编码器的检索任务模型更有效
微调的结果如图8所示,双编码器的 BEIT-3 大大优于先前的模型,在 COCO top-1 图文和文图检索上实现了 3.0/4.0 的改进,Flickr30K top-1 图文和文图检索上实现了 0.8/2.4 的改进。
在 Zero-Shot 检索任务上,BEIT-3 也比以前的 fusion-encoder 模型 (需要更多推理成本) 取得了更好的性能,如下图9所示。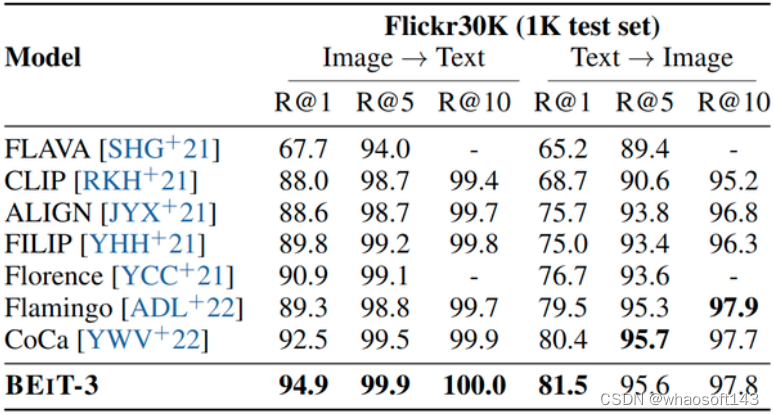 图9:Flickr30K 的 Zero-Shot 图文检索和文图检索结果,BEIT-3 也比以前的 fusion-encoder 模型取得了更好的性能
图9:Flickr30K 的 Zero-Shot 图文检索和文图检索结果,BEIT-3 也比以前的 fusion-encoder 模型取得了更好的性能
单模态视觉任务实验结果
预训练好的 BEIT-3 模型还可以直接迁移到视觉任务上面。当 BEIT-3 用作视觉编码器时,有效参数的数量与 ViT-giant 相当,即大约 1B 参数。
目标检测和实例分割实验结果
作者在 COCO 2017 benchmark 上进行了微调实验,该 benchmark 由 118k 训练、5k 验证和 20k 测试图像组成。作者使用 BEIT-3 作为骨干,并遵循 ViTDet[16] 的做法,用于对象检测和实例分割任务。BEIT-3 遵循 Swin V2[17] 和 DINO[18] 的做法,首先使用 Objects365 数据集进行中间微调,然后再在 COCO 数据集上微调模型。在推理过程中使用 Soft-NMS。实验结果如下图所示,BEIT-3 在 COCO test-dev 集上取得了最好的结果。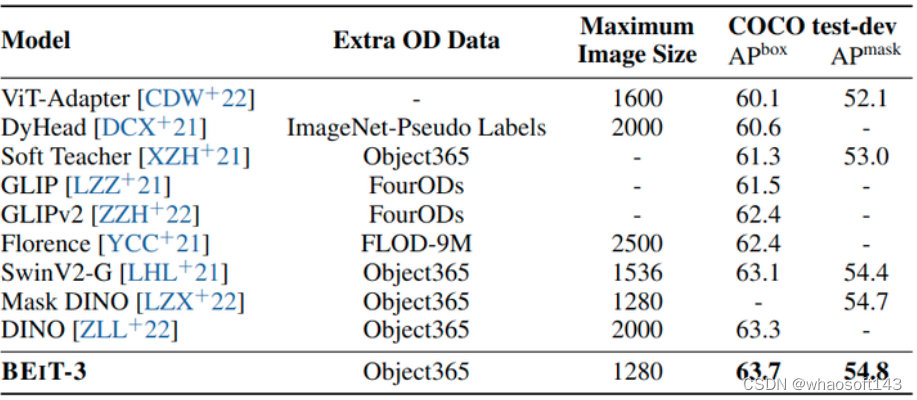 图:目标检测和实例分割实验结果
图:目标检测和实例分割实验结果
语义分割实验结果
语义分割的目的是预测给定图像每个像素的标签。作者在具有挑战性的 ADE20K 数据集上评估 BEIT-3,其中包括150个语义类别。ADE20K 包含 20k 张图像用于训练,2k 张图像用于验证。BEIT-3 直接遵循 ViT-Adapter 的做法。直接使用 Mask2Former 作为分割头。实验结果如下图所示,BEIT-3 的 mIoU 达到了 62.8,优于大小为 3B 的 FD-SwinV2,在密集预测任务上取得了卓越的性能。whaosoft aiot http://143ai.com 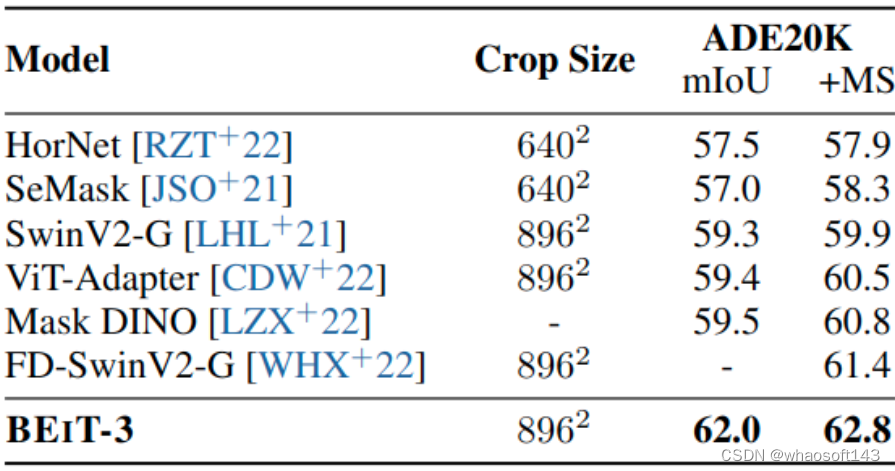 图:语义分割实验结果
图:语义分割实验结果
图像分类实验结果
作者也在 ImageNet-1K 上面评估了 BEIT-3 模型,实验结果如下图所示。评估做法不是在预训练好的 Backbone 之后加一个分类层之后做微调,而是将任务制定为图像到文本检索任务。作者使用类别名称作为文本来构建图像-文本对。BEIT-3 被训练为双编码器,以找到与图像最相关的标签。在推理的时候,首先计算每个类名称的特征嵌入和输入图片的特征嵌入的余弦相似度,再计算每张图片最可能的类别。
BEIT-3 首先在 ImageNet-21K 上执行中间微调,然后在 ImageNet-1K 上训练模型。为了公平比较,作者仅使用公共图像标签数据与之前的模型进行比较。BEIT-3 优于先前的模型,在仅使用公共图像标签数据时创造了新的 SOTA 结果。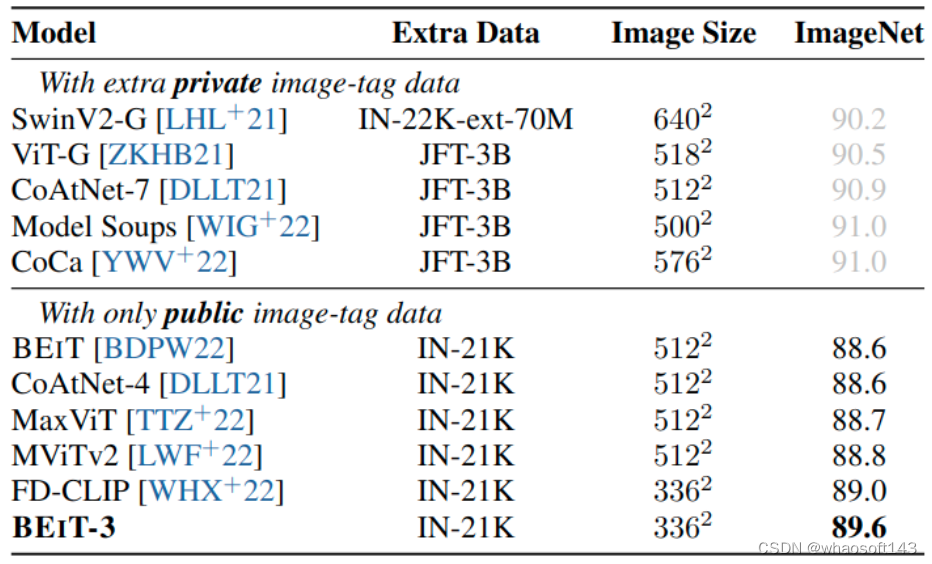 图:ImageNet-1K 图像分类实验结果
图:ImageNet-1K 图像分类实验结果

















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









