






(未完待续,持续更新中)
目录
PMU
perf map
perf list可以看到如下hardware event,
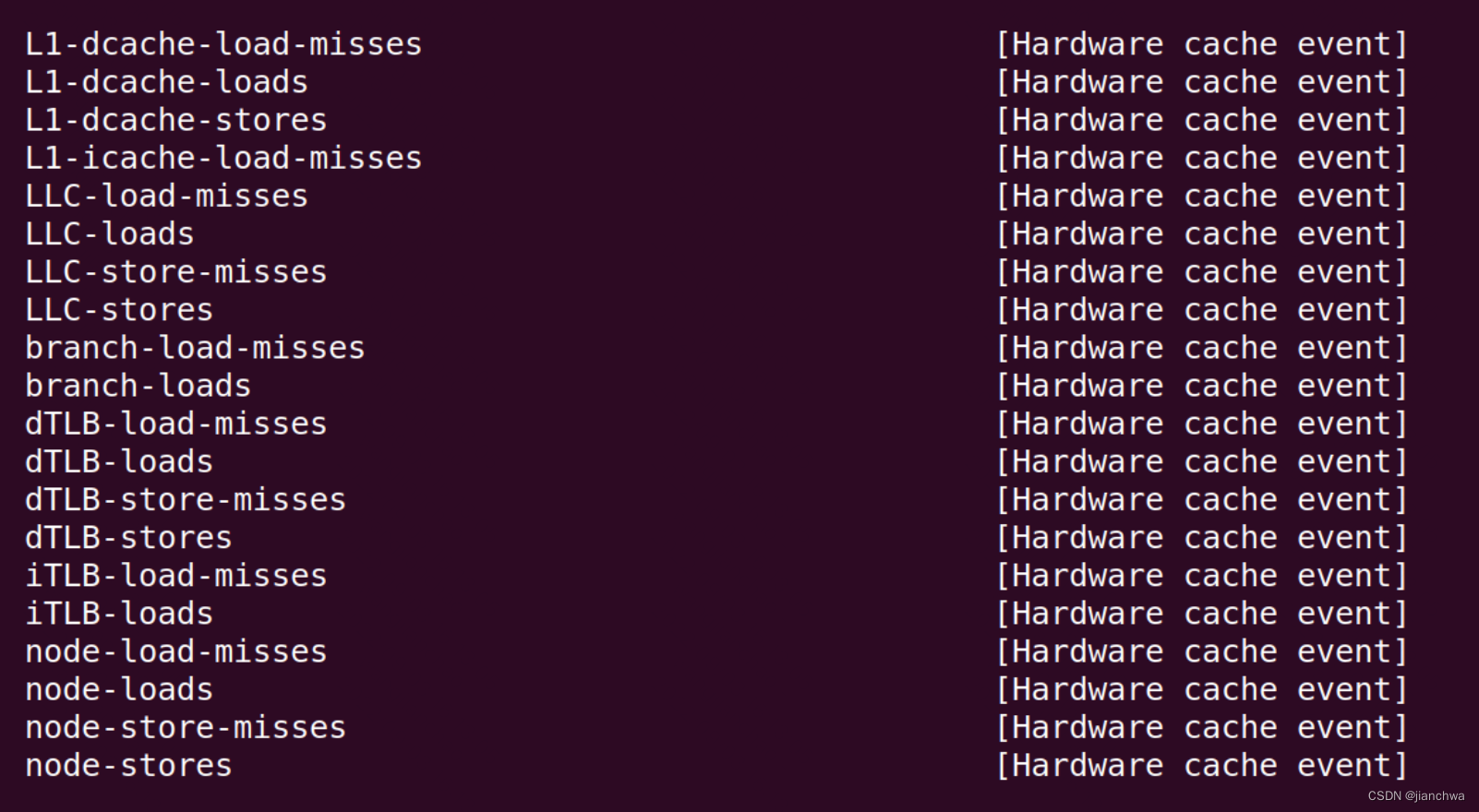
如何查看他们与intel pmu的对应关系 ?参考代码arch/x86/events/intel/core.c
intel_pmu_init()
---
case INTEL_FAM6_SKYLAKE_MOBILE:
case INTEL_FAM6_SKYLAKE_DESKTOP:
case INTEL_FAM6_SKYLAKE_X:
case INTEL_FAM6_KABYLAKE_MOBILE:
case INTEL_FAM6_KABYLAKE_DESKTOP:
x86_pmu.late_ack = true;
memcpy(hw_cache_event_ids, skl_hw_cache_event_ids, sizeof(hw_cache_event_ids));
...
name = "skylake";
...
}
snprintf(pmu_name_str, sizeof(pmu_name_str), "%s", name);
---
- 查看intel微架构版本,具体微架构历史可以参考,List of Intel CPU microarchitectures
 https://en.wikipedia.org/wiki/List_of_Intel_CPU_microarchitectures 查看方法:cat /sys/devices/cpu/caps/pmu_name;比如Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz,显示的是skylake;
https://en.wikipedia.org/wiki/List_of_Intel_CPU_microarchitectures 查看方法:cat /sys/devices/cpu/caps/pmu_name;比如Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz,显示的是skylake; - 参考skl_hw_cache_event_ids,比如iTLB相关:

事件的具体意义可以参考Intel PMU Hardware Event![]() https://perfmon-events.intel.com/skylake.html
https://perfmon-events.intel.com/skylake.html
另外,相关事件的描述中,有一个单词,"retired",其意义可以参考连接performance - What does Intel mean by "retired"? - Stack Overflow
n the context "retired" means: the instruction (microoperation, μop) leaves the "Retirement Unit". It means that in Out-of-order CPU pipeline the instruction is finally executed and its results are correct and visible in the architectural state as if they execute in-order. In performance context this is the number you should check to compute how many instructions were really executed (with useful output)
Cache类
http://www.cs.uni.edu/~diesburg/courses/cs3430_sp14/sessions/s14/s14_caching_and_tlbs.pdf
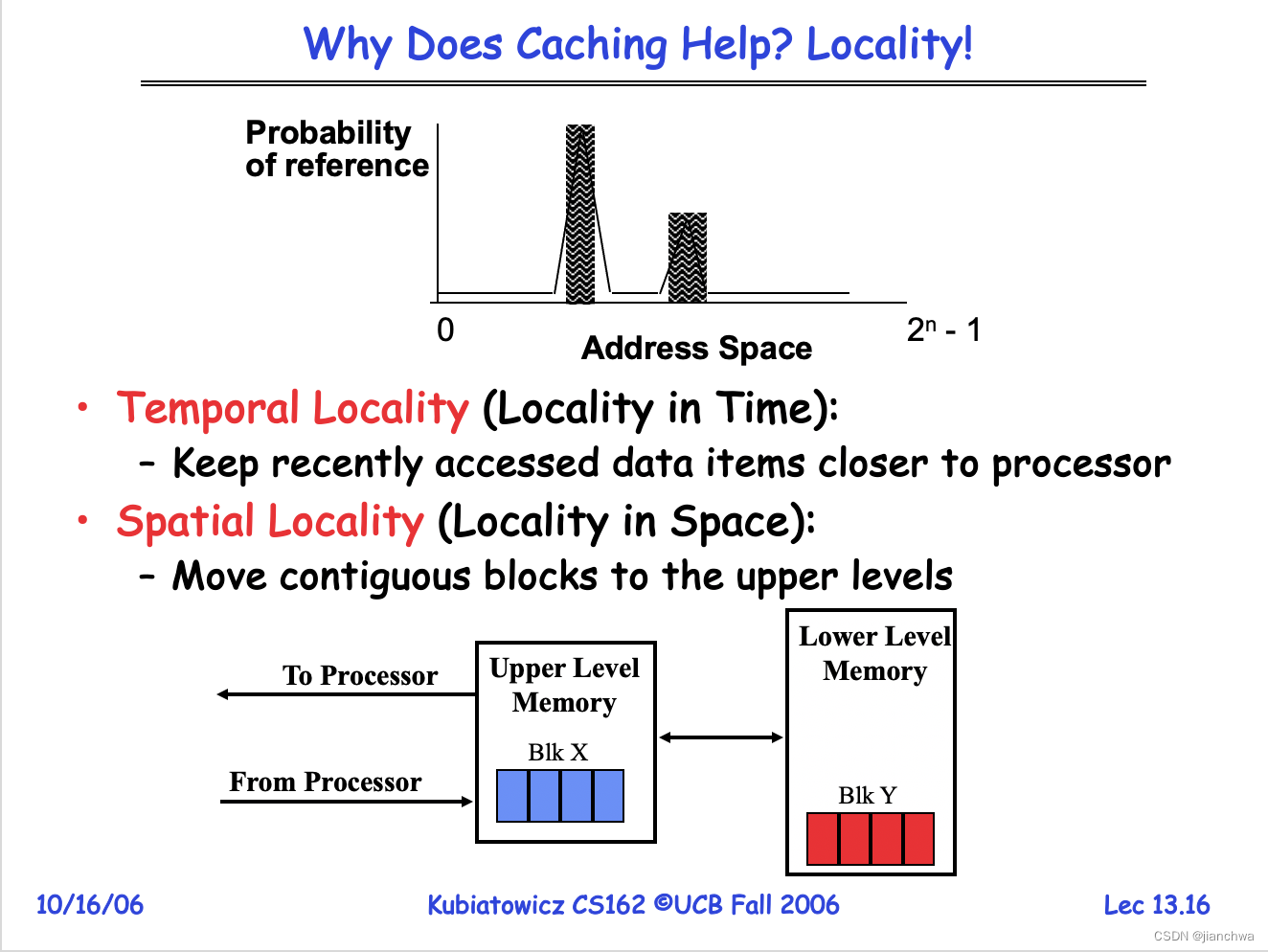
Cache的组织结构:
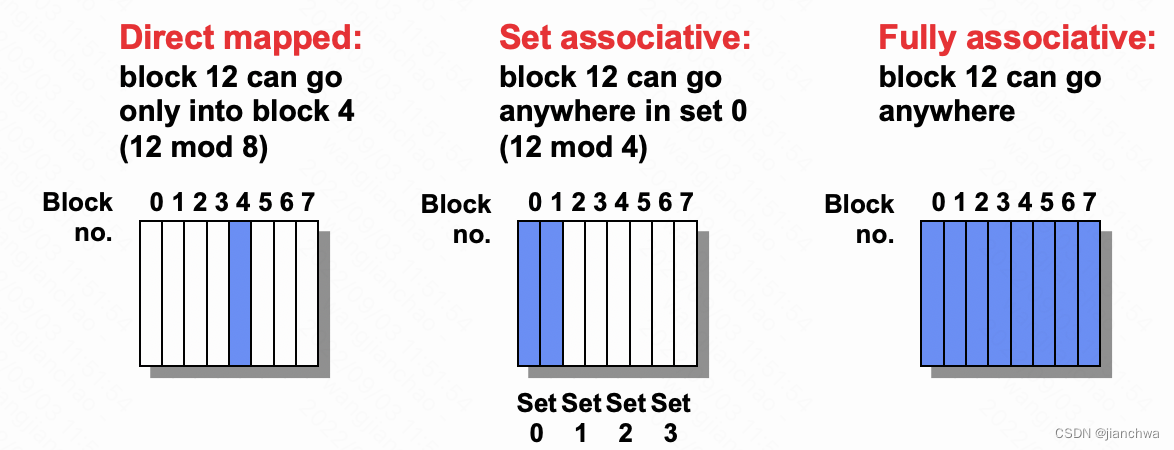
这三种类型可以直观的理解为:数组、hash表、链表;
比如:32-KB, 8-way set associative, 64-byte line size
- cache总容量是32K
- 每个组容量为 8 * 64 Bytes
- 总共有 2^15 / 2^9 = 2^6 64个组
另外,cache hierarchy还有inclusive和exclusive,参考连接Memory part 2: CPU caches [LWN.net] Section 3.2中的一段:
To be able to load new data in a cache it is almost always first necessary to make room in the cache. An eviction from L1d pushes the cache line down into L2 (which uses the same cache line size). This of course means room has to be made in L2. This in turn might push the content into L3 and ultimately into main memory. Each eviction is progressively more expensive. What is described here is the model for an exclusive cache as is preferred by modern AMD and VIA processors. Intel implements inclusive caches {This generalization is not completely correct. A few caches are exclusive and some inclusive caches have exclusive cache properties.} where each cache line in L1d is also present in L2. Therefore evicting from L1d is much faster. With enough L2 cache the disadvantage of wasting memory for content held in two places is minimal and it pays off when evicting. A possible advantage of an exclusive cache is that loading a new cache line only has to touch the L1d and not the L2, which could be faster.d
总结起来就是,cache上下层之间的关系,分成两种:
- inclusive,上下层之间会保存相同的内容
- exclusive,下层只是作为上层的victim cache
TLB
TLB结构与层级

TLB Entry的格式并未找官方的Xeon的文档,不过可以参考Nios_II的3.2.4. TLB Organization
TLB Tag Fomat
| Field Name | Description |
|---|---|
| VPN | VPN is the virtual page number field. This field is compared with the top 20 bits of the virtual address. |
| PID | PID is the process identifier field. This field is compared with the value of the current process identifier stored in the tlbmisc control register, effectively extending the virtual address. The field size is configurable in the Nios_II Processor parameter editor, and can be between 8 and 14 bits. |
| G | G is the global flag. When G = 1, the PID is ignored in the TLB lookup. |
TLB Data Format
| Field Name | Description |
|---|---|
| PFN | PFN is the physical frame number field. This field specifies the upper bits of the physical address. The size of this field depends on the range of physical addresses present in the system. The maximum size is 20 bits. |
| C | C is the cacheable flag. Determines the default data cacheability of a page. Can be overridden for data accesses using I/O load and store family of Nios II instructions. |
| R | R is the readable flag. Allows load instructions to read a page. |
| W | W is the writable flag. Allows store instructions to write a page. |
| X | X is the executable flag. Allows instruction fetches from a page. |
任务切换
需要特别关注的是PID和G,这关系到当切换上下文时,是否需要invalidate tlb;
参考文档
Intel® 64 and IA-32 Architectures Software Developer’s Manual
Volume 3A: System Programming Guide, Part 1 September 2016
4.10.1 Process-Context Identifiers (PCIDs)
Process-context identifiers (PCIDs) are a facility by which a logical processor may cache information for multiple linear-address spaces. The processor may retain cached information when software switches to a different linear- address space with a different PCID (e.g., by loading CR3; see Section 4.10.4.1 for details)
A PCID is a 12-bit identifier. Non-zero PCIDs are enabled by setting the PCIDE flag (bit 17) of CR4. If CR4.PCIDE = 0, the current PCID is always 000H; otherwise, the current PCID is the value of bits 11:0 of CR3. Not all processors allow CR4.PCIDE to be set to 1.
When a logical processor creates entries in the TLBs (Section 4.10.2) and paging-structure caches (Section 4.10.3), it associates those entries with the current PCID. When using entries in the TLBs and paging-structure caches to translate a linear address, a logical processor uses only those entries associated with the current PCID.
4.10.4.1 Operations that Invalidate TLBs and Paging-Structure Caches
MOV to CR3. The behavior of the instruction depends on the value of CR4.PCIDE:
— If CR4.PCIDE = 1 and bit 63 of the instruction’s source operand is 0, the instruction invalidates all TLB entries associated with the PCID specified in bits 11:0 of the instruction’s source operand except those for global pages. It also invalidates all entries in all paging-structure caches associated with that PCID. It is not required to invalidate entries in the TLBs and paging-structure caches that are associated with other PCIDs.
4.10.4 Invalidation of TLBs and Paging-Structure Caches
As noted in Section 4.10.2 and Section 4.10.3, the processor may create entries in the TLBs and the paging-struc- ture caches when linear addresses are translated, and it may retain these entries even after the paging structures used to create them have been modified. To ensure that linear-address translation uses the modified paging structures, software should take action to invalidate any cached entries that may contain information that has since been modified.
上文中提到的global pages,来自页表项中的一位,参考下图:
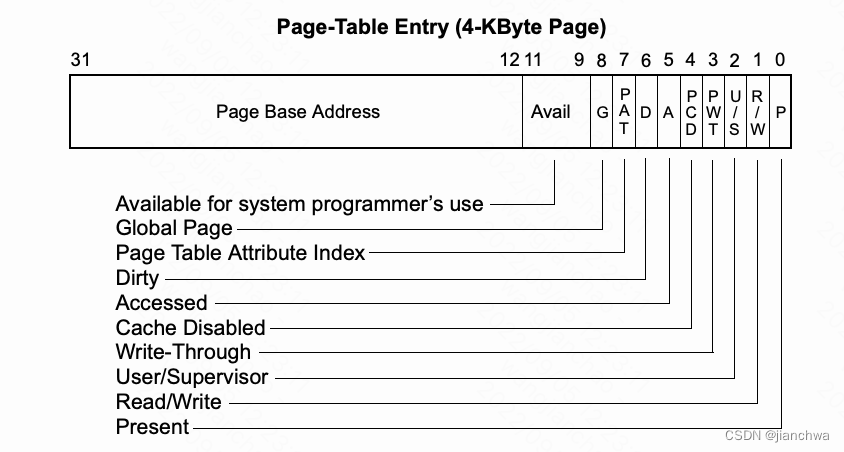 (该图来自2006版本)
(该图来自2006版本)
在Linux内核中,相关代码为:
arch/x86/mm/tlb.c
上下文切换的过程中,ASID的切换,
switch_mm_irqs_off()
---
if (real_prev == next) {
...
} else {
u16 new_asid;
bool need_flush;
...
next_tlb_gen = atomic64_read(&next->context.tlb_gen);
choose_new_asid(next, next_tlb_gen, &new_asid, &need_flush);
if (need_flush) {
this_cpu_write(cpu_tlbstate.ctxs[new_asid].ctx_id, next->context.ctx_id);
this_cpu_write(cpu_tlbstate.ctxs[new_asid].tlb_gen, next_tlb_gen);
load_new_mm_cr3(next->pgd, new_asid, true);
} else {
/* The new ASID is already up to date. */
load_new_mm_cr3(next->pgd, new_asid, false);
...
}
...
}
---这里有三个关键的值:
- asid,per-cpu只有6个,(TLB_NR_DYN_ASIDS 6),所有到该CPU上的任务,轮着用
choose_new_asid() --- /* * We don't currently own an ASID slot on this CPU. * Allocate a slot. */ *new_asid = this_cpu_add_return(cpu_tlbstate.next_asid, 1) - 1; if (*new_asid >= TLB_NR_DYN_ASIDS) { *new_asid = 0; this_cpu_write(cpu_tlbstate.next_asid, 1); } *need_flush = true; --- - ctx_id,每个任务都有一个ctx_id,是一个全局的原子变量,这个ctx_id用于区分当前cpu上是否有已经持有的asid,这决定了,下一步是不是需要申请新的asid,如果申请,就涉及到invalidate掉该asid之前对应的tlb entry;
init_new_context() --- mm->context.ctx_id = atomic64_inc_return(&last_mm_ctx_id); atomic64_set(&mm->context.tlb_gen, 0); --- choose_new_asid() --- for (asid = 0; asid < TLB_NR_DYN_ASIDS; asid++) { if (this_cpu_read(cpu_tlbstate.ctxs[asid].ctx_id) != next->context.ctx_id) continue; *new_asid = asid; *need_flush = (this_cpu_read(cpu_tlbstate.ctxs[asid].tlb_gen) < next_tlb_gen); return; } --- - tlb_gen,per-mm,即地址空间;即使是同一个context的tlb也可能需要flush
flush_tlb_mm_range() --- /* This is also a barrier that synchronizes with switch_mm(). */ info.new_tlb_gen = inc_mm_tlb_gen(mm); --- return atomic64_inc_return(&mm->context.tlb_gen); --- ---
Perf监测
看下面这组perf采集的数据:
perf stat -e dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads make O=../out -j20 > /dev/null
Performance counter stats for 'make O=../out -j20':
10,095,672,437 dTLB-load-misses # 0.09% of all dTLB cache hits (63.78%)
10,869,338,077,000 dTLB-loads (63.77%)
3,475,643,439 dTLB-store-misses (63.77%)
5,408,658,177,811 dTLB-stores (63.77%)
8,101,851,811 iTLB-load-misses # 22.88% of all iTLB cache hits (63.76%)
35,402,725,030 iTLB-loads (63.77%)
684.556635266 seconds time elapsed
各项对应的intel的pmu事件是:
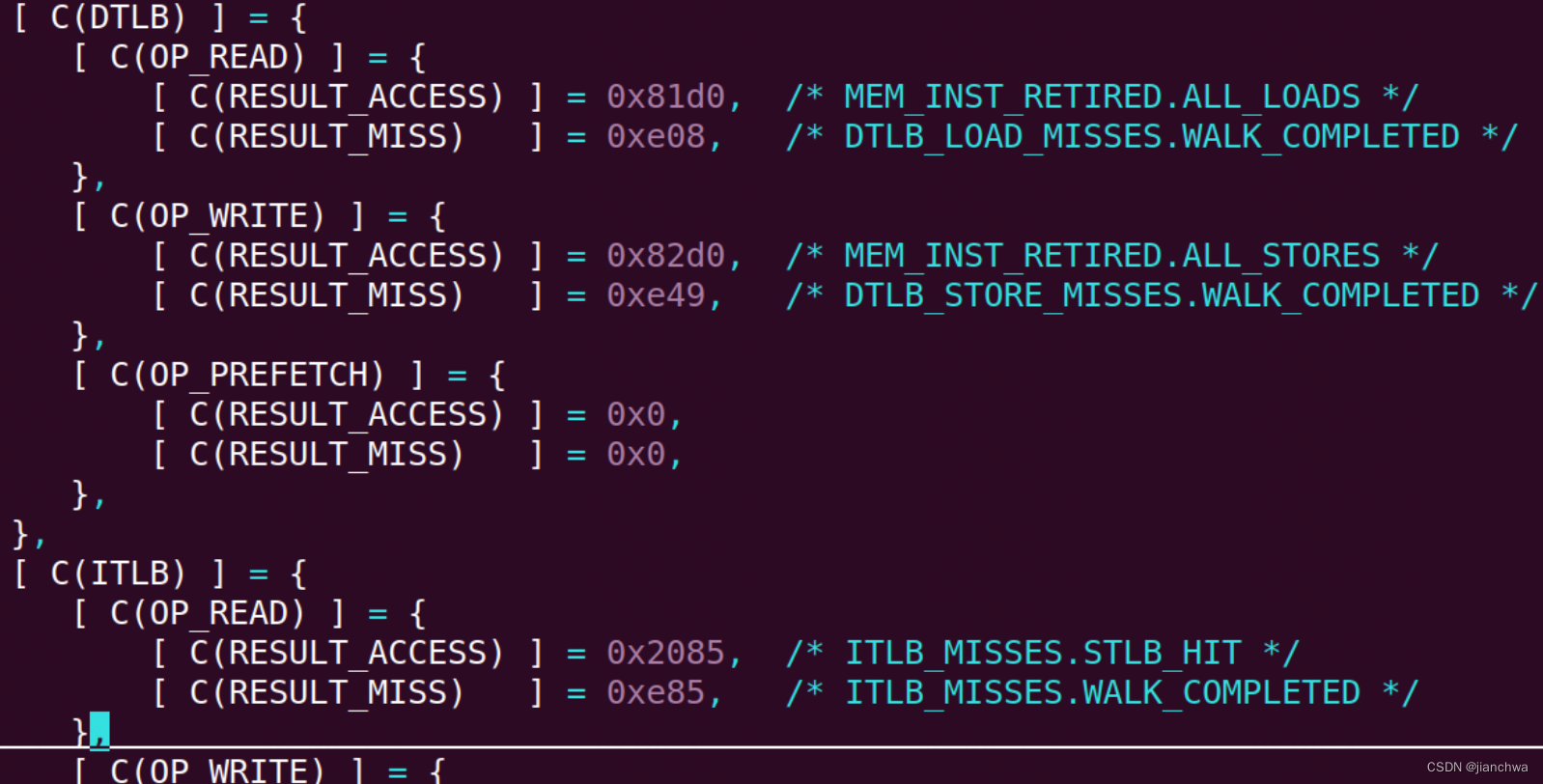
- dTLB-loads,MEM_INST_RETIRED.ALL_LOADS,All retired load instructions;这里使用的计数是,执行成功的所有load指令;
- dTLB-load-misses,DTLB_LOAD_MISSES.WALK_COMPLETED,Counts completed page walks (all page sizes) caused by demand data loads. This implies it missed in the DTLB and further levels of TLB
- dTLB-store,MEM_INST_RETIRED.ALL_STORES,All retired instructions
- dTLB-store-misses,DTLB_STORE_MISSES.WALK_COMPLETED,Counts completed page walks (all page sizes) caused by demand data stores. This implies it missed in the DTLB and further levels of TLB
- iTLB-loads,ITLB_MISSES.STLB_HIT,Instruction fetch requests that miss the ITLB and hit the STLB
- iTLB-load-misses,ITLB_MISSES.WALK_COMPLETED,Counts completed page walks (all page sizes) caused by a code fetch. This implies it missed in the ITLB (Instruction TLB) and further levels of TLB
Cache
结构和层级
还是以Intel skylate为例,参考以下文档:
Skylake (server) - Microarchitectures - Intel - WikiChip
它的cache hiearchy为:
- L1I Cache:
- 32 KiB/core, 8-way set associative
- 64 sets, 64 B line size
- competitively shared by the threads/core
- L1D Cache:
- 32 KiB/core, 8-way set associative
- 64 sets, 64 B line size
- competitively shared by threads/core
- 4 cycles for fastest load-to-use (simple pointer accesses)
- 5 cycles for complex addresses
- 128 B/cycle load bandwidth
- 64 B/cycle store bandwidth
- Write-back policy
- L2 Cache:
- 1 MiB/core, 16-way set associative
- 64 B line size
- Inclusive
- 64 B/cycle bandwidth to L1$
- Write-back policy
- 14 cycles latency
- L3 Cache:
- 1.375 MiB/core, 11-way set associative, shared across all cores
- 2,048 sets, 64 B line size
- Non-inclusive victim cache
- Write-back policy
- 50-70 cycles latency
我们看到,L2是Inclusive的而L3是Non-inclusive的,这是什么意思?参考文档:Skylake Processors - HECC Knowledge Base
An inclusive L3 cache guarantees that every block that exists in the L2 cache also exists in the L3 cache. A non-inclusive L3 cache does not guarantee this.
A larger L2 cache increases the hit rate into the L2 cache, resulting in lower effective memory latency and lower demand on the mesh interconnect and L3 cache.
If the processor has a miss on all the levels of the cache, it fetches the line from memory and puts it directly into the L2 cache of the requesting core, rather than putting a copy into both the L2 and L3 caches, as is done on Broadwell. When the cache line is evicted from the L2 cache, it is placed into L3 if it is expected to be reused.
Due to the non-inclusive nature of the L3 cache, the absence of a cache line in L3 does not indicate that the line is absent in private caches of any of the cores. Therefore, a snoop filter is used to keep track of the location of cache lines in the L1 or L2 caches of cores when a cache line is not allocated in L3. On the previous-generation processors, the shared L3 itself takes care of this task.
正如对L3的特性描述,它是Non-inclusive Victim Cache。
也找到了类似的描述:
Perf监测
Perf监测的相关事件分别对应了那些Hardware Event呢?
Performance counter stats for 'make O=../out -j20':
586,724,859,432 L1-dcache-load-misses # 5.40% of all L1-dcache hits (95.80%)
10,872,724,488,141 L1-dcache-loads (95.85%)
5,408,474,346,992 L1-dcache-stores (95.84%)
930,699,520,202 L1-icache-load-misses (95.79%)
725.217684983 seconds time elapsed
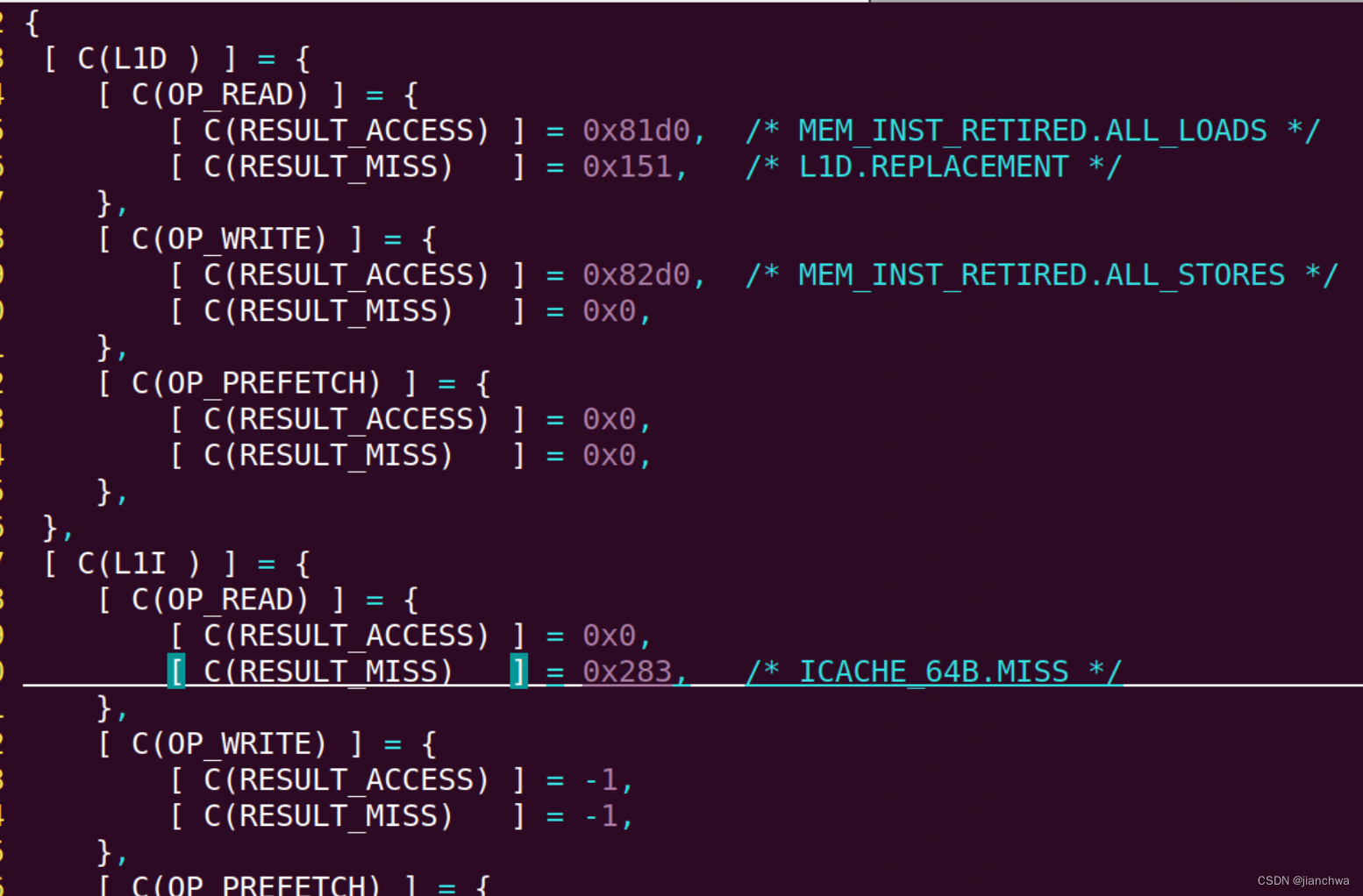
- L1-dcache-loads,MEM_INST_RETIRED.ALL_LOADS,All retired load instructions;这里使用的计数是,执行成功的所有load指令;这与dTLB-loads一样
- L1-dcache-load-misses,L1D.REPLACEMENT,Counts L1D data line replacements including opportunistic replacements, and replacements that require stall-for-replace or block-for-replace;
- L1-dcache-stores,MEM_INST_RETIRED.ALL_STORES,All retired store instructions
- L1-icache-misses,ICACHE_64B.MISS,Instruction fetch tag lookups that miss in the instruction cache (L1I). Counts at 64-byte cache-line granularity.















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









