







问题描述
有一组字符集{c1, c2, …, cn},在使用这组字符集的过程中,通过统计发现每个字符都有其相应的出现频率,假设对应的频率为{f1, f2, …, fn}。现在需要对这些字符进行二进制编码,我们希望的编码结果如下:每个字符都有其独一无二的编码;编码长度是变长的,频率大的字符使用更少的二进制位进行编码,频率小的字符则使用比较多的二进制位进行编码,使得最终的平均编码长度达到最短;每个字符的编码都有特定的前缀,一个字符的编码不可能会是另一个字符的前缀,这样我们可以在读取编码时,当读取的二进制位可以对应一个字符时,就读取出该字符。举个例子,假如我们有字符集{‘a’, ‘b’, ‘c’},字符’a’的编码为001,字符’b’的编码为010,那么此时c的编码不能为00或者01,这样我们才能识别’a’和’c’或者’b’和’c’。
算法描述
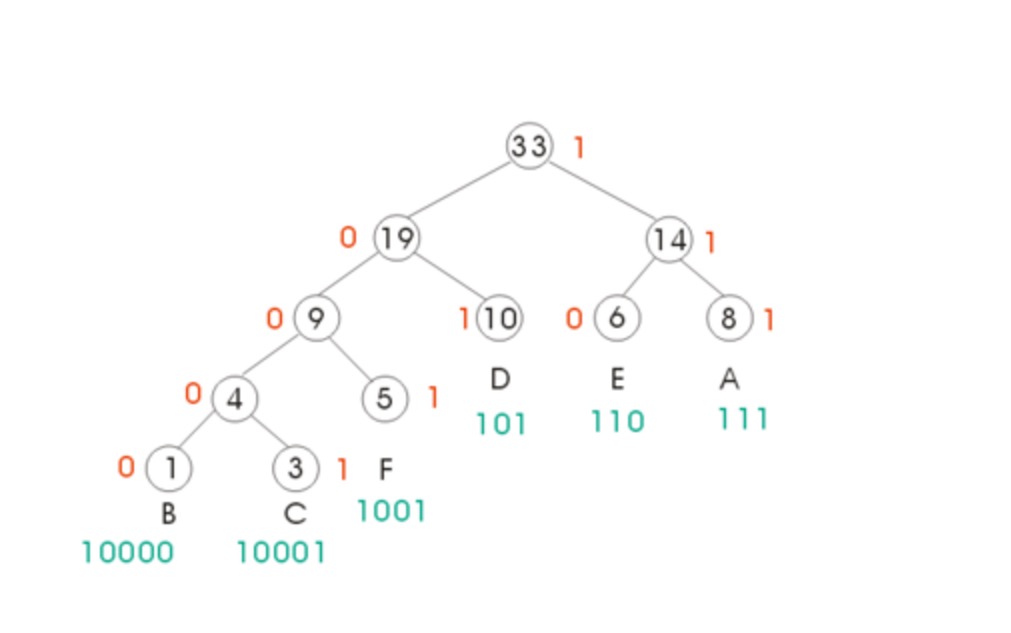
上述问题可以使用Huffman编码来解决,Huffman编码实际上是一个贪心算法。在这个算法中,使用二叉树来表示前缀码,每个字符都是树的叶子结点,非叶子结点则不代表任何字符。将每个字符构造成结点形成结点集S,每次都从结点集S中选出频率最低的两个结点x和y作为子节点进行建树,为这两个子结点构造一个父节点,父节点不保存任何字符,父节点的频率为两个子节点频率之和,将两个子节点从S中移走,将父节点加入S中。不断迭代下去,直到S只剩一个结点时,这个结点就是树的根节点。这样我们就得到了一棵Huffman树,整个过程就是一个自底向上的建树过程。由于从根节点到每个叶子节点有且仅有一条路径,所以,每个叶子的路径都是不一样的,唯一的。我们把从根节点到叶子节点的路径记录下来,便可作为叶子节点上字符的编码。初始化编码为空,从根节点开始,往左走则编码加0,往右走则编码加1,具体展示图如下所示:
建树过程的伪代码如下:
给定字符集C={c1,c2,...,cn},每个字符ci都有相应的频率fi
根据字符集构建结点集S={s1,s2,...,sn},每个结点si保存有字符ci和频率fi的信息
while |S| != 1 do
取出S中频率最小的两个结点x和y;
构造父节点z;
z.f = x.f + y.f;
z.c = undefined;
z.left = x;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5957
5957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









