







Pre-training large language models(预训练大语言模型)
In the previous video, you were introduced to the generative AI project life cycle. As you saw, there are a few steps to take before you can get to the fun part, launching your generative AI app. Once you have scoped out your use case, and determined how you'll need the LLM to work within your application, your next step is to select a model to work with. Your first choice will be to either work with an existing model, or train your own from scratch. There are specific circumstances where training your own model from scratch might be advantageous, and you'll learn about those later in this lesson.

In general, however, you'll begin the process of developing your application using an existing foundation model. Many open-source models are available for members of the AI community like you to use in your application. The developers of some of the major frameworks for building generative AI applications like Hugging Face and PyTorch, have curated hubs where you can browse these models. A really useful feature of these hubs is the inclusion of model cards, that describe important details including the best use cases for each model, how it was trained, and known limitations. You'll find some links to these model hubs in the reading at the end of the week.
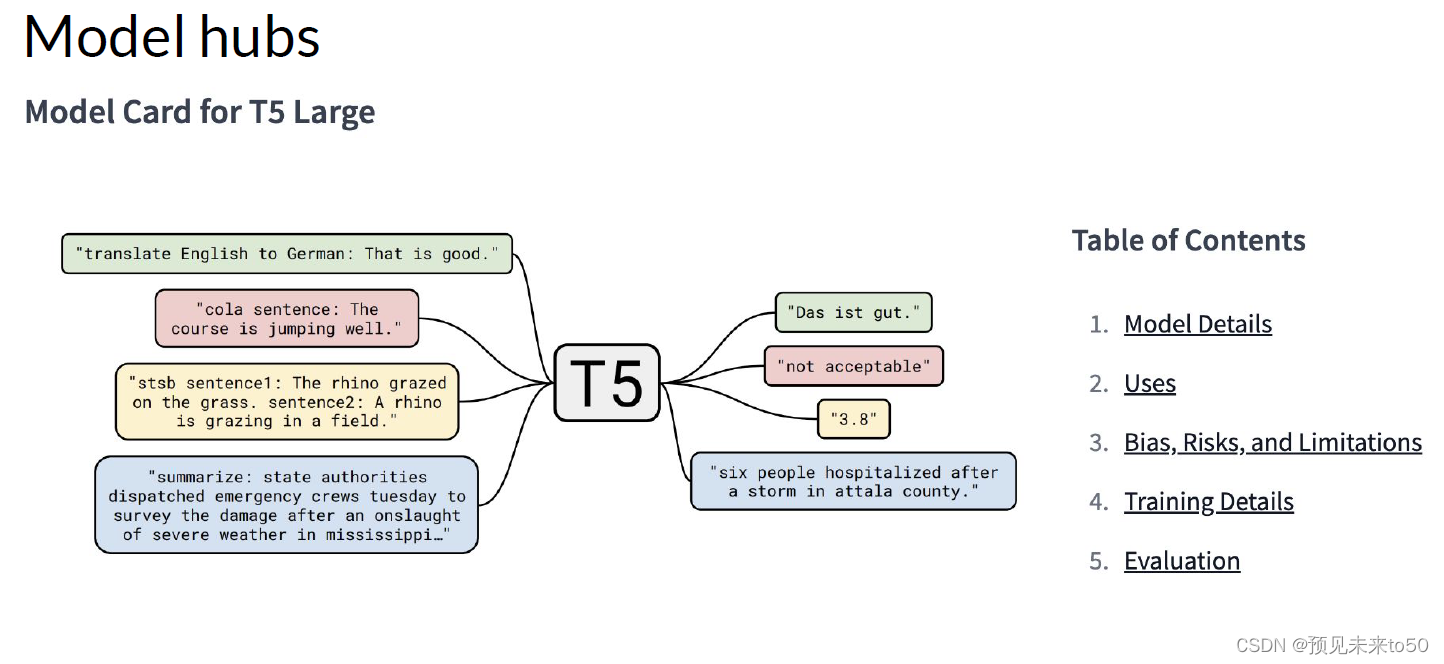
The exact model that you'd choose will depend on the details of the task you need to carry out. Variance of the transformer model architecture are suited to different language tasks, largely because of differences in how the models are trained. To help you better understand these differences and to develop intuition about which model to use for a particular task, let's take a closer look at how large language models are trained. With this knowledge in hand, you'll find it easier to navigate the model hubs and find the best model for your use case.
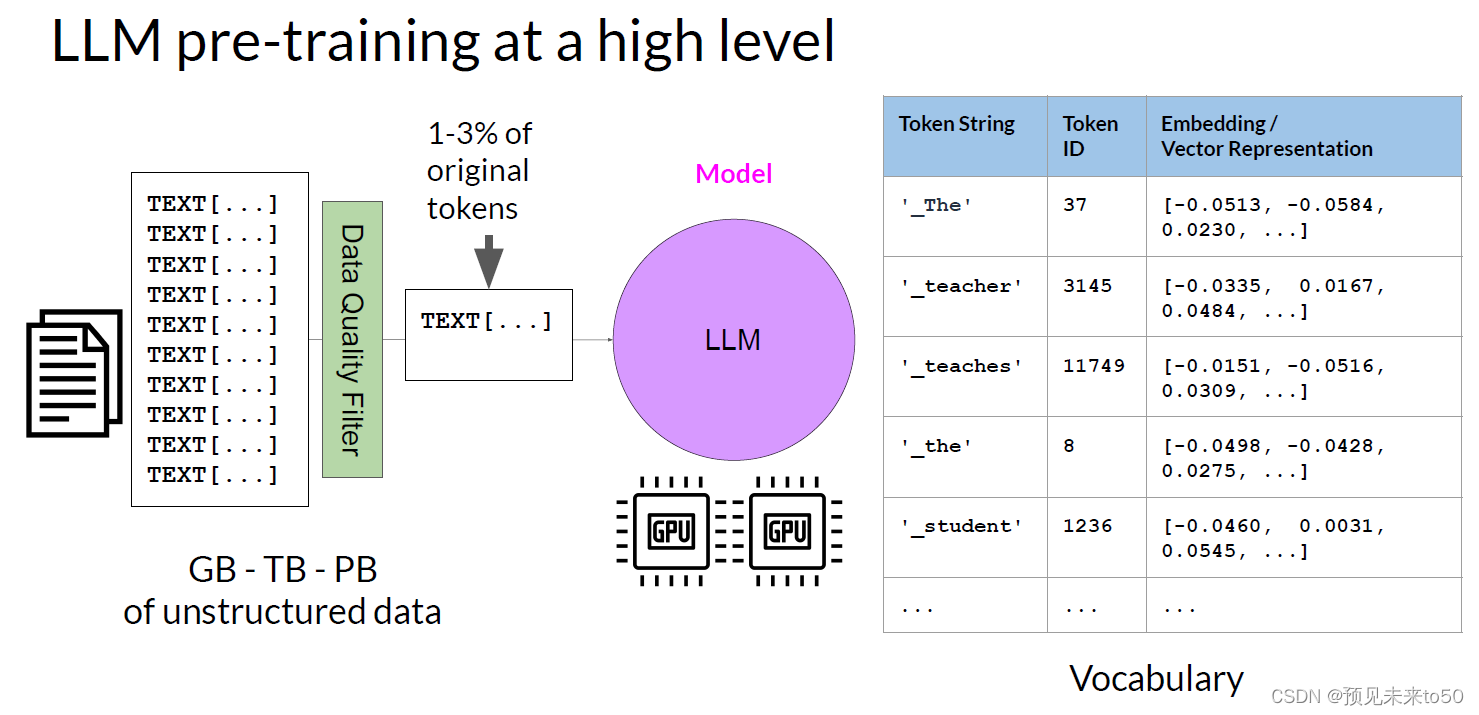
To begin, let's take a high-level look at the initial training process for LLMs. This phase is often referred to as pre-training. As you saw in Lesson 1, LLMs encode a deep statistical representation of language. This understanding is developed during the models pre-training phase when the model learns from vast amounts of unstructured textual data. T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









