







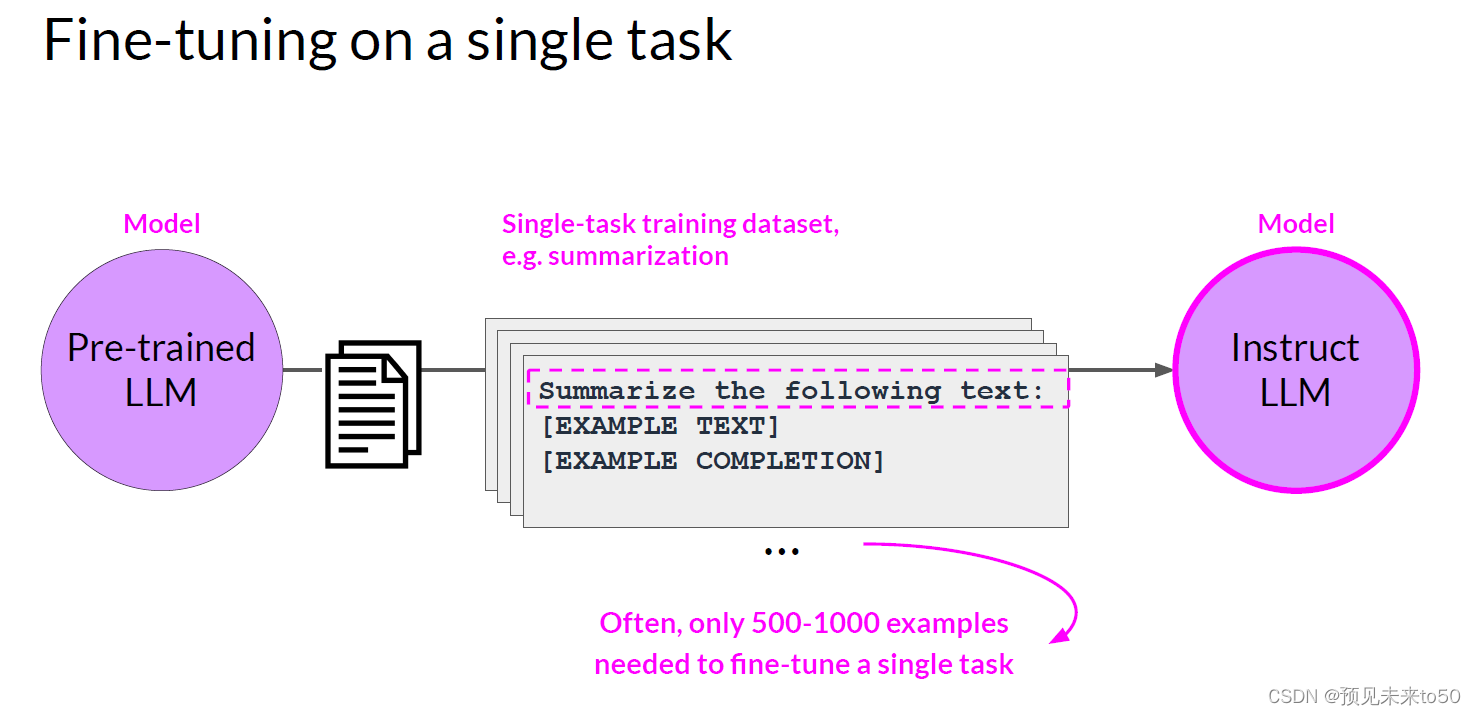
Fine-tuning on a single task(单任务微调)
While LLMs have become famous for their ability to perform many different language tasks within a single model, your application may only need to perform a single task. In this case, you can fine-tune a pre-trained model to improve performance on only the task that is of interest to you. For example, summarization using a dataset of examples for that task. Interestingly, good results can be achieved with relatively few examples. Often just 500-1,000 examples can result in good performance in contrast to the billions of pieces of texts that the model saw during pre-training.
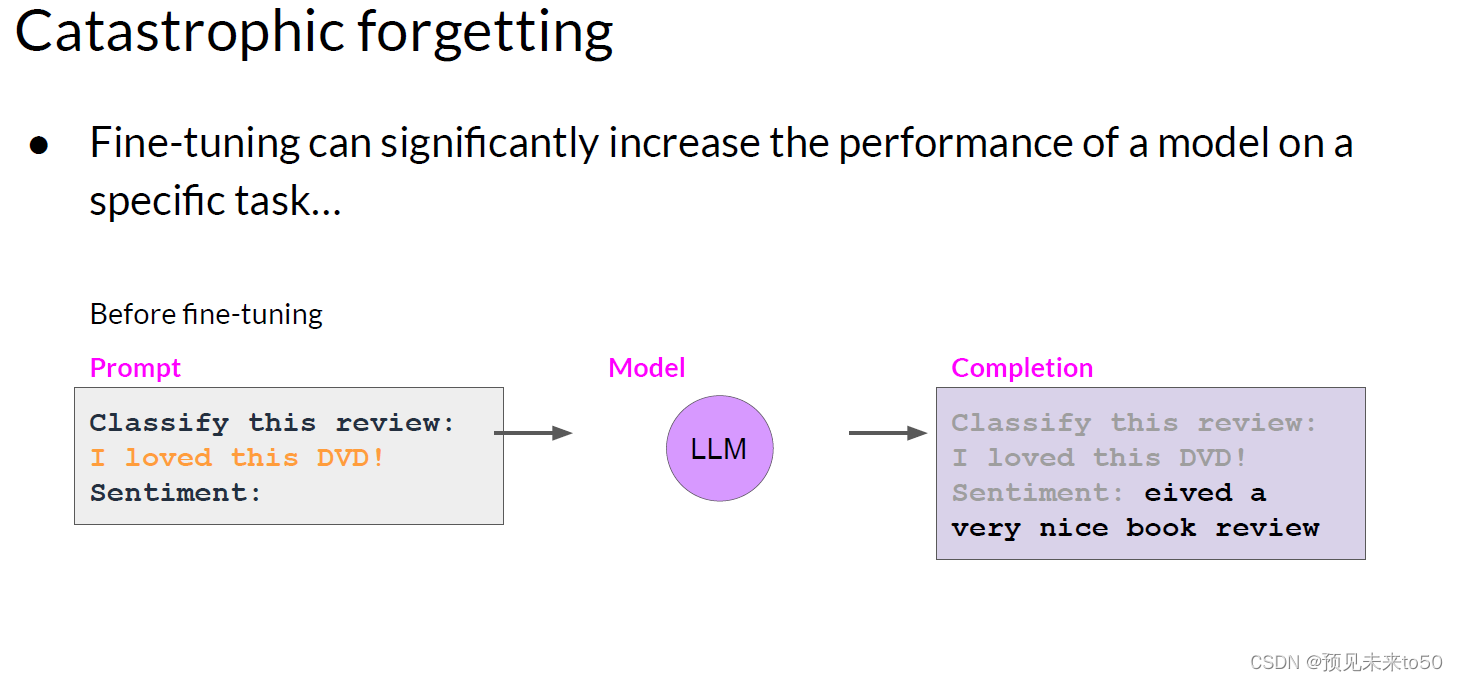
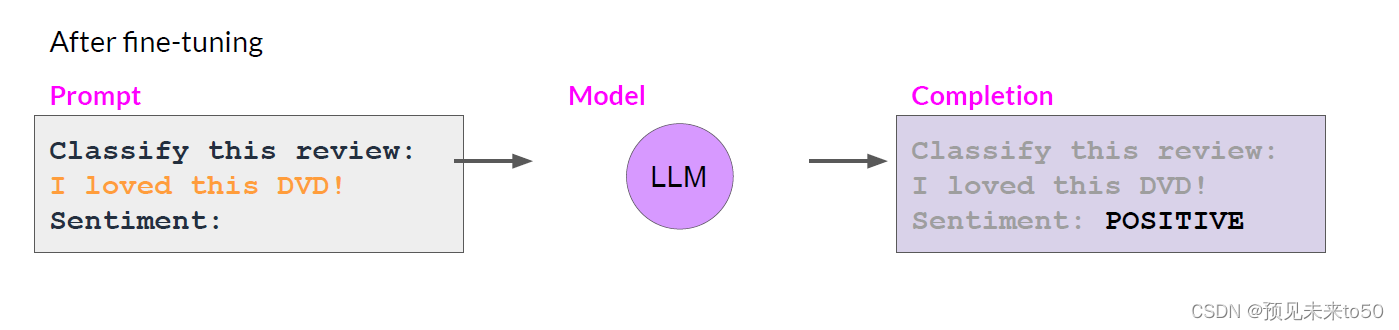
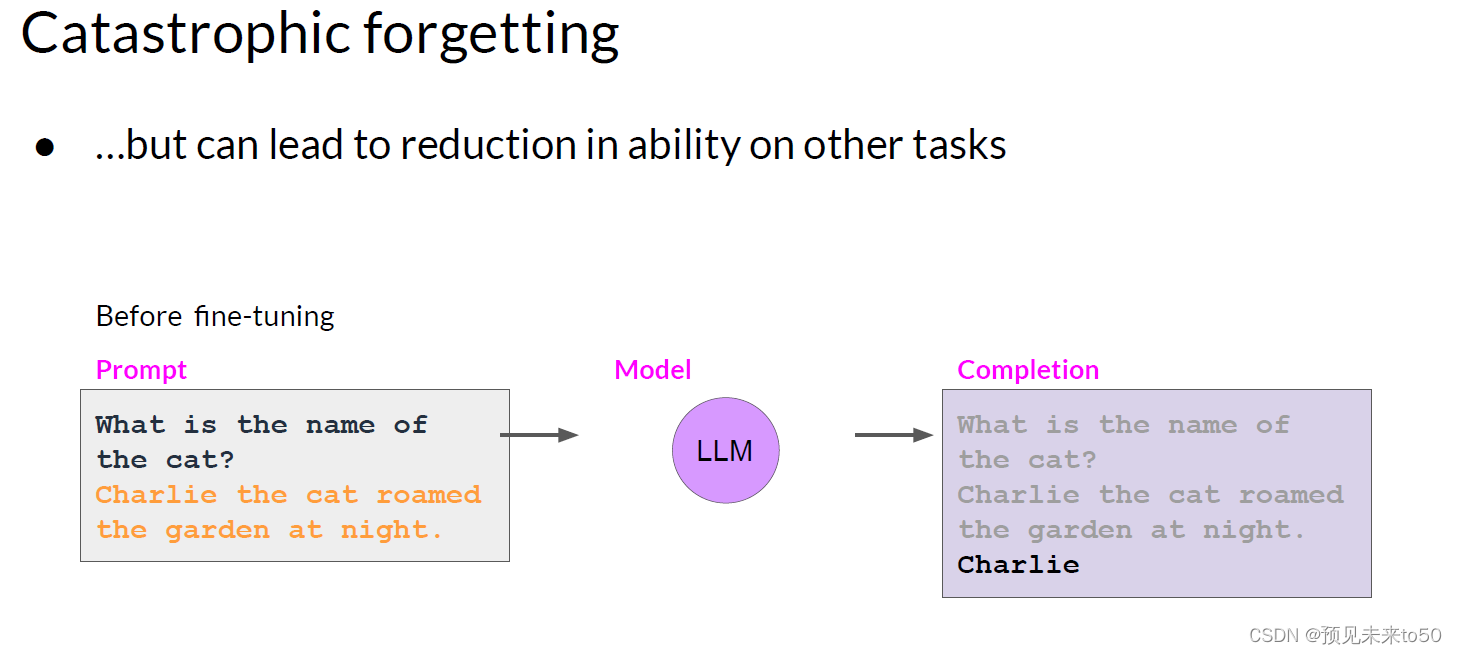
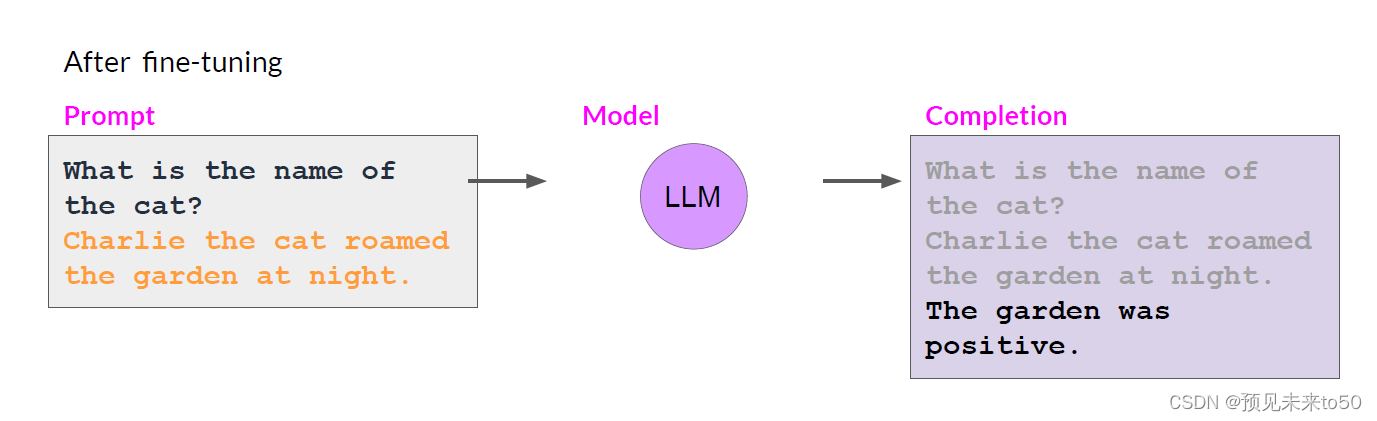
However, there is a potential downside to fine-tuning on a single task. The process may lead to a phenomenon called catastrophic forgetting. Catastrophic forgetting happens because the full fine-tuning process modifies the weights of the original LLM. While this leads to great performance on the single fine-tuning task, it can degrade performance on other tasks. For example, while fine-tuning can improve the ability of a model to perform sentiment analysis on a review and result in a quality completion, the model may forget how to do other tasks. This model knew how to carry out named entity recognition before fine-tuning correctly identifying Charlie as the name of the cat in the sentence. But after fine-tuning, the model can no longer carry out this task, confusing both the entity it is supposed to identify and exhibiting behavior related to the new task.
What options do you have to avoid catastrophic forgetting? First of all, it's important to decide whether catastrophic forgetting actually impacts your use case. If all you need is reliable performance on the single task you fine-tuned on, it may not be an issue that the model can't generalize to other tasks. If you do want or need the model to maintain its multitask generalized capabilities, you can perform fine-tuning on multiple tasks at one time. Good multitask fine-tuning may require 50-100,000 examples across many tasks, and so will require more data and compute to train. Will discuss this option in more detail shortly. Our second option is to perform parameter efficient fine-tuning, or PEFT for short instead of full fine-tuning. PEFT is a set of techniques that preserves the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters. PEFT shows greater robustness to catastrophic forgetting since most of the pre-trained weights are left unchanged. PEFT is an exciting and active area of research that we will cover later this week. In the meantime, let's move on to the next video and take a closer look at multitask fine-tuning.

虽然LLM因其在单个模型内执行许多不同语言任务的能力而闻名,但你的应用程序可能只需要执行单个任务。在这种情况下,你可以微调预训练模型以提高你只对其感兴趣的任务的性能。例如,使用该任务的示例数据集进行摘要。有趣的是,相对较少的示例也可以取得良好的结果。通常,只需500-1000个示例就可以在与预训练期间模型看到的数十亿文本相比,取得良好的性能。然而,对单一任务进行微调可能存在一个潜在的缺点。这个过程可能导致一种称为灾难性遗忘的现象。
灾难性遗忘是因为完整的微调过程修改了原始LLM的权重。虽然这可以导致在单个微调任务上表现出色,但它可能会降低在其他任务上的性能。例如,虽然微调可以提高模型执行评论情感分析的能力并产生高质量的完成,但模型可能会忘记如何做其他任务。这个模型在微调之前知道如何执行命名实体识别,正确识别句子中的Charlie是猫的名字。但在微调之后,模型无法再执行此任务,混淆了它应该识别的实体,并表现出与新任务相关的行为。
你有什么选择来避免灾难性遗忘?首先,重要的是要决定灾难性遗忘是否真的影响你的用例。如果你只需要在你微调的单个任务上有可靠的表现,模型不能泛化到其他任务可能不是问题。如果你确实需要模型保持其多任务泛化能力,你可以同时对多个任务进行微调。良好的多任务微调可能需要跨越许多任务的50-100,000个示例,因此将需要更多的数据和计算来进行训练。我们将很快更详细地讨论这个选项。我们的第二个选择是执行参数高效的微调,或简称PEFT,而不是完整的微调。PEFT是一组技术,保留原始LLM的权重,只训练少量的任务特定适配器层和参数。PEFT对灾难性遗忘显示出更大的鲁棒性,因为大部分预训练的权重保持不变。PEFT是一个令人兴奋且活跃的研究领域,我们将在本周晚些时候介绍。与此同时,让我们继续下一个视频,更仔细地看看多任务微调。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









