






在智慧物联时代,设备智能化正经历从简单响应到深度推理的进化。萤石开放平台推出基于H20&昇腾910B的DeepSeek R1推理模型本地化方案,为开发者带来新一代长推理模型(Long Reasoning Models)私有化部署的服务,让智能硬件真正具备“深思熟虑”的能力。
随着DeepSeek-R1模型的广泛应用,越来越多的开发者开始尝试复现类似的模型,以提升其推理能力。目前已经涌现出不少令人瞩目的成果。然而,这些新模型的推理能力是否真的提高了呢?EvalScope框架是魔搭社区上开源的评估工具,提供了对R1类模型的推理性能的评测服务。
萤石团队在实验室基于H20&昇腾910B等服务器部署了DeepSeek-R1/QwQ-32B等大语言模型,通过728道推理题目(与R1技术报告一致)进行演示。评测数据具体包括:
| 序号 | 测评数据集 | 题目数量 | 说明 | 数据链接 |
| 1 | MATH-500 | 500 | 一组具有挑战性的高中数学竞赛问题数据集,涵盖七个科目(如初等代数、代数、数论)共500道题. 每个问题由一个数学表达式和对应答案组成,难度从1级(简单)到5级(复杂)不等. Level 1 题目数量:43 (容易) Level 2 题目数量:90 Level 3 题目数量:105 Level 4 题目数量:128 Level 5 题目数量:134(困难) | https://www.modelscope.cn/datasets/HuggingFaceH4/aime_2024 |
| 2 | GPQA-Diamond | 198 | 该数据集包含物理、化学和生物学子领域的硕士水平多项选择题,共198道题。 | https://modelscope.cn/datasets/AI-ModelScope/gpqa_diamond/summary |
| 3 | AIME-2024 | 30 | 美国邀请数学竞赛的数据集,包含30道数学题。 | https://modelscope.cn/datasets/AI-ModelScope/AIME_2024 |
*本最佳实践的流程包括安装相关依赖、准备模型、评测模型以及评测结果的可视化。
「测评框架安装与执
1.私有化环境下大模型部署步骤

昇腾910B DeepSeek R1 部署
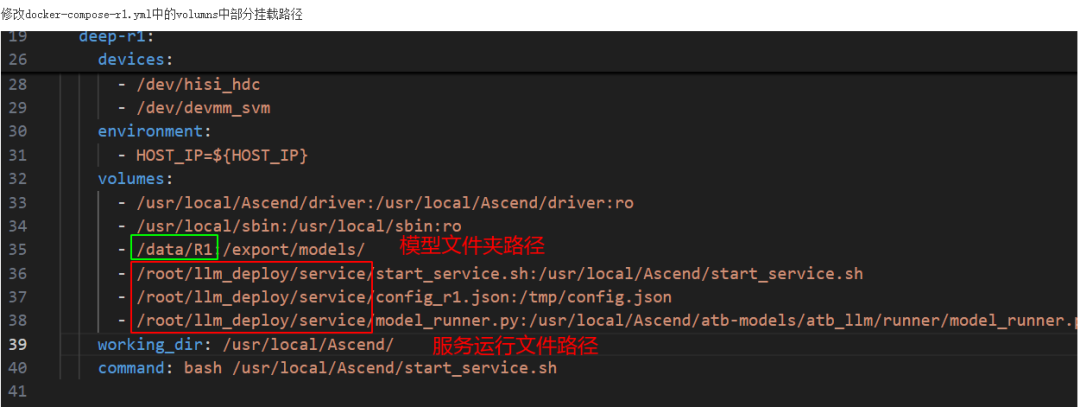
阿里云H20 DeepSeek R1 & QwQ-32B部署
1.1 docker安装,配置及镜像下载
1.2 安装 NVIDIA 容器工具包
1.3 vllm环境容器启动
1.4 模型运行
基于两台H20服务器分布式部署满血版Deepseek R1模型
# running on node1
ray start --head --dashboard-host 0.0.0.0
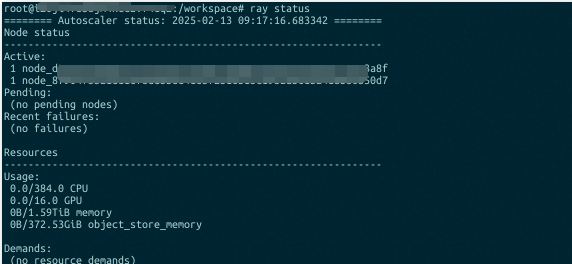
在其中一个ECS node1的容器vllm-engine上运行命令启动Deepseek R1的推理 serving 服务
vllm serve /data/models/DeepSeek-R1 \
--served-model-name DeepSeek-R1 \
--tensor-parallel-size 8 ……
2.测评框架安装
pip install 'evalscope[app,perf]' -U
3.测评框架执行
①
我们将MATH-500、GPQA-Diamond和AIME-2024三个数据集整合为一个数据集合,放置于modelscope/R1-Distill-Math-Test数据集中。
如果希望了解数据集的生成过程或者自行定制数据集合,可以参考(https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/collection/index.html)
②
配置评测任务(runtest.py)
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
task_cfg = TaskConfig(
model='DeepSeek-R1', # 模型名称 (需要与部署时的模型名称一致)
api_url='http://127.0.0.1:8801/v1', # 推理服务地址
api_key='EMPTY',
eval_type=EvalType.SERVICE, # 评测类型,SERVICE表示评测推理服务
datasets=[
'data_collection', # 数据集名称(固定为data_collection表示使用混合数据集)
],
dataset_args={
'data_collection': {
'dataset_id': 'modelscope/R1-Distill-Math-Test' # 数据集ID 或 数据集本地路径
}
},
eval_batch_size=32, # 发送请求的并发数
generation_config={ # 模型推理配置
'max_tokens': 20000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.6, # 采样温度 (deepseek 报告推荐值)
'top_p': 0.95, # top-p采样 (deepseek 报告推荐值)
'n': 5 # 每个请求产生的回复数量 (注意 lmdeploy 目前只支持 n=1)
},
stream=True # 是否使用流式请求,推荐设置为True防止请求超时
)
run_task(task_cfg=task_cfg)
③
执行评测任务
python3 runtest.py
④
输出结果:

「测评结果解
随着大语言模型的迅速发展,模型的推理能力得到了显著提升。特别是长推理模型(Long Reasoning Models),如OpenAI的o1、QwQ-32B、DeepSeek-R1-671B和Kimi K1.5等,因其展现出类似人类的深度思考能力而备受关注。这些模型通过长时间推理(Inference-Time Scaling),能够在解码阶段不断思考并尝试新的思路来得到正确的答案。
然而,随着研究的深入,科研人员发现这些模型在推理过程中存在两个极端问题:Underthinking(思考不足) 和Overthinking(过度思考) :
Underthinking(思考不足):现象指的是模型在推理过程中频繁地进行思路跳转,反复使用“alternatively”、“but wait”、“let me reconsider”等词,无法将注意力集中在一个正确的思路上并深入思考,从而得到错误答案。这种现象类似于人类的"注意力缺陷多动障碍",影响了模型的推理质量。
Overthinking(过度思考):现象则表现为模型在不必要的情况下生成过长的思维链,浪费了大量的计算资源。例如,对于简单的"2+3=?"这样的问题,某些长推理模型可能会消耗超过900个token来探索多种解题策略。尽管这种思维链策略对于复杂问题的解答非常有帮助,但在应对简单问题时,反复验证已有的答案和进行过于宽泛的探索显然是一种计算资源的浪费。
这两种现象都凸显了一个关键问题,如何在保证答案质量的同时,提高模型的思考效率?换句话说,我们希望模型能够在尽可能短的输出中获取正确的答案。而在本最佳实践中,我们将在使用MATH-500数据集上衡量DeepSeek-R1-Distill-Qwen-7B等模型的思考效率,从模型推理token数、首次正确token数、剩余反思token数、token效率、子思维链数量和准确率六个维度来评估模型的表现。
1
模型思考效率评估指标
在获取模型的推理结果后,我们便可以着手评估其思考效率。在开始之前,我们需要介绍评估过程中涉及的几个关键指标:token效率、模型思考长度以及子思维链数量。
1)模型推理token数(Reasoning Tokens)
这是指模型在推理过程中生成的长思维链的token数量。对于O1/R1类型的推理模型,该指标表示</think>标志前的token数量。
2)首次正确token数(First Correct Tokens)
模型推理过程中,从起始位置到第一个可以识别为正确答案位置的token数。
3)剩余反思token数(Reflection Tokens)
从第一个正确答案位置到推理结束的token数。
4)子思维链数量(Num Thought)
这一指标表示模型在推理过程中生成的不同思维路径的数量。具体来说,是通过统计模型生成的标志词(如alternatively、but wait、let me reconsider等)的出现次数来计算的。这反映了模型在推理中切换思路的频率。
5)token效率(Token Efficiency)
指的是首次正确token数与模型推理token总数的比值,其计算公式如下其计算公式如下:
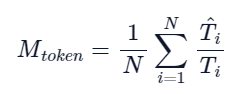

6)正确率(Accuracy)
正确得分,取值0到1之间
2
测试结果
使用相同的方法,对3个推理模型(deepseek-r1-671b-910B,DeepSeek-R1-671b-H20,QwQ-32b-H20)以及社区评测的6个模型DeepSeek-R1-Distill-Qwen-7B,QwQ-32B、QwQ-32B-Preview、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B,Qwen2.5-Math-7B-Instruct(将模型输出的所有token视为思考过程),以便观察不同类型模型的表现。具体结果整理如下:
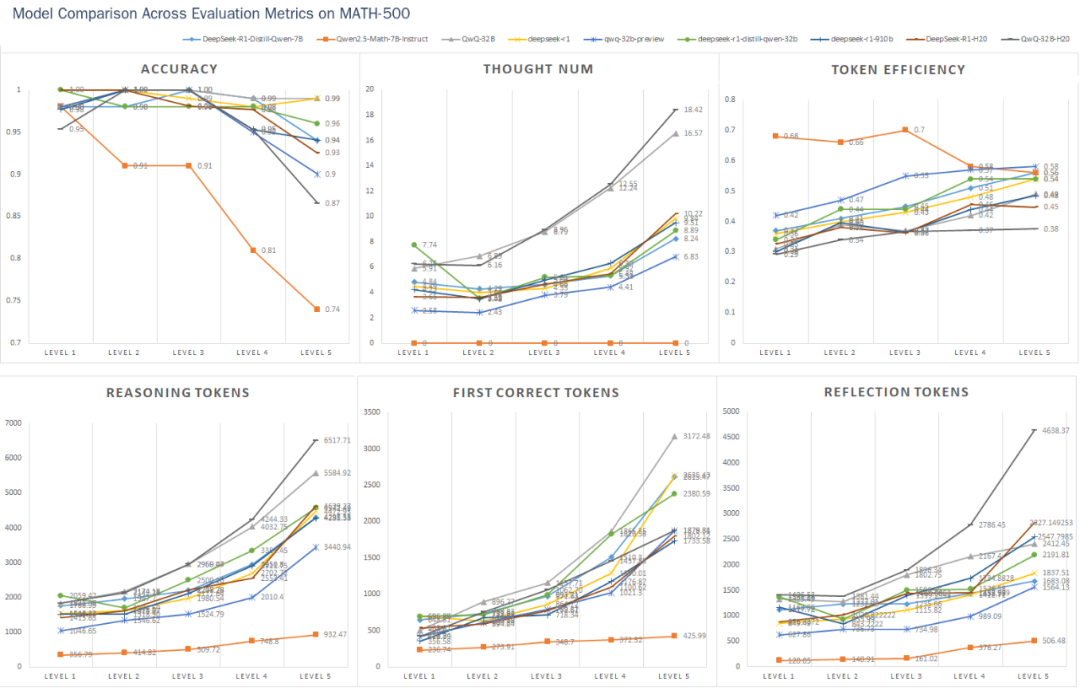
各模型准确度得分:
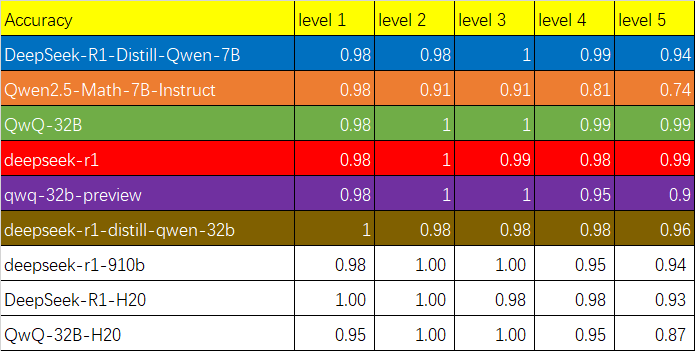
通过分析这些折线图,我们可以得出一些有趣的结论:
1)问题难度与模型表现
随着问题难度的增加,大多数模型的正确率呈现下降趋势,但QwQ-32B和DeepSeek-R1表现出色,在高难度问题上仍保持很高的准确率,其中QwQ-32B在最高难度级别上取得了最佳表现。同时,所有模型的输出长度都随问题难度增加而增加,这表明模型在解答更复杂问题时需要更长的"思考时间",与Inference-Time Scaling现象相符。
2)O1/R1类推理模型的表现
对于O1/R1推理模型,随着问题难度的提升,虽然输出长度稳定变长,但token的效率也有所提高(DeepSeek-R1从36%增长到54%,QwQ-32B从31%增长到49%)。这表明推理类型的模型,在更复杂的问题上其token的消耗会更加“物有所值”。而在相对简单的问题中,可能更多的存在不必须的token浪费,即使在简单问题上也可能不必要的对答案进行反复验证。其中QwQ-32B输出的token数量相较其他模型更多,这使得该模型在Level 5这种高难度问题上也能保持较高正确率,但另一方面也说明该模型可能存在过度分析的问题。
3)子思维数量
在难度Level 4及以下的问题中,DeepSeek系列的三个模型在子思维链数量上的变化相对稳定。然而,在最具挑战性的Level 5难度下,子思维链的数量会突然大幅增加。这可能是因为对于所测试的这些模型来说,Level 5的问题带来了极大的挑战,需要经过多轮尝试和思考才能找到解决方案。相比之下,QwQ-32B和QwQ-32B-Preview在思维链数量的增长上表现得更加均匀。这个现象可能反映了它们在处理复杂问题时的不同策略和能力。
4)非推理模型的表现
在处理高难度数学问题时,非推理模型Qwen2.5-Math-7B-Instruct的准确率显著下降。此外,由于缺乏深入的思考过程,该模型的输出数量仅为推理模型的三分之一。从图中不难看出,像Qwen2.5-Math-7B-Instruct这样的专门训练的数学模型在普通问题上的解题速率和资源消耗方面优于通用推理模型,但随着问题难度的提升,由于深入思考过程的缺乏所导致的模型性能下降的现象会更加明显,即存在明显的"天花板"效应。
本文基于MATH-500数据集,对包括QwQ-32B、DeepSeek-R1在内的几个主流Reasoning模型进行了推理效率的评测,从"Token efficiency"和"Accuracy"的视角,我们得到几个值得探讨的结论:
-
模型的“深入思考”能力,与模型的性能表现有明显的相关关系,更高难度的问题,需要“更深入”的思考过程
-
对于Reasoning效率评测,本文基于“overthinking”和“underthinking”的相关工作,探讨如何定义可量化的评测指标,以及在EvalScope框架上的工程实现
-
模型Reasoning效率的评测,对GRPO和SFT训练过程有非常重要的参考意义,有助于开发出"更高效"且能根据问题难度"自适应推理"的模型
让每个智能设备都拥有数学家般的严谨思维,工程师般的系统思考——这正是萤石云在AI浪潮中坚守的技术信仰。
本文评测数据引用自《R1类模型推理能力评测最佳实践》,技术实现依托萤石云弹性推理服务架构,模型思考效率评测最佳实践 | EvalScope。

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









