









 文章讲述了CPU架构的发展历程,从早期的SMP架构及其局限,到解决性能问题的NUMA架构,特别是介绍了NUMA架构的工作原理和Linux内核对其的支持,强调了在编程时利用NUMA特性以优化性能的重要性。
文章讲述了CPU架构的发展历程,从早期的SMP架构及其局限,到解决性能问题的NUMA架构,特别是介绍了NUMA架构的工作原理和Linux内核对其的支持,强调了在编程时利用NUMA特性以优化性能的重要性。
CPU是计算机的核心部件,被设计用来完成计算机的核心计算任务。
为了提升CPU的计算能力,CPU的技术发展大体经历了增加晶体管的数量、提高CPU的主频、增加核心数量、增加CPU个数(CPU互联)等多个阶段。
01 早期SMP架构的局限
早期,计算机系统是这样设计的,所有的CPU都是通过一条总线来访问内存,这种架构叫做SMP架构(Symmetric Multi-Processor),即对称多处理器结构。
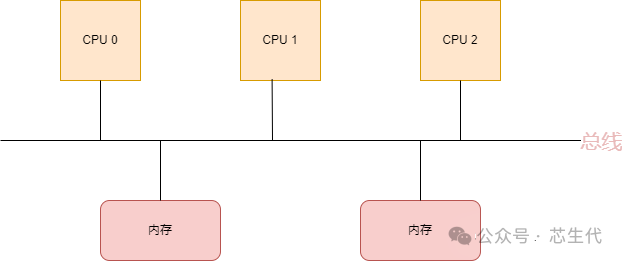
SMP架构有4个特点:
-
CPU和CPU以及CPU和内存都是通过一条总线连接起来
-
CPU都是平等的,没有主从关系
-
所有的硬件资源都是共享的,即每个CPU都能访问到任何内存、外设等
-
内存是统一结构和统一寻址的(UMA, Uniform Memory Architecture)
SMP架构在CPU核心不多的情况下,问题不明显。有实验证明,SMP架构服务器CPU利用率最好的情况是2~4个CPU。
随着CPU多核心技术的发展,一颗物理CPU中集成了越来越多的core(比如ARM架构服务器CPU基本是64核起步),当多个核心(Core)都是通过一条总线进行访问内存时,就会产生“争抢”情况,这种“争抢”会导致内存访问的延迟增加,从而导致系统的整体性能下降。
也就是说,SMP架构会随着CPU个数增加、单颗CPU的核心数增加,导致性能瓶颈越来越明显。
02 NUMA架构技术原理
为了解决SMP架构下不断增多的CPU Core导致的性能问题,NUMA架构应运而生。
NUMA架构:Non-Uniform Memory Access,即非一致性内存访问,是一种关于多个CPU如何访问内存的架构模型。
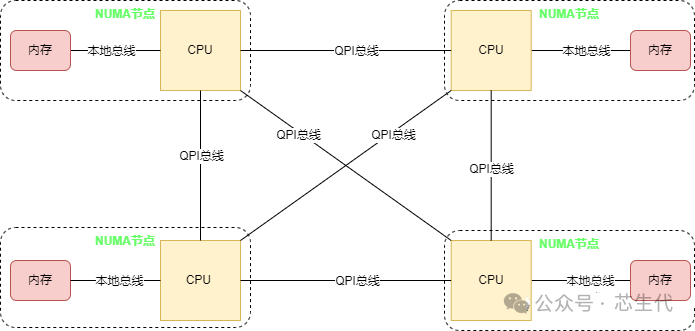
在NUMA架构中,将CPU划分到多个NUMA Node中,每个Node有自己独立的内存空间和PCIE总线系统。各个CPU间通过QPI总线进行互通。
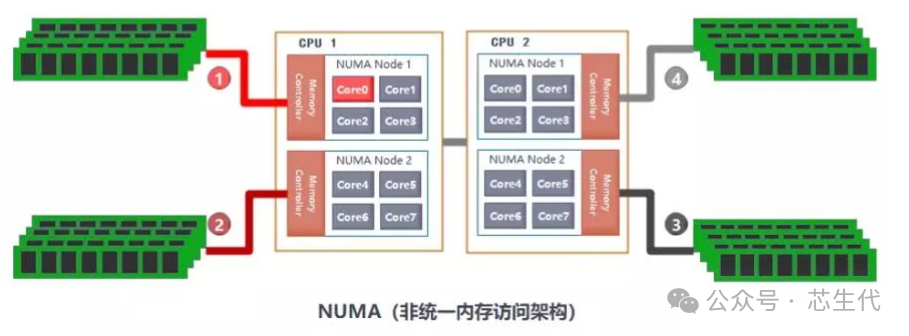
内存在物理上内存在物理上是分布式的,不同的核访问不同内存的时间不同。具体如上图所示:①的延迟为10~60ns(纳秒);②的延时高于①;③的延时高于②;④的延时略高于③。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访,问速度越慢,所以叫做非一致性内存访问,这个访问内存的距离称作Node Distance。
NUMA 架构的作用主要包括:
-
性能优化:通过允许每个处理器快速访问本地内存,NUMA 可以显著提高内存访问速度,减少等待时间,从而提高系统的整体性能。
-
可扩展性:支持系统的水平扩展。随着处理器和内存的增加,系统可以通过添加更多的节点来扩展,而不需要对现有的硬件或软件架构进行重大改动。
-
负载均衡:NUMA 系统可以通过操作系统和中间件的支持,实现内存访问的负载均衡,确保系统资源得到有效利用。
虽然NUMA很好的解决了SMP架构下CPU大量扩展带来的性能问题,但是其自身也存在着不足,当Node节点本地内存不足时,需要跨节点访问内存,节点间的访问速度慢,从而也会带来性能的下降。
所以,在编写应用程序时,要充分利用NUMA系统的这个特点,尽量的减少不同CPU模块之间的交互,避免远程访问资源,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
03 Linux内核对NUMA架构的支持
Linux内核对NUMA的支持:
-
2.5 版提供了基本的 NUMA 支持,在后续的内核版本中得到了进一步改进。
-
Linux 内核版本 3.8 带来了新的 NUMA 基础,允许在后续内核版本中开发更高效的 NUMA 策略。
-
Linux 内核 3.13 版本带来了许多旨在将进程置于其内存附近的策略,以及处理诸如在进程之间共享内存页或使用透明大页等情况;新的sysctl设置允许启用或禁用 NUMA 平衡,以及配置各种 NUMA 内存平衡参数。
-
在Linux系统中,针对NUMA架构的优化和调优主要涉及操作系统层面的内存管理和调度,以及应用程序层面的优化。
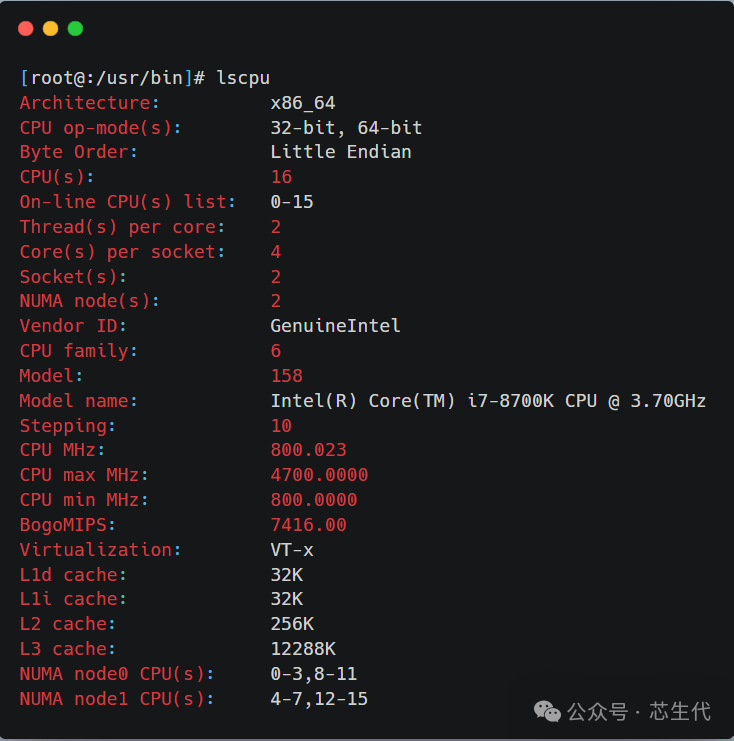
在Linux系统中,可以用lscpu查看NUMA和CPU的对应关系:
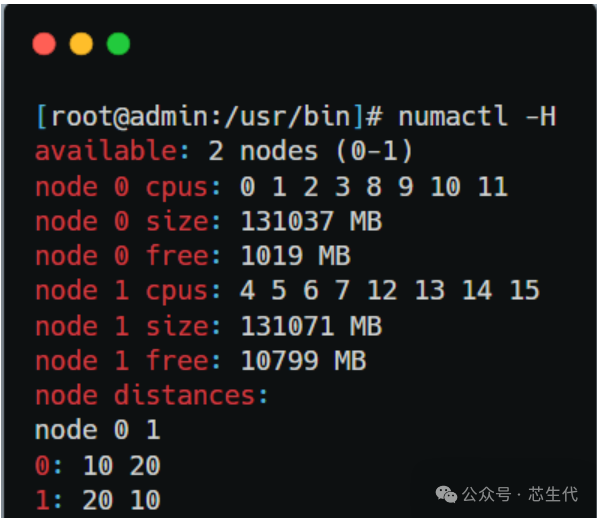
使用numactl -H命令可以看到NUMA架构下的内存分布:

















 5774
5774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









