









1. transformer与RNN

1)训练阶段不需要像RNN一样将序列数据依次放进模型,输入数据直接输入序列数据进行embedding。训练时由input生成attention(相当于生成中间语言义信息,key-value),由output根据input生成的中间语义及目标值序列加掩码输出预测结果。
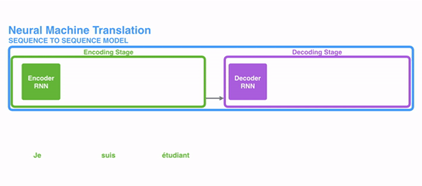 RNN->Attention
RNN->Attention 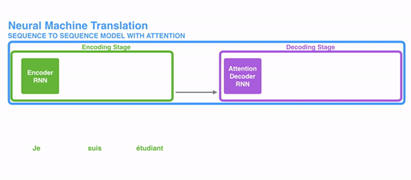
2) 解码阶段需要循环解码,由输入部分生成的语义及已经完成解码的部分持续 生成未解码部分。
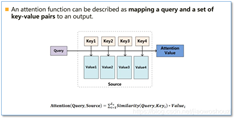
右边的解码部分相当于自动机wfst,左边attention给右边的输入相当于状态机上的输入,每次输入虽然相同但状态机已经到了不同的状态,有不同的输出。右边没有解码的部分输入值都是0,与前面已经解码的部分会形成一个鲜明的分割信息,再与由左边时序上生成的attention做点积可以有时序上与左边对齐的效果。transformer由于每次左边的attention都是一个完整的输入,而流式解码因为时效性要求,不能生成一个完整的时序输入,形不成transformer的attention。
2. embedding
1) embedding由输入数据embedding、位置信息embedding、段落信息embedding相加构成
2)输入数据embedding:
->[N,32,1]*[1,30000] 将词ID信息变换成one hot变示
->[N,32,1]*[1,30000]*[30000,768] 将30000个词信息映射成768维隐变量表示即完成embedding。后来albert又将768维压缩成了128维。
3)position embedding

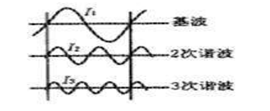
公式中i是位置信息,d是不同的隐维度。
i能表示的信息即:即便是同一个词在句子中不同的位置,对应到语义空间也会是不同的点。d主要是将这个不同的从多个维度展开,以在更高维的空间表示更丰富的位置信息。
4)段落embedding或token type embedding与position embedding类似都是为了给词序列附加更多的信息,更多的标注序列中的词在不同环境语义表达上的不同。
3.attention
1)multi-head attention •(head=12)

2)self attention
这里会由[1,32,768] 生成三个[1,32,12,64]维度的attention,称为Q、K、V。self attention中这三个attention生成的方法是一样的(但是[1,32,768]矩阵乘weight加bias,但不同的weight,bias初值会使QKV呈现不同的结果)。

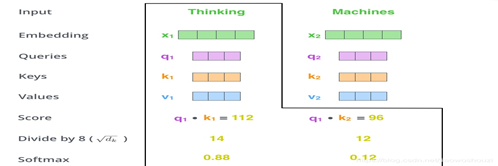
a.将Q每个位置64位隐变量依次与K中32个位置上的隐变量点积 : [1,12,32,64] * [1,12,64,32] ->[1,12,32,32]
b.将点击结果进行缩放再softmax,得到Q中每个位置与K中每个位置相关性 : Softmax( Sacle( [1,12,32,32] )) ->[1,12,32,32] probabilities
c.将value按位置相关性进行加权: [1,12,32,32]*[1.12,32,64] ->[1,12,32,64] ->[1,32,12,64]
d.将加权结果过感知机再与输入数据embedding相加,再过归一化得到[1,32,768]维度之attention:
[1,32,12,64] * [12,64,768] +[1,32,768] ->[1,32,768]
Attention = Normal(input_embedding+ w*[1,32,768]+b)
4.Position-wise Feed-Forward Networks
按attention is all your need论文讲,ffn相当于做了两次核大小为1的卷积。
在开源实现上是先将attention输出的[1,32,768]数据先过一个3072神经元的全连接,过激活层activitiion( [1,32,768]*[768,3072]+[1,32,3072] ) ->[1,32,3072]。再过一个768神经元的全连接[1,32,3072]*[3072,768] ->[1,32,768],结果即是每一层输出之hidden state。

5.参考文献















 4479
4479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









