







目录
一:朴素贝叶斯简介
朴素贝叶斯法是基于贝叶斯定理与特征条件独立性假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入输出的联合概率分布(朴素贝叶斯法这种通过学习得到模型的机制,显然属于生成模型);然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。
1.1基于贝叶斯决策理论的分类方法
首先对于朴素贝叶斯来说,其优点在于在数据较少的情况想依旧有效,并且可以处理多类别问题,缺点在于对于输入数据的准备方式较为敏感。
朴素贝叶斯的思想可以通过下图的示例来了解,我们现在用p1(x,y)表示数据点(x,y)属于类别1的概率,即下图中的圆点,p2(x,y)表示数据点(x,y)属于类别2的概率,即下图的三角形,那么我们就可以用下面的规则来判断它的类别:
如果p1(x,y)>p2(x,y),那么类别为1
如果p2(x,y)>p1(x,y),那么类别为2
也是就是选择高概率对应的类别,这就是朴素贝叶斯的核心思想。

1.2条件概率
条件概率即为在已知B发生的条件下,求事件A发生的概率。我们之前也学过概率论,所以这里直接给出计算公式。条件概率的计算公式为:

另外一种有效的计算方法为贝叶斯准则,计算公式如下:
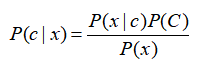
下面我们用条件概率来进行分类
按照前面提出的贝叶斯决策理论需要计算两个概率p1(x,y)和p2(x,y),这里只是简化描述,需要计算和比较的是P(C1|x,y)和P(C2|x,y).代表含义为给定某个有x,y表示的数据点,那么该数据点来着类别C1的概率和来着C2的概率。这里计算公式为
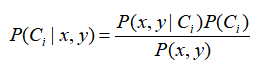
如果P(C1|x,y)>P(C2|x,y),那么类别为1;如果P(C2|x,y)>P(C1|x,y),那么类别为2
二:文档分类
2.1从文本构建词向量
在文档分类中,整个文档是实例,而电子邮件中某些元素构成特征。我们可以观察文档中出现的词,并把每个词的出现或者不出现作为一个特征,这样得到的特征数目就会跟词汇表中的词目一样多。朴素贝叶斯是用于文档分类的常用方法
def loadDataSet():
postingList = [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









