







问题:为什么要使用线程池
线程在使用过程中遇到的问题:
1、线程在Java中是一个对象,也是操作系统的重要资源,线程的创建、销毁需要时间,如果创建时间+销毁时间>执行 任务的时间那就很不合算了
2、Java对象占用堆内存,操作系统线程占用系统内存年,根据JVM规范,一个线程默认最大栈大小1M,这个栈空间是 需要从系统内存中分配的,线程过多,会消耗很多的内存
3、操作系统需要频繁的切换上下文,影响性能
为了方便的控制线程的数量,JDK引进了线程池,它具有以下好处:
- 降低资源消耗。通过复用已存在的线程和降低线程关闭的次数来尽可能降低系统性能损耗;
- 提升系统响应速度。通过复用线程,省去创建线程的过程,因此整体上提升了系统的响应速度;
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,因此,需要使用线程池来管理线程。
ThreadPoolExecutor
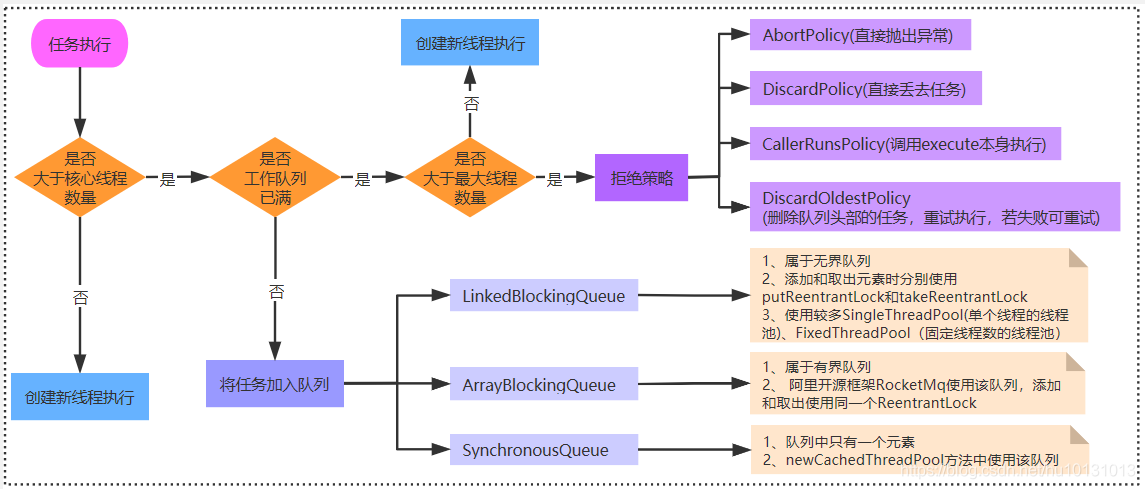
线程池执行逻辑
1、首先判断你是否达到核心线程数
1.1 如果没有达到,创建一个新的线程执行任务2、如果已经达到核心线程数,进而判断工作队列是否已满
2.1 如果没满,那将新的任务放入工作队列中3、如果工作队列已满,再判断是否已经达到最大线程数
3.1 如果没有达到,创建一个新的线程执行任务
4、如果已经达到了最大线程数,再执行拒绝策略
队列共有三种
1.直接切换。一个工作队列的一个很好的默认选择是一个SynchronousQueue ,将任务交给线程,无需另外控制。 在这里,如果没有线程可以立即运行,那么尝试排队任务会失败,因此将构建一个新的线程。 处理可能具有内部依赖关系的请求集时,此策略可避免锁定。 直接切换通常需要无限制的maximumPoolSizes,以避免拒绝新提交的任务。 这反过来允许无限线程增长的可能性,当命令继续以平均速度比他们可以处理的速度更快地到达时。
2.无界队列。使用无界队列(例如LinkedBlockingQueue没有预定容量)会导致新的任务,在队列中等待,当所有corePoolSize线程都很忙。 因此,不会再创建corePoolSize线程。 (因此,最大值大小的值没有任何影响。)每个任务完全独立于其他任务时,这可能是适当的,因此任务不会影响其他执行; 例如,在网页服务器中。 虽然这种排队风格可以有助于平滑瞬态突发的请求,但是当命令继续达到的平均速度比可以处理的速度更快时,它承认无界工作队列增长的可能性。
3.有边界的队列。有限队列(例如, ArrayBlockingQueue )有助于在使用有限maxPoolSizes时防止资源耗尽,但可能更难调整和控制。 队列大小和最大池大小可能彼此交易:使用大队列和小型池可以最大限度地减少CPU使用率,OS资源和上下文切换开销,但可能导致人为的低吞吐量。 如果任务频繁阻塞(例如,如果它们是I / O绑定),则系统可能能够安排比您允许的更多线程的时间。 使用小型队列通常需要较大的池大小,这样可以使CPU繁忙,但可能会遇到不可接受的调度开销,这也降低了吞吐量。
拒绝策略可以自定义默认有4中策略可用:
1.在默认ThreadPoolExecutor.AbortPolicy ,处理程序会引发运行RejectedExecutionException后排斥反应。
2.在ThreadPoolExecutor.CallerRunsPolicy中,调用execute本身的线程运行任务。 这提供了一个简单的反馈控制机制,将降低新任务提交的速度。
3.在ThreadPoolExecutor.DiscardPolicy中 ,简单地删除无法执行的任务。
4.在ThreadPoolExecutor.DiscardOldestPolicy中 ,如果执行程序没有关闭,则工作队列头部的任务被删除,然后重试执行(可能会再次失败,导致重复)。
可以定义和使用其他类型的RejectedExecutionHandler类。 这样做需要特别注意,特别是当策略被设计为仅在特定容量或排队策略下工作时。
//预期:每次查看是否已经超过核心线程数,没有超过的话就创建线程,超过的话,就判断工作队列是否已满,不满的话直接添加到队列,如果已满,则执行决绝策略
private static void testThreadPoolExecutor() throws Exception {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 5,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), (a, b) -> System.out.println("自定义"));//自定义拒绝策略
// TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.DiscardOldestPolicy());//删除队列头部的任务,重试执行(可能再次失败,导致重复)
// TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.DiscardPolicy());//直接丢弃需要执行的任务
// TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.CallerRunsPolicy());//如果线程池没有关闭直接运行任务(性能不高)
// TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.AbortPolicy());//直接抛出异常
testCommon(executor);
}
private static void testCommon(ThreadPoolExecutor executor) throws Exception {
//提交15个执行时间为3s的任务
for (int i = 0; i < 15; i++) {
executor.submit(() -> {
try {
Thread.sleep(500L);
log.info("当前线程池线程数量:{}; 当前线程池等待的数量:{} ;核心线程数量:{};最大线程数量:{}", executor.getPoolSize(), executor.getQueue().size(), executor.getCorePoolSize(), executor.getMaximumPoolSize());
log.info("开始执行....");
Thread.sleep(5000L);
log.info("执行结束....");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
log.info("任务[{}]提交成功", i);
}
Thread.sleep(500L);
log.info("当前线程池线程数量:{}; 当前线程池等待的数量:{} ;核心线程数量:{};最大线程数量:{}", executor.getPoolSize(), executor.getQueue().size(), executor.getCorePoolSize(), executor.getMaximumPoolSize());
Thread.sleep(15000L);//所有的都执行结束
log.info("当前线程池线程数量:{}; 当前线程池等待的数量:{} ;核心线程数量:{};最大线程数量:{}", executor.getPoolSize(), executor.getQueue().size(), executor.getCorePoolSize(), executor.getMaximumPoolSize());
executor.shutdown();
}
ScheduledThreadPoolExecutor
-
schedule(Runable) - 延时执行,仅执行一次且没有返回值
//预期:初始延迟30毫秒执行,执行1次,如果获取返回值的话得到null
private static void testScheduledThreadPoolExecutor() {
ScheduledThreadPoolExecutor scheduledExecutor = new ScheduledThreadPoolExecutor(5);
scheduledExecutor.schedule(() -> log.info("任务被执行,当前时间:{}", System.currentTimeMillis()),
//延时30毫秒 单位:毫秒
30, TimeUnit.MILLISECONDS);
}
-
schedule(Callable) - 延时执行,仅执行一次且有返回值
//预期: 初始延期1秒执行,执行1次后结束,能获取到返回值
private static void testScheduledThreadPoolExecutorCallBack() throws ExecutionException, InterruptedException {
ScheduledThreadPoolExecutor scheduledExecutor = new ScheduledThreadPoolExecutor(5);
ScheduledFuture<?> future = scheduledExecutor.schedule(() -> {
return UUID.randomUUID().toString();
// 延时1000毫秒 单位毫秒
}, 1000, TimeUnit.MILLISECONDS);
//获取返回值
Object o = future.get();
log.info("返回值为:{}", o);
}-
scheduleAtFixedRate() -周期性执行,有固定执行周期
若任务执行时长超过周期的话,后面的任务自动延时执行,不会并行执行
//预期: 开始任务延迟2秒执行,后过5秒 继续执行
private static void testScheduledThreadPoolExecutorCycle() {
ScheduledThreadPoolExecutor scheduledExecutor = new ScheduledThreadPoolExecutor(5);
scheduledExecutor.scheduleAtFixedRate(() -> {
System.out.println();
log.info("周期执行开始,当前时间:{},当前线程:{}", System.currentTimeMillis(), Thread.currentThread().getName());
try {
Thread.sleep(3000);//模拟任务执行周期是3秒
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("周期执行结束,当前时间:{},当前线程:{}", System.currentTimeMillis(), Thread.currentThread().getName());
// 初始延时2秒 固定周期1秒
}, 2000, 1000, TimeUnit.MILLISECONDS);
log.info("任务提交时间为:{} ,当前线程池中的线程数量为:{}", System.currentTimeMillis(), scheduledExecutor.getCorePoolSize());
}-
scheduleWithFixedDelay() -周期性执行,在当前任务执行结束固定时间后继续执行
//预期: 开始任务延迟2秒执行,任务执行了5秒,然后等待3秒周继续执行,依次类推
private static void testScheduledThreadPoolExecutorCycle1() {
ScheduledThreadPoolExecutor scheduledExecutor = new ScheduledThreadPoolExecutor(5);
scheduledExecutor.scheduleWithFixedDelay(() -> {
log.info("周期执行开始,当前时间:{},当前线程:{}", System.currentTimeMillis(), Thread.currentThread().getName());
try {
Thread.sleep(5000);//模拟任务执行周期是5秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println();
log.info("周期执行结束,当前时间:{},当前线程:{}", System.currentTimeMillis(), Thread.currentThread().getName());
// 初始延迟2秒 周期3秒
}, 2000, 3000, TimeUnit.MILLISECONDS);
log.info("任务提交时间为:{} ,当前线程池中的线程数量为:{}", System.currentTimeMillis(), scheduledExecutor.getCorePoolSize());
}

















 2860
2860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









