







 本文深入探讨了三种聚类算法:K均值聚类,介绍了其原理、步骤、参数选择及评价标准;接着讨论了基于密度的DBSCAN算法,包括其工作原理和参数选择;最后提到了层次聚类的特点和优势。通过对各种算法的比较,有助于理解聚类方法的不同应用场景。
本文深入探讨了三种聚类算法:K均值聚类,介绍了其原理、步骤、参数选择及评价标准;接着讨论了基于密度的DBSCAN算法,包括其工作原理和参数选择;最后提到了层次聚类的特点和优势。通过对各种算法的比较,有助于理解聚类方法的不同应用场景。
一、K均值聚类
1、原理:K-meas算法以k为参数,把n个对象分为k个簇,使得簇内相似度较高,簇间相似度较低
2、步骤:
1.随机选取k个点作为初始聚类的中心
2.对于剩下的点,根据其与聚类中的距离,将其归入最近的簇
3.对每个簇,计算所有点的均值作为新的聚类中心。
4.重复2.3步骤,直至聚类中心不再改变。
3、关于参数的选择:
- k值的选择:
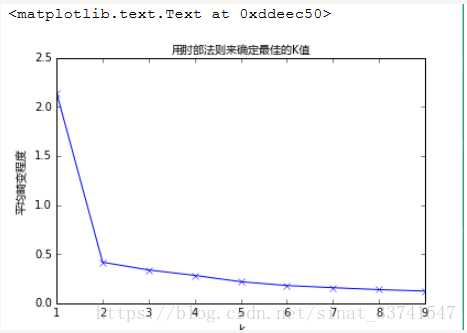
肘部法则:
一般情况下,我们可以选取K=2,3,...,10进行多次试验,并以K值为X轴,以损失函数(样本与质点的平方误差:)作为Y轴进行画图。理论上,随着K值的增大,损失函数会减小,选取图中的拐点(图中绿色的点)对应的K值为合适的K值,这意味着继续增大K值的效果已经不明显了。如下图:
轮廓系数:
对于一个聚类任务,我们希望得到的簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标。样本i的轮廓系数计算方法如下:
- 计算样本 i 到同簇内其他样本的平均距离
,该值越小,说明样本 i 越应该被聚类到该簇中,可以将
- 簇 C 中所有样本的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









