







MapReduce核心思想及其运行原理
1、MapReduce概述
MapReduce是Hadoop中面向大数据并行处理的计算模型、框架和平台。MapReduce用于海量数据的并行计算,它采用“分而治之”的思想,把大规模数据集的操作分发到多个机器去共同完成,然后对各个节点的中间结果进行整合后得到最终的结果。
2、MapReduce的核心思想
当启动一个MapReduce任务时,作业会将输入的数据集切分成若干独立的数据块,由Map端将数据映射成需要的键值对类型,然后对Map的输出进行排序,再把结果输入Reduce端;Reduce端接收Map端传过来的键值对类型的数据,根据不同键分组,对每一组键相同的数据进行处理,得到新的键值对并输出,这就是MapReduce的核心思想。
3、MapReduce编程模型
MapReduce是一种编程模型,它由Map和Reduce两个阶段组成。Map表示“映射”,由一定数量的Map Task组成;Reduce表示“归约”,由一定数量的Reduce Task组成。
3.1、MapReduce运行过程
在Map阶段,用户自定义的map()函数接收<key,value>对作为输入,执行map()函数逻辑,产生新的<key,value>对并写入本地磁盘,MapReduce框架会对这些中间结果进行排序,并将key相同的数据放在一起形成新的列表,同意交给reduce()函数处理。
在Reduce阶段,reduce()函数接收key及对应的value列表作为输入,将key值相同的value值合并后,产生新的<key,value>对输入到HDFS上。
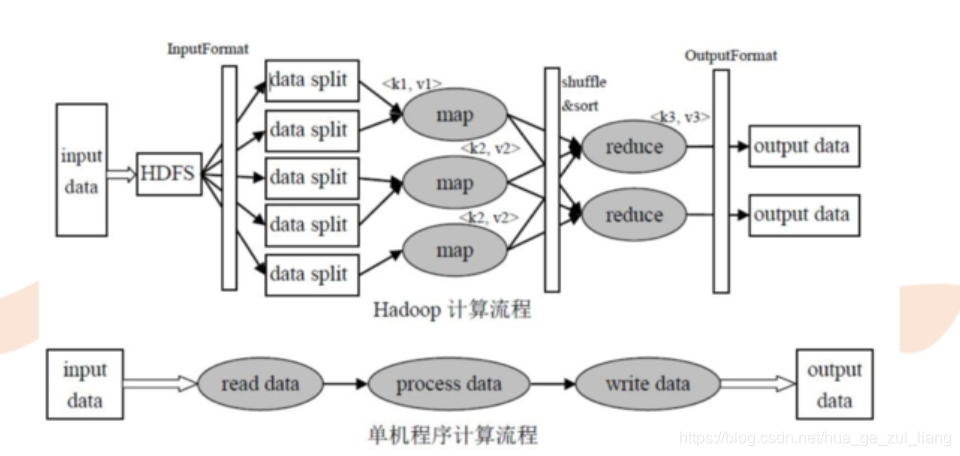
3.2、MapReduce编程三部曲
(1)输入Input。MapReduce输入一系列k1/v1对。
(2)Map和Reduce阶段。Map:(k1,v1)->list(k2,v2),Reduce:(k2,list(v2))->list(k3,v3)。其中k2/v2是中间结果对。
(3)输出Output。MapReduce输出一系列k3/v3对。
4、MapReduce词频统计
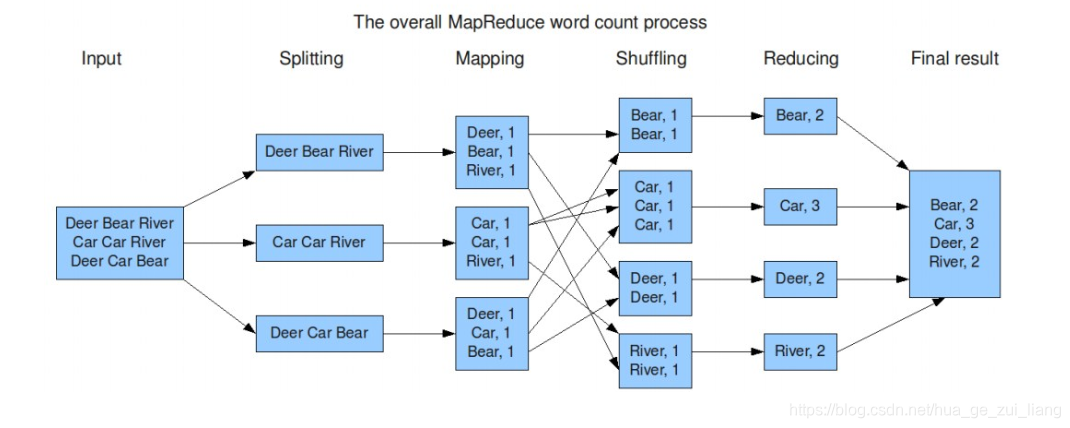
ps:以上便是MapReduce的基本介绍。
ps:望多多支持,后续更新中。















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









