







原文地址http://blog.csdn.net/collaboom/article/details/52227950
在下在做数据分析时,原始数据是excel格式的,导入Hive表时将其转化为txt格式。
excel文件转txt格式的步骤如下:
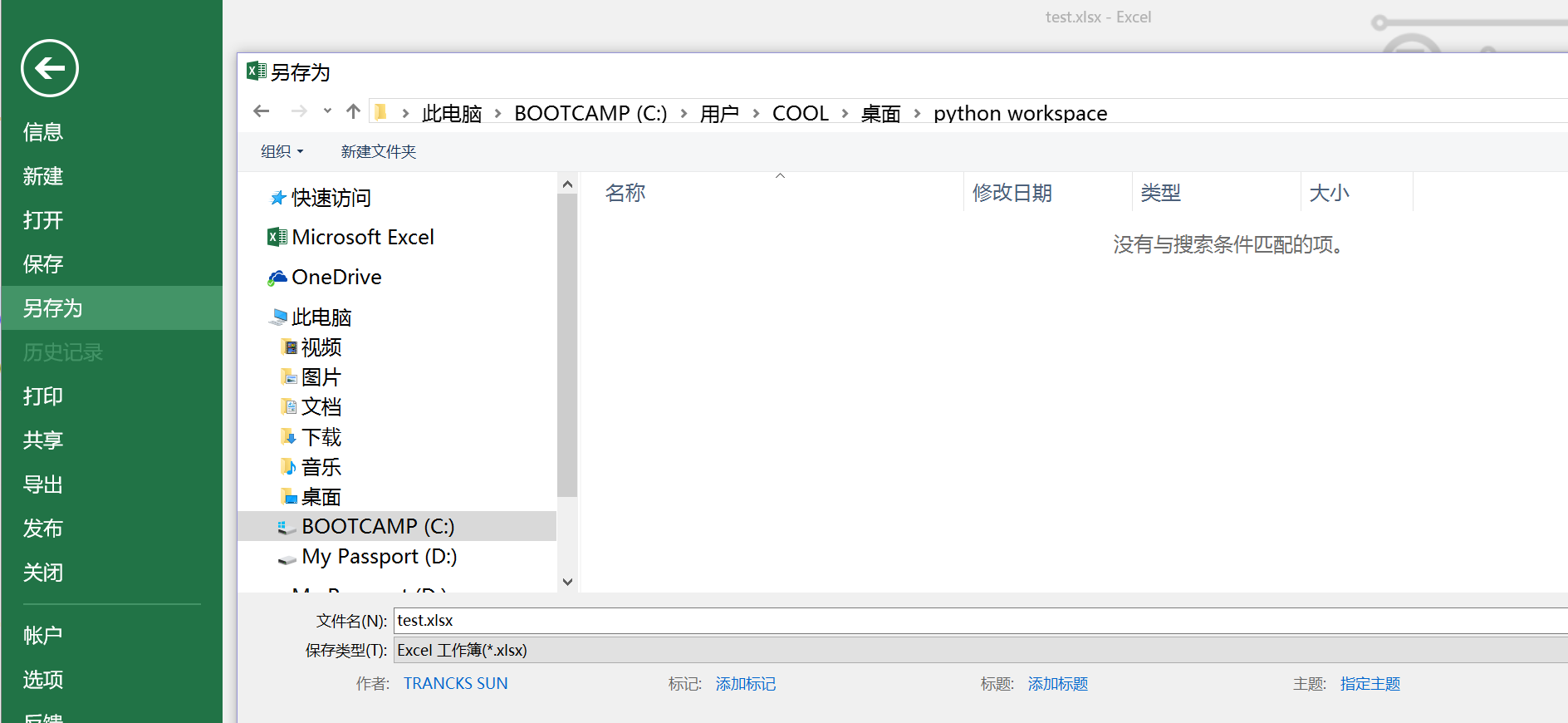
1.打开另存为
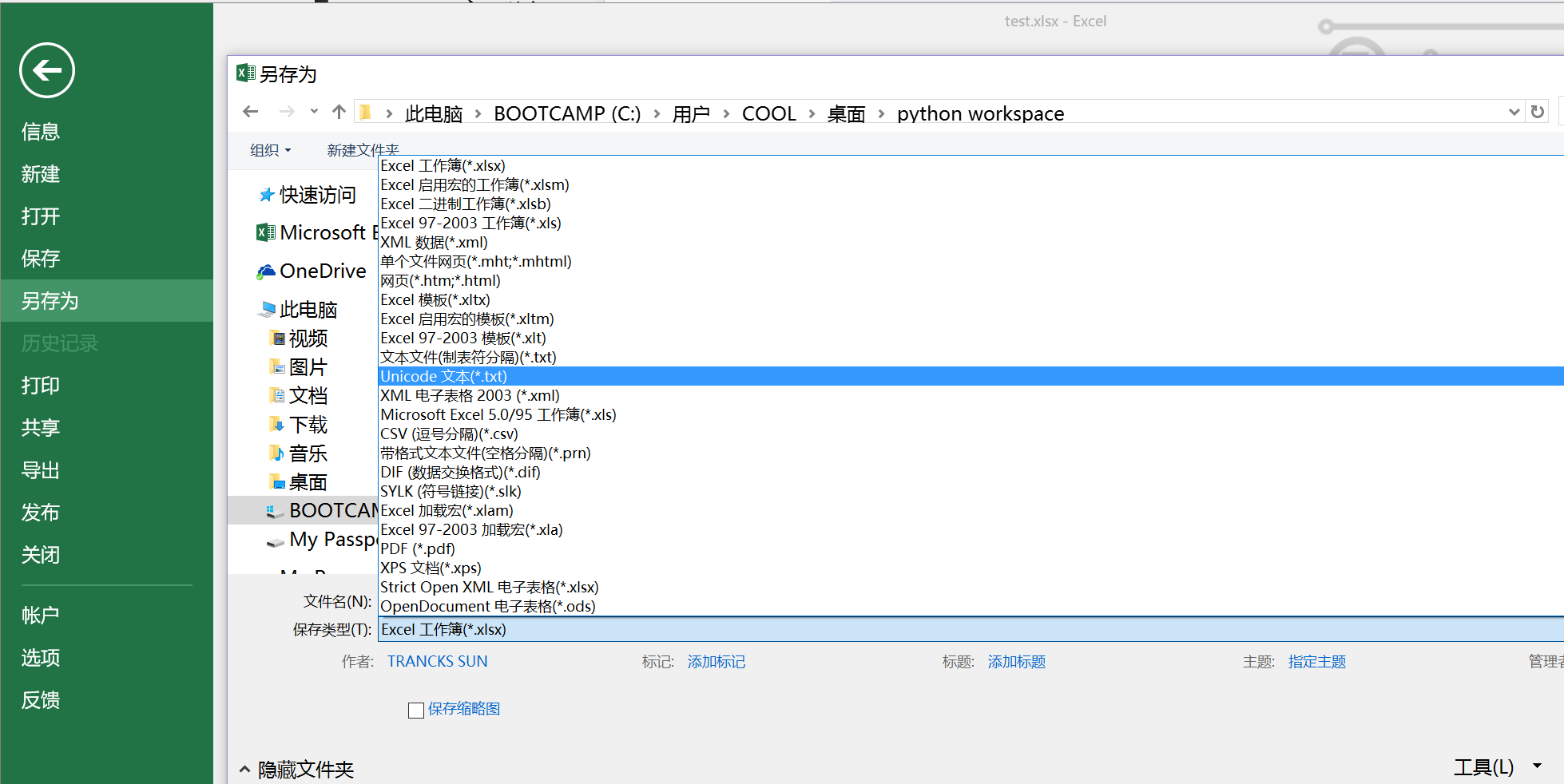
2.选择txt格式保存
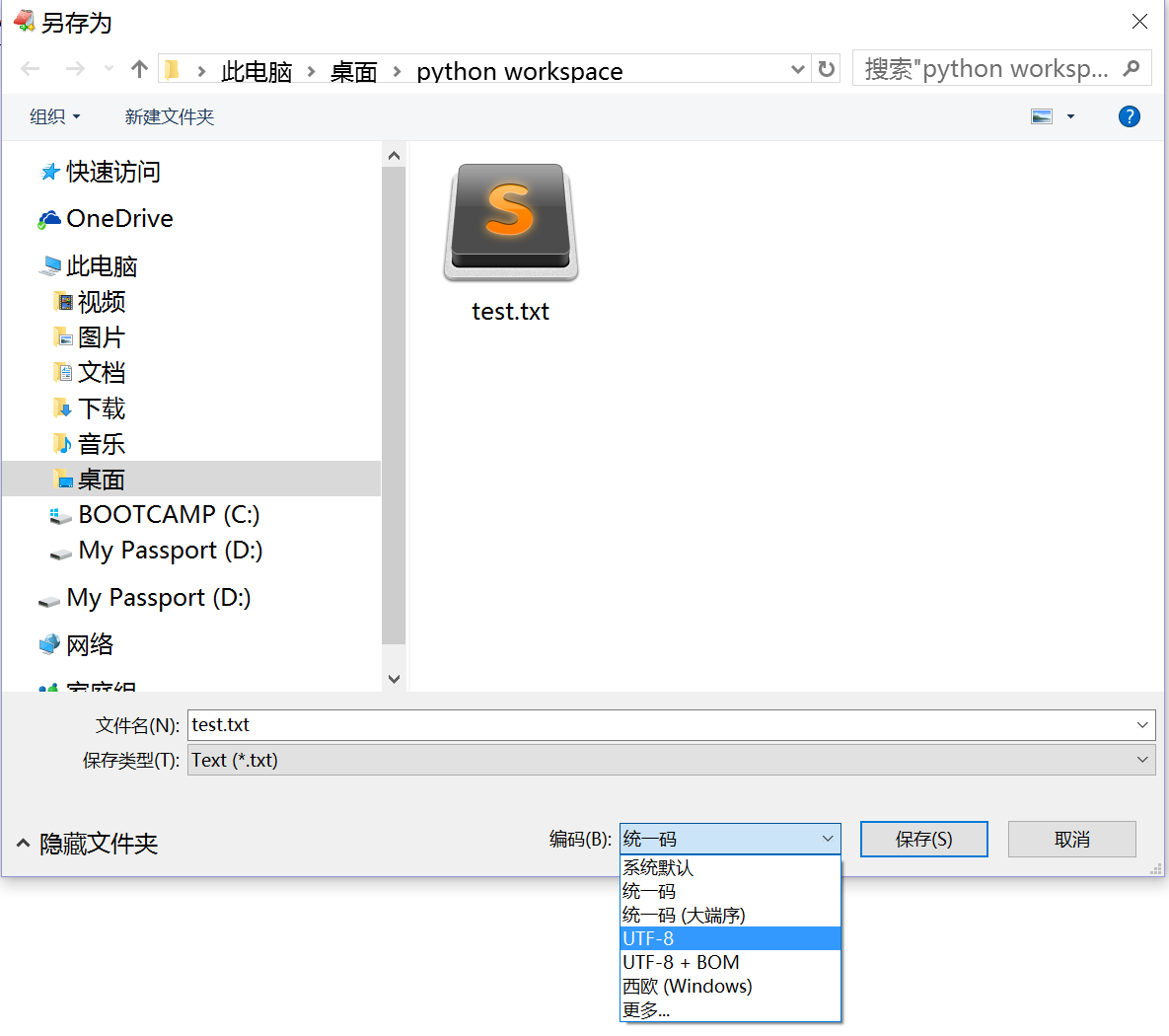
3.打开转成的txt将编码修改为UTF-8
在往hive表中导入数据时常常以换行符‘\n’来分割条数据。然而有时因为数据格式不够标准,即excel单元格中存在着换行符情况。例子如下:
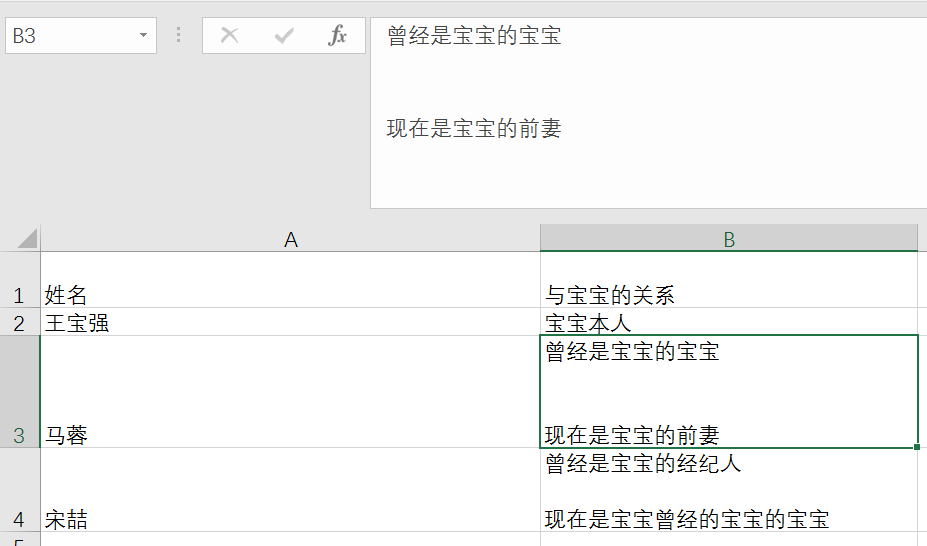
在这个表格中,B3,B4单元格都存在这换行符。如果将其导入到hive中,查询得到的结果将是这样:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
与我们预先想得到的不一样
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
因此尝试使用Python编写脚本来处理问题。开始尝试使用正则表达式进行处理。后面找到了更简便的办法,使用xlrd包对excel文件进行处理。使用pip install xlrd可以安装该包。
下面的代码读取每一个单元格并将其中内容转化为字符串格式(默认为float格式,因此原本的整数可以转化为int去除小数点在转化为字符串),去除字符串中的换行符,将数据直接存储到txt文件中,编码格式为utf-8。
废话不说上代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
总结:该代码可以实现将excel表格标准化并转化为UTF-8的txt文件,方便导入数据库。

















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









