







 本文介绍如何通过修改Spark的log4j.properties配置文件来减少启动spark-shell时的日志输出,提高命令行界面的清晰度。
本文介绍如何通过修改Spark的log4j.properties配置文件来减少启动spark-shell时的日志输出,提高命令行界面的清晰度。
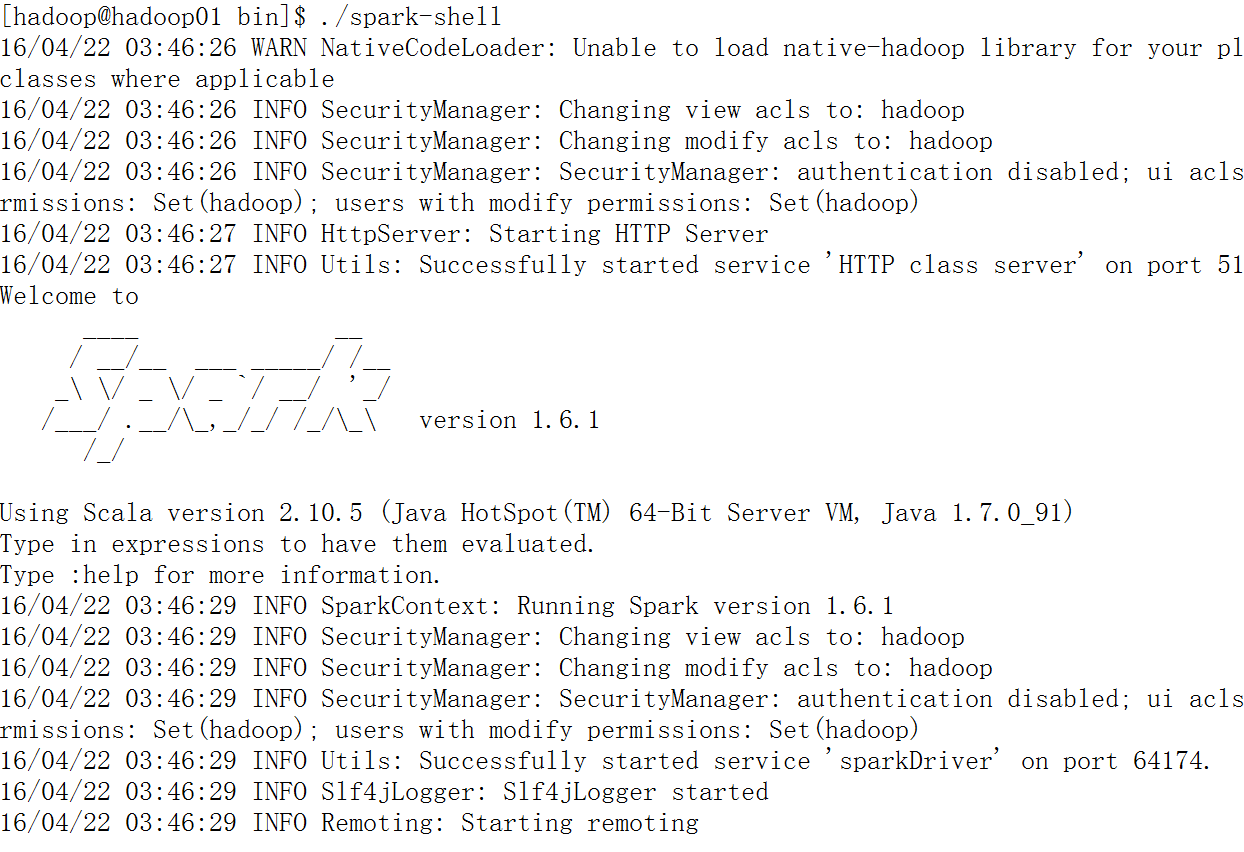
当我们执行spark-shell的时候,会出现如下界面,如果觉得显示信息过多可通过修改conf文件夹下的log4j.properties文件让其只显示警告信息,而不显示所有的信息1。
解决方案
进入到spark目录/conf文件夹下,此时有一个log4j.properties.template文件,我们执行如下命令将其拷贝一份为log4j.properties,并对log4j.properties文件进行修改。
cp log4j.properties.template log4j.properties
vim log4j.properties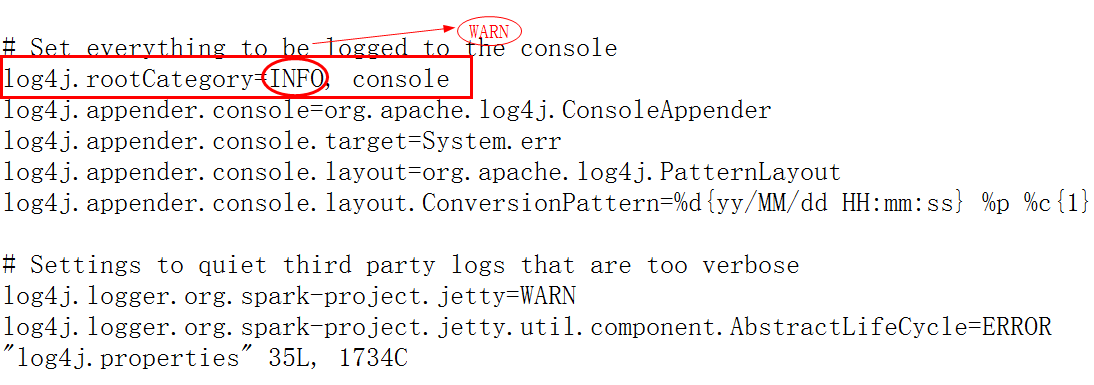
如上图所示,将log4j.rootCategory=INFO, console中的INFO改为WARN,保存退出即可。
效果如下所示:
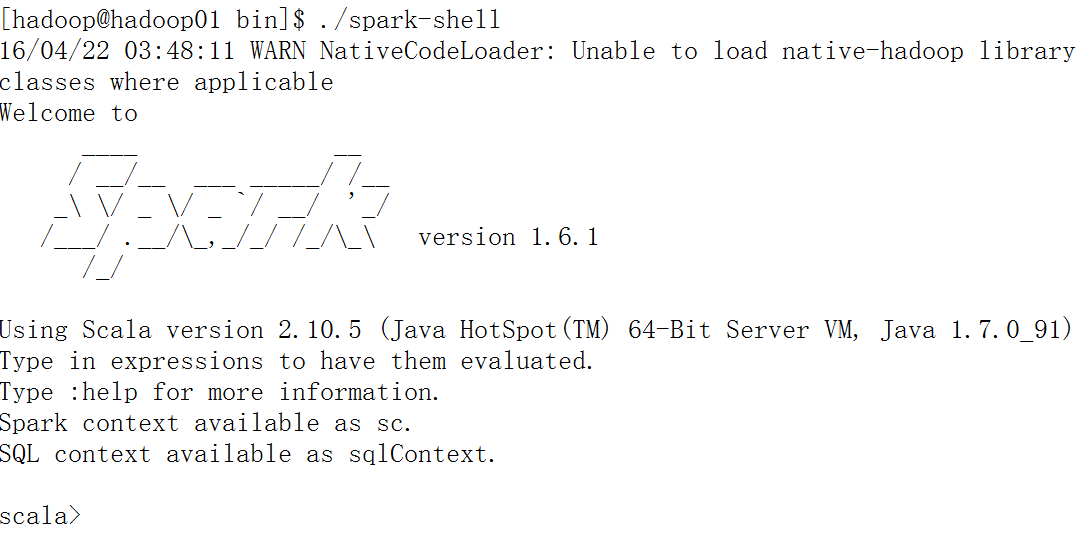
同样,该方法也适用于pyspark。
- Spark快速大数据分析,卡劳(Karau,H.) ↩

















 6758
6758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









